While i’m trainning the WaveRNN, i found that the size of tensor has always different and there’s an error.
I had checked the source code and print the tensor in the background, i found that the tensor’s size had becoem strange after it pass self.upsample().Size shoud be torch.Size([8, 1, 132300]) but it is torch.Size([8, 1, 132300]). I don’t know how and why.(Here’s a photo, and it’s a notebook on colab:Google Colab)
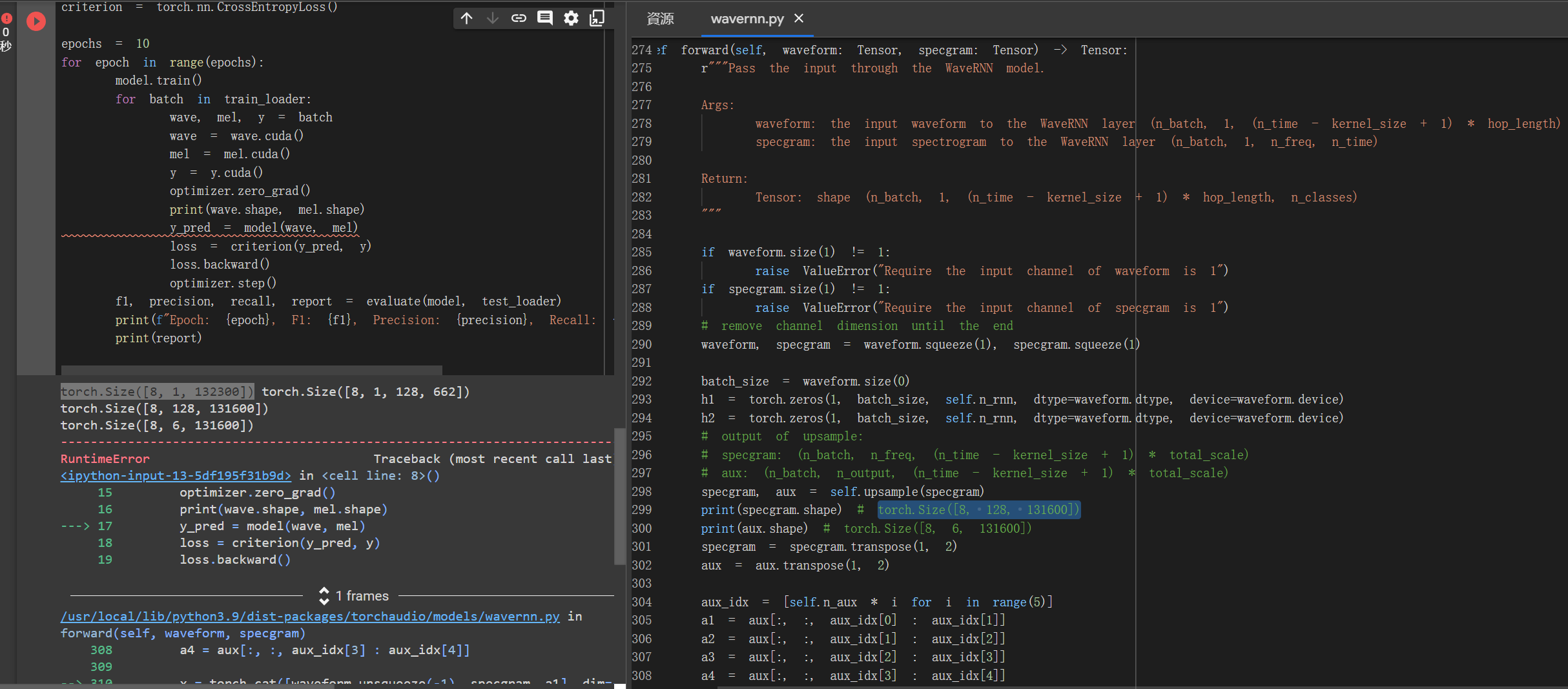
error msg:
RuntimeError: Sizes of tensors must match except in dimension 2. Expected size 132300 but got size 131600 for tensor number 1 in the list.
part of code:
data processing
import IPython.display as ipd
import numpy as np
from tqdm import tqdm
make all of the audio the same length(max len)
max_len = max([len(i[‘audio’]) for i in simple_data])
for i in simple_data:
i[‘audio’] = np.pad(i[‘audio’], (0, max_len - len(i[‘audio’])), ‘constant’)
turn the audio into mel spectrograms
preprose = transforms.MelSpectrogram(sample_rate=16000, n_fft=1024, win_length=1024, hop_length=256, n_mels=128, f_min=0.0, f_max=8000.0, power=2.0)
import torchaudio, os
waveforms =
mel_spectrograms =
labels =
save to wav
for i in simple_data:
torchaudio.save(f"audio.wav", torch.tensor(i[‘audio’]).float().unsqueeze(0), 16000)
waveform, sample_rate = torchaudio.load(f"audio.wav")
from torchaudio.transforms import MelSpectrogram
mel_spectrogram = MelSpectrogram(sample_rate)(waveform)
mel_spectrograms.append(mel_spectrogram)
waveforms.append(waveform)
labels.append(i[‘disease’])
# delete the wav file
os.remove(f"audio.wav")
features =
for i in tqdm(range(len(mel_spectrograms))):
features.append([waveforms[i] ,mel_spectrograms[i]])
train_x, test_x, train_y, test_y = train_test_split(features, labels, test_size=0.2, random_state=random_state)
train_audio = torch.stack([x[0] for x in train_x])
train_mel = torch.stack([x[1] for x in train_x])
train_dataset = torch.utils.data.TensorDataset(train_audio, train_mel, torch.tensor(train_y))
test_audio = torch.stack([x[0] for x in test_x])
test_mel = torch.stack([x[1] for x in test_x])
test_dataset = torch.utils.data.TensorDataset(test_audio, test_mel, torch.tensor(test_y))
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
model
model = models.WaveRNN(upsample_scales=[5, 5, 8], n_classes=data_classes , n_output = 6,hop_length=200, kernel_size = 5)
model = model.cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
criterion = torch.nn.CrossEntropyLoss()
epochs = 10
for epoch in range(epochs):
model.train()
for batch in train_loader:
wave, mel, y = batch
wave = wave.cuda()
mel = mel.cuda()
y = y.cuda()
optimizer.zero_grad()
print(wave.shape, mel.shape)
y_pred = model(wave, mel)
loss = criterion(y_pred, y)
loss.backward()
optimizer.step()
f1, precision, recall, report = evaluate(model, test_loader)
print(f"Epoch: {epoch}, F1: {f1}, Precision: {precision}, Recall: {recall}")
print(report)