I have relatively large network fully exported to torchscript.
I reimport the torchscript in python, and then I need to run the forward pass a number of times on a set of frames.
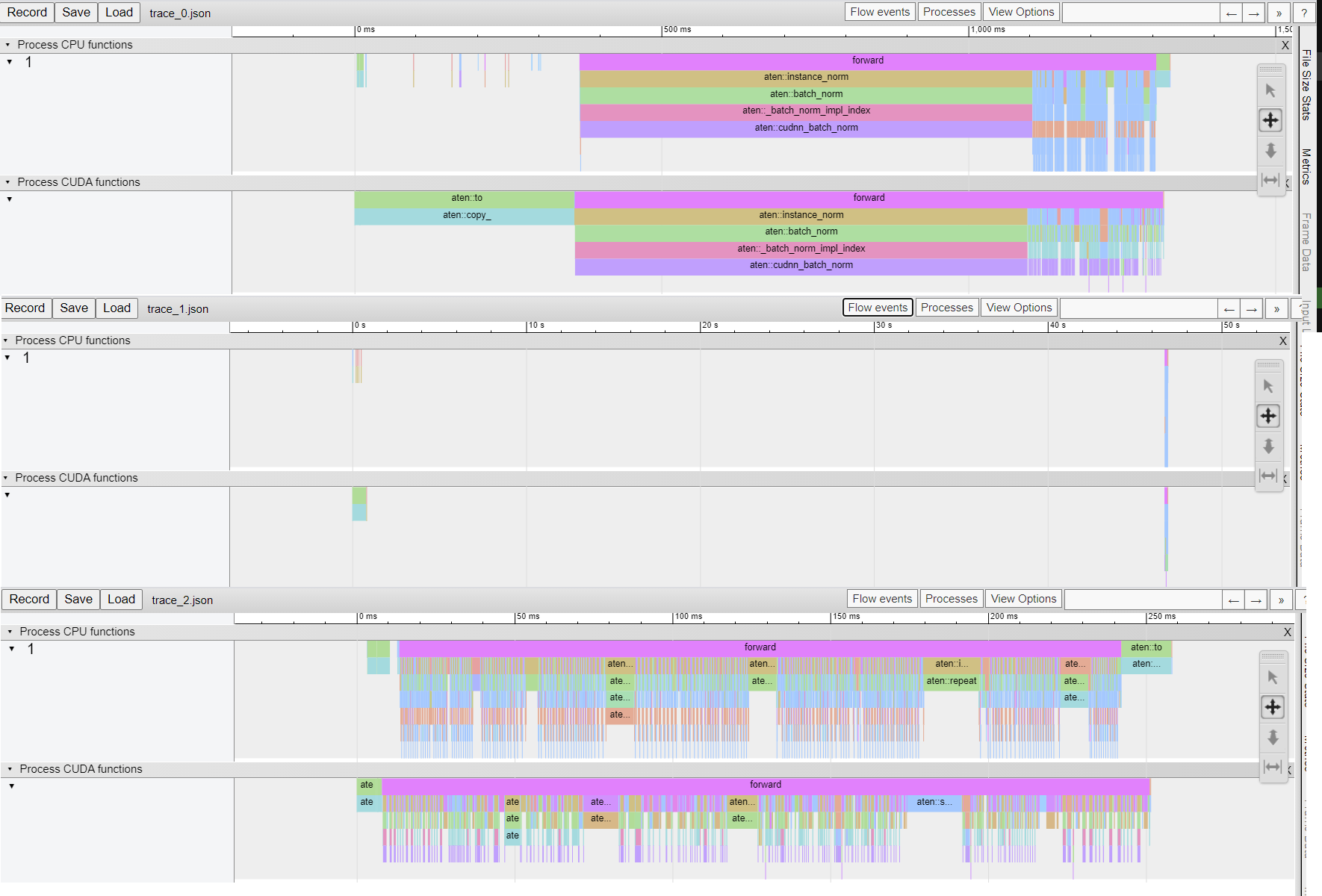
The weird thing is that while the first forward pass runs at an acceptable speed, the 2nd one (and only the second one, after the first pass has returned the results to CPU) seems to be tacking forever, more than 50 seconds.
I’ve even tried to call
torch.cuda.synchronize(device=self.device)
after the .to('cpu').
The rest of the frames are processed at reasonable speed, it’s really only the 2nd one what could it be doing in this 2nd pass?
Are you only seeing the slow 2nd iteration when using the scripted model and/or only the GPU?
Note that the JIT performs some optimizations, but 50s sounds rather excessive, so I doubt it’s the case here.
It is a traced model, and it only happens on GPU (on cpu things are even).
I’ve tried this on Pytorch 1.8.1 cuda 10, on both Windows 10 and Ubuntu 20.04 (the former on a Quadro P2000 Mobile with driver 466.11 and the latter has a Titan RTX on 450.102.04) and the results are similarly skewed (the 2nd frame takes 30 seconds on the Titan).
If it is of any assistance in understanding what is going on these are the profiles from the first 3 frames:
with torch.autograd.profiler.profile(use_cuda=True, with_stack=True) as prof:
inp = [torch.from_numpy(i).float().to(self.device) for i in inputs]
with torch.no_grad():
out = self.sess(*inp)
result = [o.detach().cpu().numpy() for o in out]
Btw is there any way to check that pytorch is loading the correct cuda libraries?
Is the slowdown only happening on scripted models or any GPU workload?
You could check the used CUDA version via torch.version.cuda and depending on the way you’ve installed it (binaries or source build) it can be either statically or dynamically linked.
Apologies, I didn’t catch that the point of your question initially. It is only on scripted models.
Just to check if I understand correctly now:
I have the training function of my model wrapped in some boilerplate code (partly pytorch-lightning, but it should be irrelevant). I have the option to trace this function and then use it for training, or to skip this step and train with all python host code.
My original question was based on what i observed at inference time (forward function has been exported and re-imported) but indeed even in training i observe a delay on the second iteration only when the forward function is traced, whereas with all python host code the times are even.
cuda = '10.2' in torch/version.py
It’s installed from anaconda, so it should be all statically linked i believe?
Someone opened an issue on gitlab, after encountering what i thought is a superset of this problem. He saw that with varying input sizes, the first 20 iterations would be slow. On the other hand with fixed input size, only the first 2 iterations would be slow (and the second one, unacceptably so, much like the reason for my question here).
link: The first 20 loops of inference are Extremely Slow on C++ libtorch v1.8.1 · Issue #56245 · pytorch/pytorch · GitHub
Now, the problem for me was that the latter solution did not fix the 2nd iteration. However as it turns out, setting the baliout_depth to 0 would solve just that.
I’m not sure if this is an acceptable/recommended solution, and/or if there’s a better fix to be coming in a future version of pytorch (as i see ticket 52286 is still open) however maybe you want to try this.
Thank you very much! It works for me without measurable performance penalty. It seems there is few document about bailout depth and it’s hard to find the solution for me without the help of you guys.
I would expect it to be an option that is not exactly supposed to be accessible by the user, as both _C module and function are coded as “private”. That’s why I wonder if it’s the right solution.
 what could it be doing in this 2nd pass?
what could it be doing in this 2nd pass?