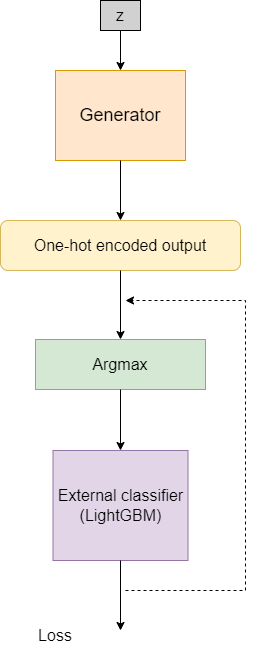
I am creating a GAN that can also utilize an auxiliary classifier from an external library for computing an additional loss that can be backpropagated to the GAN. The auxiliary classifier is a LightGBM model, which was chosen due to its computational efficiency. The input to LightGBM is typically a panda DataFrame, where each feature is represented in a single dimension.
Since the output of my generator is a one-hot encoded model, I have to first apply torch.argmax(cat_output) to make the output compatible for the LightGBM model. Problems arise when backpropagating the loss, as the argmax detaches the gradients from the output. Is there a way to skip the argmax when backpropagating the loss, as the argmax merely exists for making the output compatible for use in the alternative model, whereas the learning is required for the layers before it.