im facing a runtime error when trying to implement cnn
this is the link of model :
https://github.com/Alymostafa/ml/blob/master/cnn_using_pytorch.ipynb
im facing a runtime error when trying to implement cnn
The error is raised by a linear layer.
Add a print statement before feeding the activation to the first linear layer and check its shape.
like that , sorry i am beginner in cnn:
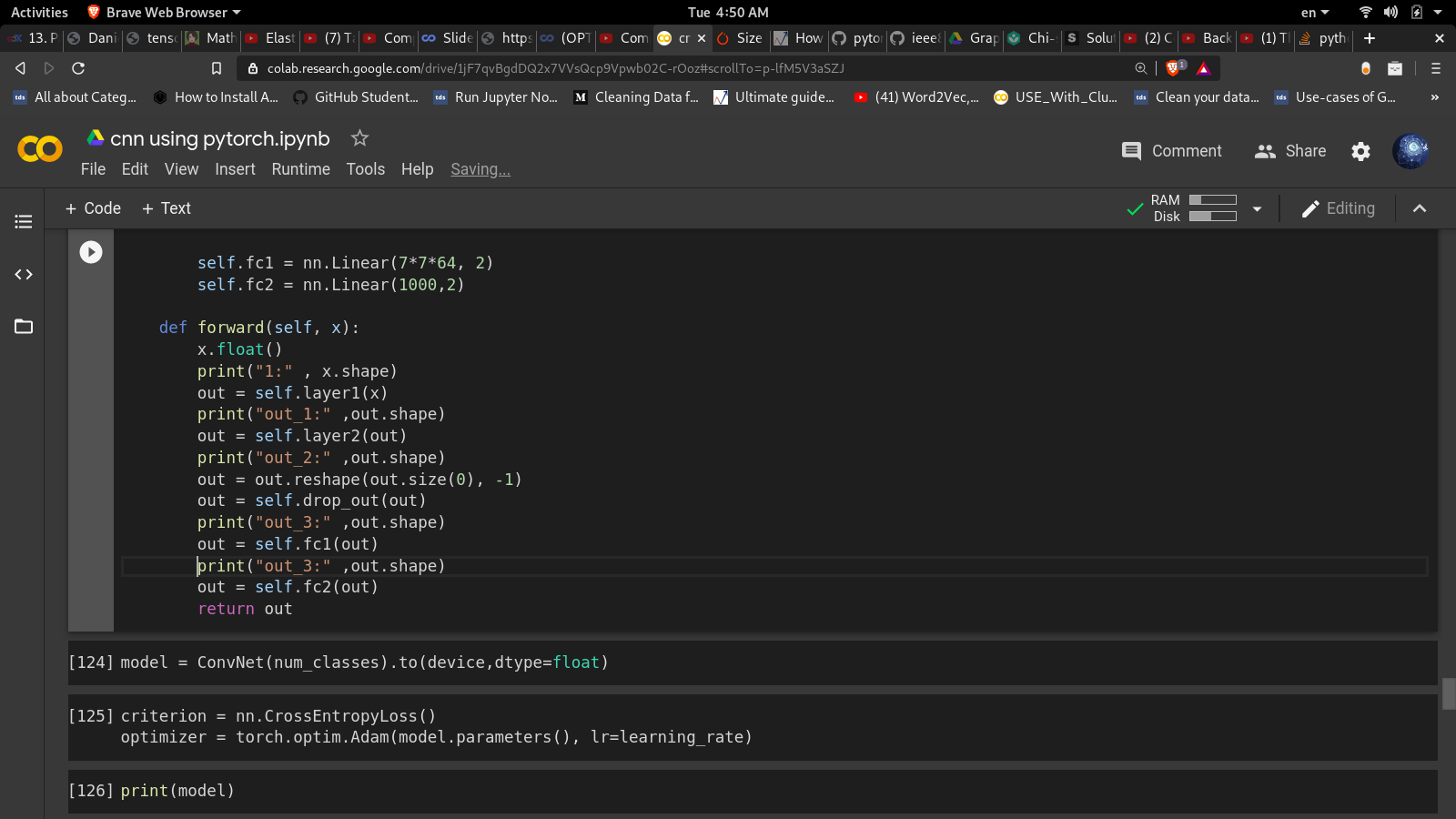
def forward(self, x):
x.float()
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.drop_out(out)
print(out.shape)
out = self.fc1(out)
out = self.fc2(out)
return out
Could you post the printed shape and compare it the the in_features in self.fc1?
