While investigating another issue, I stumbled over some weird behaviour, where using a single Con2D layer for inference blows up my memory usage more than using a resnet50. This is the code that I’m using:
import os
from tqdm import tqdm
from torchvision.transforms import ToTensor
from torchvision.models import resnet50, resnet18
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
import torch
import torch.nn as nn
import cv2
n = 1000000
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
class RandomDs(Dataset):
def __init__(self, ):
pass
def __len__(self):
return n
def __getitem__(self, index):
return torch.rand(3, 256, 256)
if __name__ == '__main__':
dataset = RandomDs()
data_loader = DataLoader(dataset, batch_size=128, shuffle=False, num_workers=4, pin_memory=False)
model = resnet50()
# model = nn.Conv2d(3, 128, 3)
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
device = torch.device('cuda:0')
# model = nn.DataParallel(model)
model.to(device)
s = f"{count_parameters(model):.3e} trainable parameters"
print(s)
with torch.no_grad():
for batch in tqdm(data_loader):
batch = batch.to(device)
model(batch)
I ran this code with 4 configurations (model is either resnet50 or nn.Conv2d(3, 128, 3); and DataParallel is turned on or off (off means I just use a single GPU).
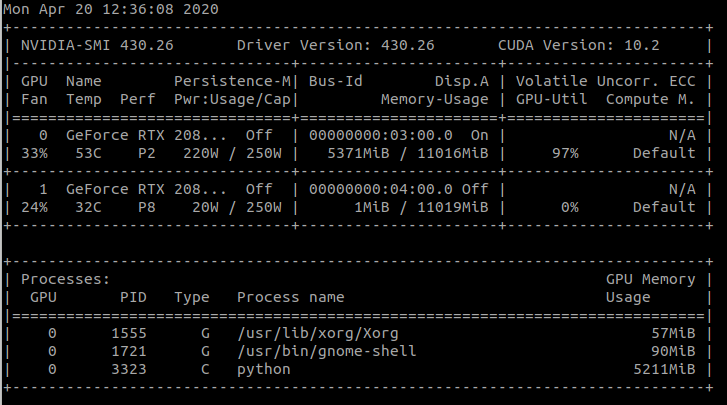
For Conv2D, single GPU I get
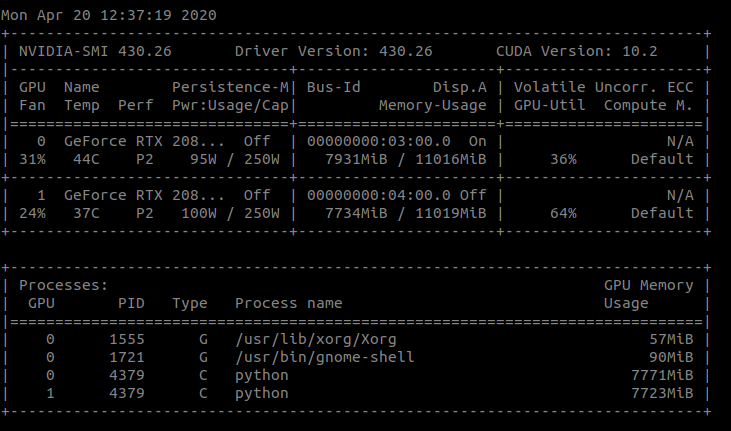
For Conv2D, DataParallel I get
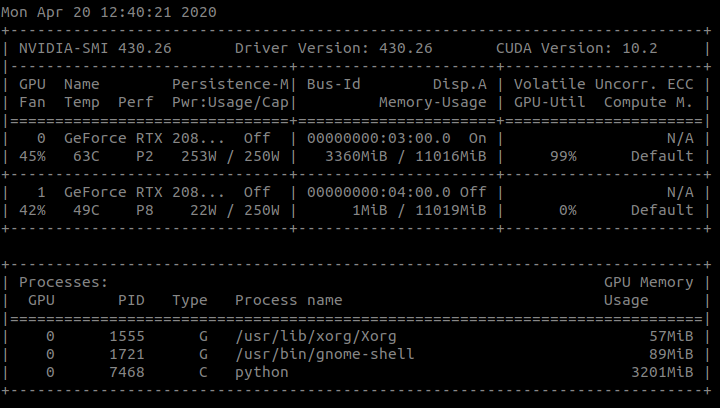
For resnet50, single GPU I get
For resnet50, DataParallel I get
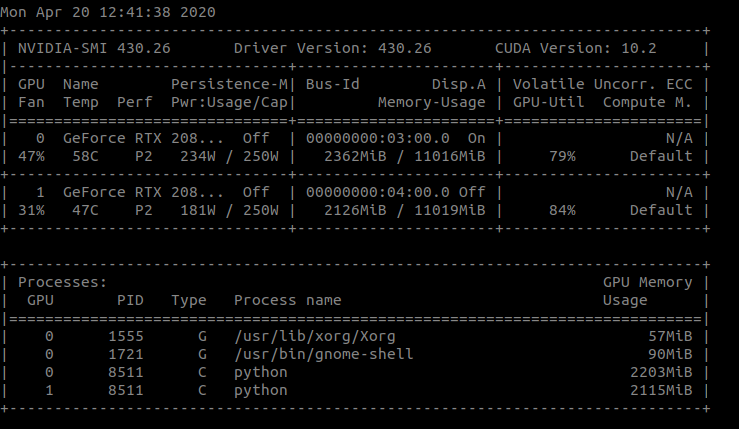
Why is that? Conv2D uses way more memory than resnet50 and memory increases for Conv2D if I use Dataparallel.
I am using Cuda 10.2 and pytorch 1.2.0
