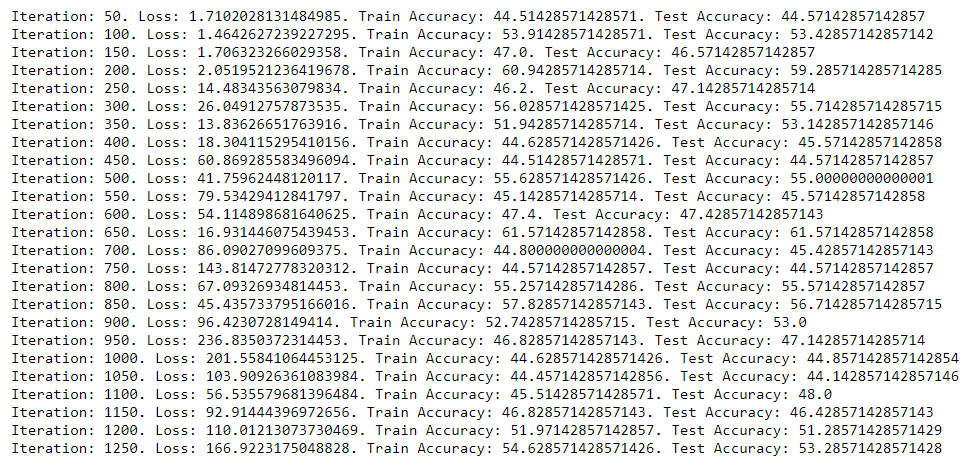
I’m trying to implement simulated annealing as a custom PyTorch optimizer to be used in a neural network training loop instead of a traditional gradient-based method. The code I currently have runs, but the loss just keeps growing rather than decreasing. I’ve tested on this dataset using a traditional gradient-based method and do achieve improving performance, rather than decreasing like it does here.
I think the issue may be with how I am updating the model parameters on each iteration. For simulated annealing I need to check the loss value for new randomly chosen parameters within some neighborhood of the current parameters. If the loss is lower, I update the model to the new parameters. If the loss is higher, with some probability I will still update the parameters (according to the simulated annealing algorithm).
Is the way I have done this correct? Basically I am updating the parameters with the new (random) ones, testing the loss, and if the loss is higher with the new points I put back the old parameters with some probability (using load_state_dict). If the loss is lower, I keep the new parameters. Any ideas why this is not working?
Below is the class I wrote for simulated annealing.
Here is a link to all the code in the notebook (full data pipeline) where I use this simulated annealing algorithm, in case that helps.
import torch
from torch.optim import Optimizer
import torch.nn as nn
import numpy as np
import math
class SimulatedAnnealing(Optimizer):
def __init__(self, params, startTemp = 1000
, coolRate = 0.001, neighborhoodSize = 0.05
, loss = nn.CrossEntropyLoss()
, model = None
, features = None
, labels = None): #these represent default values, but can be overridden
self.startTemp = startTemp
self.coolRate = coolRate
self.currTemp = startTemp
self.loss = loss
self.model = model
self.features = features
self.labels = labels
self.neighborhoodSize = neighborhoodSize
def step(self):
#need to first generate a random new point in the space
if torch.cuda.is_available():
oldOutputs = self.model(self.features.cuda())
oldPerformance = self.loss(oldOutputs, self.labels.type(torch.LongTensor).cuda())
else:
oldOutputs = self.model(self.features)
oldPerformance = self.loss(oldOutputs, self.labels.type(torch.LongTensor))
oldDict = self.model.state_dict()
for name, param in self.model.state_dict().items():
#generate a matrix of random changes in each param element to be added to each param matrix
if (len(param.shape) == 2):
random = torch.Tensor(np.random.uniform(low = self.neighborhoodSize * -1, high = self.neighborhoodSize
, size = (param.shape[0], param.shape[1])))
else:
random = torch.Tensor(np.random.uniform(low = self.neighborhoodSize * -1, high = self.neighborhoodSize
, size = param.shape[0]))
#now add random to the params to transform them
new_param = param + random.cuda()
self.model.state_dict()[name].copy_(new_param)
if torch.cuda.is_available():
newOutputs = self.model(self.features.cuda())
newWeights = self.model.state_dict().items()
newPerformance = self.loss(newOutputs, self.labels.type(torch.LongTensor).cuda())
else:
newOutputs = self.model(self.features)
newWeights = self.model.state_dict().items()
newPerformance = self.loss(newOutputs, self.labels.type(torch.LongTensor))
if (newPerformance < oldPerformance):
jumpProb = math.exp((newPerformance - oldPerformance) / self.currTemp) #computes the probability of accepting a worse point
if (np.random.uniform(0, 1) <= jumpProb): #determines whether we jump to worse point or stay with prior point
self.currTemp -= self.coolRate
else:
self.model.load_state_dict(oldDict) #put the old weights back in case where we don't jump'
self.currTemp -= self.coolRate
else:
self.currTemp -= self.coolRate

