Hi!
My network has a large embedding layer [141713, 128]. The forward pass takes about 0.01s but the backward is taking almost 0.47s which is 47x of the forward operation.

Also, when I used torch.autograd.profiler.profile(use_cuda=True) then I saw a significant amount of time is taken by embedding_dense_backward on the CPU but the network is training on GPU. This could be the reason for the slow-down during backward.
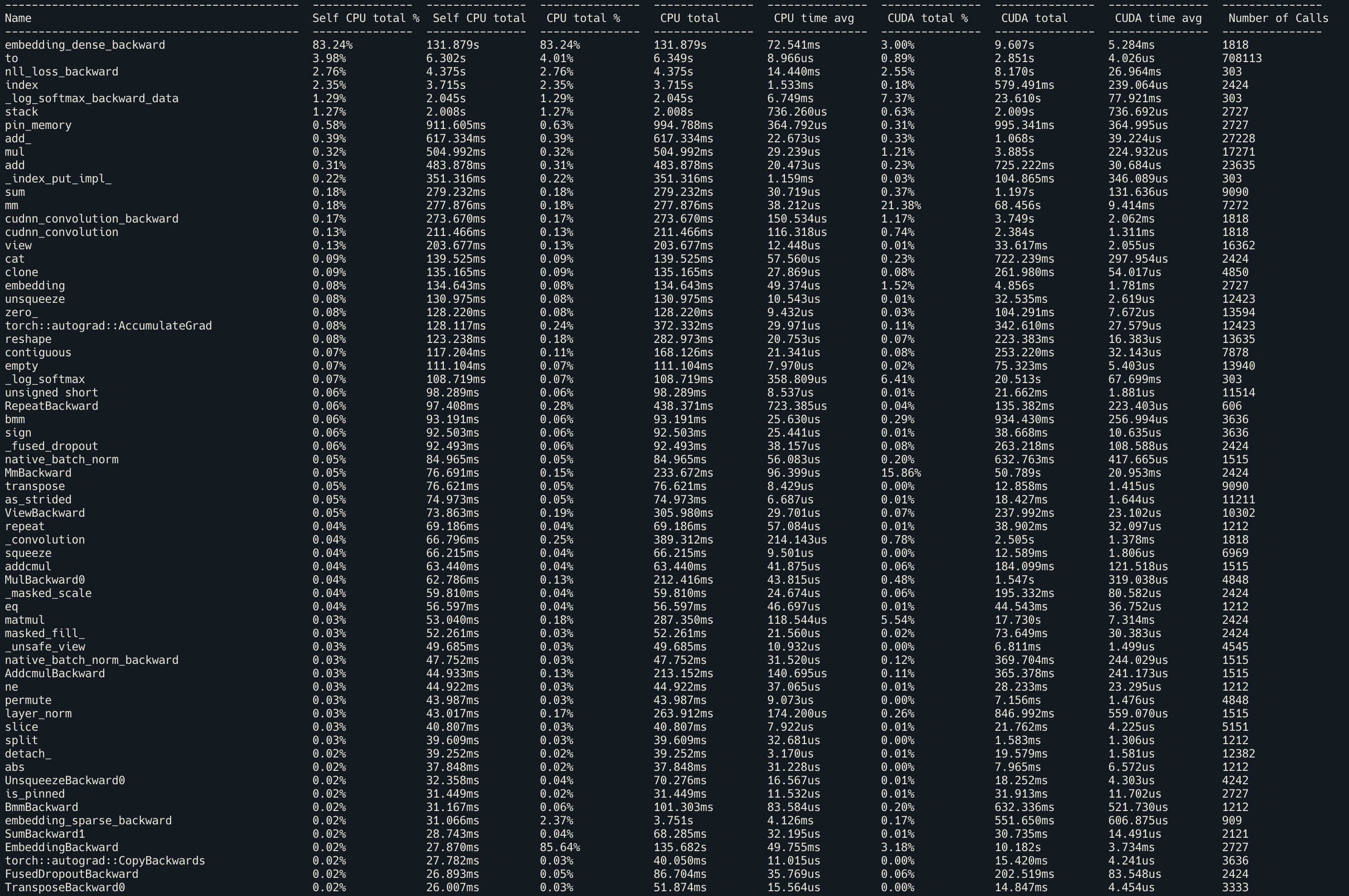
I also tried using sparse=True in the embedding layer, but that did not have any significant impact on the timing.
Could you please provide some insights into this and ways to overcome it?