Based on the print statements, you should set in_features=7168.
However, I’m not sure if your model is really doing what you intend to do.
nn.Conv2d expects an input tensor in the shape [batch_size, channels, height, width], while you are apparently passing the tensor as [batch_size, height, width, channels] and set the number of input channels to 224, which seems to be the height.
You could permute the input tensor via: x = x.permute(0, 3, 1, 2) and pass it in the expected shape.
PS: It’s also better to post by wrapping it in three backticks ```, as it makes debugging easier and enables the forum search. 
i want to take i photo with 224*224 pixel and the output is binary [1 or 0 ]
i face a problems in choosing the kernel size in cov2d and in maxpool2d
any advice ?
Permute the input, so that the channel dimension is in dim1 and set the in_channels to the number of input channels, not the height.
sorry but i dont understand , can you take a look in the github repo and tell me about values of conv2d and maxpool2d , sorry for that
The git repo is not functional. It is throwing an error. As @ptrblck mentioned the model expects an input of shape [batch_size, channels, height, width] as compared to [batch_size, height, width, channels], which is what you have given. To address this issue you would need to change the shapes of the input which can be done using torch’s permute method as shown below.
import torch
batch_size = 16
img_h,img_w = 64,64
num_channels = 3
img_1 = torch.randn(batch_size , img_h , img_w , num_channels) ### Of the form
img_1 = img_1.permute(0,3,1,2) ### Of the form [batch_size, channels, height, width]
In your case, you would need to permute x as soon as it comes into the forward method of the model.
Additionally, in your Conv2d declaration, the number of input channels is not the height. For instance, in the above example, the number of input channels is 3 and not 64. Therefore the Conv2d declaration would take an in_shape of 3.
def __init__(self, num_classes=2):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(3, 224, kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),
#nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=1, stride=0))
self.drop_out = nn.Dropout()
self.fc1 = nn.Linear(7168, 45)
self.fc2 = nn.Linear(45,2)
def forward(self, x):
x.float()
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.drop_out(out)
out = self.fc1(out)
out = self.fc2(out)
return out
where can i change the values that you say
my image size is 224*224
thanks in advance
def forward(self, x):
x.float()
x = x.permute(0,3,1,2)
....
Change nn.Conv2d in layer1 to nn.Conv2d(3,32,kernel_size = 5, stride = 1, padding = 2)
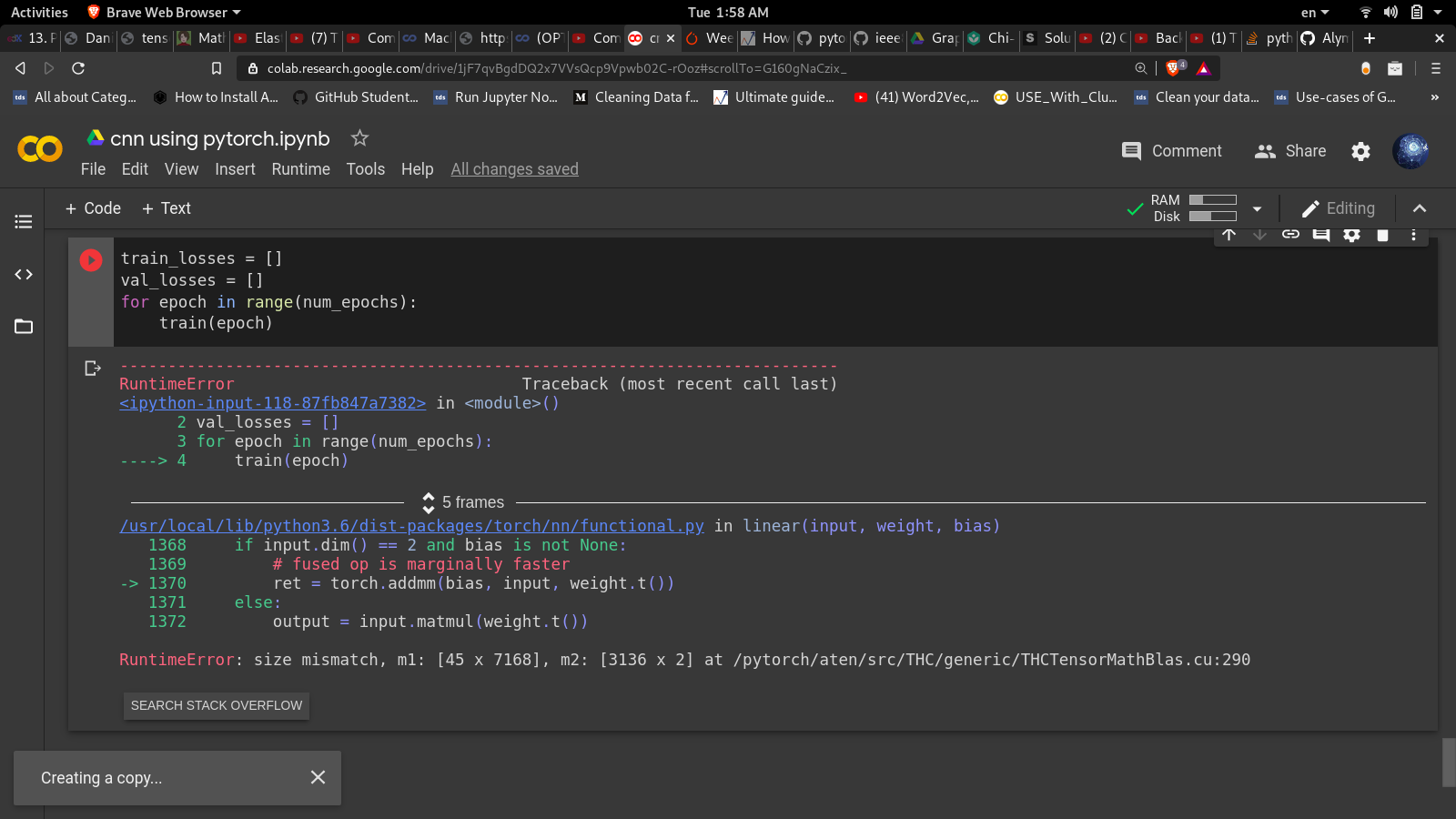
gives me this error :
<ipython-input-33-87fb847a7382> in <module>()
2 val_losses = []
3 for epoch in range(num_epochs):
----> 4 train(epoch)
5 frames
/usr/local/lib/python3.6/dist-packages/torch/nn/functional.py in linear(input, weight, bias)
1368 if input.dim() == 2 and bias is not None:
1369 # fused op is marginally faster
-> 1370 ret = torch.addmm(bias, input, weight.t())
1371 else:
1372 output = input.matmul(weight.t())
RuntimeError: size mismatch, m1: [45 x 802816], m2: [7168 x 45] at /pytorch/aten/src/THC/generic/THCTensorMathBlas.cu:290
The error is expected, given that your Linear layer takes in an input of 7168 and you are getting an input of 802816. Declare the Linear layer as self.fc1 = nn.Linear(802816, 45). However, this solution is not recommended as it places huge computational constraint in terms of the number of parameters. It is recommended to downsample the spatial dimension further before you use a fully connected layer.
how can i do that and not use huge computational
it gives me another error :
ValueError Traceback (most recent call last)
<ipython-input-39-87fb847a7382> in <module>()
2 val_losses = []
3 for epoch in range(num_epochs):
----> 4 train(epoch)
4 frames
/usr/local/lib/python3.6/dist-packages/torch/nn/functional.py in nll_loss(input, target, weight, size_average, ignore_index, reduce, reduction)
1834 if input.size(0) != target.size(0):
1835 raise ValueError('Expected input batch_size ({}) to match target batch_size ({}).'
-> 1836 .format(input.size(0), target.size(0)))
1837 if dim == 2:
1838 ret = torch._C._nn.nll_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
ValueError: Expected input batch_size (45) to match target batch_size (90).
There are 90 targets. There are only 45 inputs. This is an error in the way you are assigning targets.
I would suggest using Maxpool layers to downsample the input