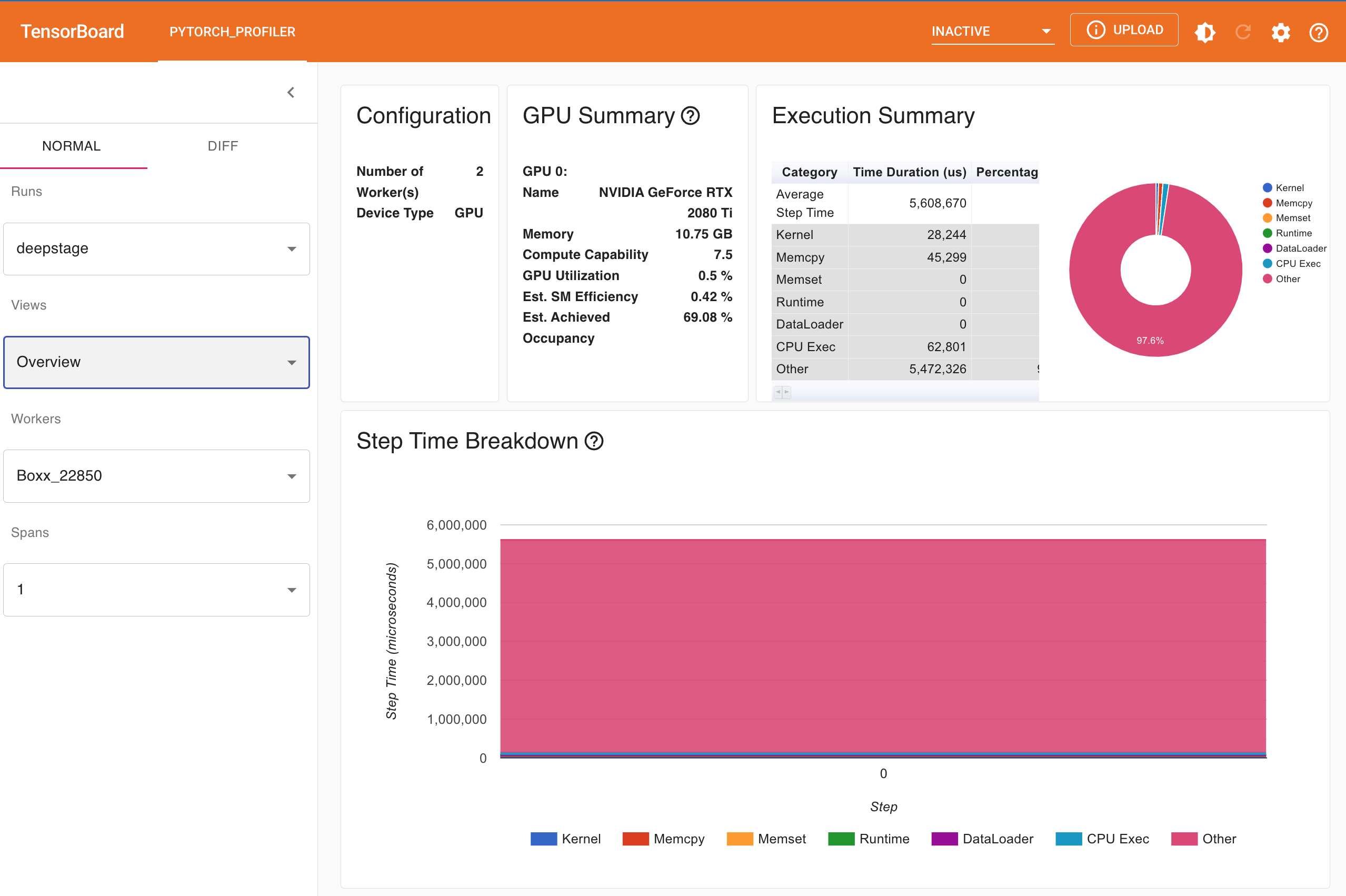
My system is as follows:
NVIDIA Titan V
AMD Threadripper 32-core CPU with 64MB RAM
running Pytorch 1.13.1 + cuda 11.6 installed on Anaconda Python 3.9.x
I’m using Ubuntu 18.04 with kernel 5.14 and nvidia-driver version 525.78.01
My code was adapted from the Pytorch finetuning example code. I’m training a image classification model based on torchvision’s MobileNetV3 (Small) architecture. I’m only retraining the model.classifier layers.
Its extremely frustrating to see Pytorch takes 2.5 sec to train a single batch. Pytorch reports device cuda:0 is available, but my GPU activity seems very low or inactive when training the model (observed using nvidia-smi -l).
My code is as follows:
import torch
from utils.dataloader import MyCustomDataset
import copy
from sklearn.model_selection import KFold
import sklearn.preprocessing
from torch import nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision import models,utils
import torchvision.transforms as T
#import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
from torchmetrics.classification import BinaryAccuracy
from tqdm import tqdm
def train_model(model, criterion, optimizer, scheduler, batch_size, num_epochs=10):
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
kfold = KFold(n_splits=3)
for fold, (train_index, val_index) in enumerate(kfold.split(deepstage_dataset)):
# Print
print(f'FOLD {fold}')
print('=' * 6)
dataloaders={}
dataloaders['train'] = torch.utils.data.DataLoader(deepstage_dataset, batch_size = batch_size, shuffle = True,num_workers=16)
dataloaders['val'] = torch.utils.data.DataLoader(deepstage_dataset, batch_size = batch_size, shuffle = True,num_workers=16)
dataset_sizes = {x: len(dataloaders[x]) for x in ['train', 'val']}
for epoch in range(num_epochs):
print()
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_accuracy = 0.0
loop = tqdm(enumerate(dataloaders[phase]),total=len(dataloaders[phase]),leave=False)
# Iterate over data.
for batch_idx,sample in loop:
inputs = sample['image'].to(device=torch.device('cuda'),dtype=torch.float32)
labels = torch.nn.functional.one_hot(sample['label'],num_classes).to(device=torch.device('cuda'), dtype=torch.float32)
grid = utils.make_grid(inputs)
writer.add_image('images', grid, epoch)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
output = model(inputs)
loss = criterion(output, labels)
writer.add_scalar("Loss[train]", loss, epoch)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
#accuracy = Accuracy(task="multiclass", num_classes=num_classes).to(device)
accuracy = BinaryAccuracy().to(device=torch.device('cuda'))
running_accuracy += accuracy(output, labels).cpu().numpy()
running_loss += loss.item() * inputs.size(0)
#update progress bar
loop.set_description(f"Epoch [{epoch+1}/{num_epochs}]")
loop.set_postfix(loss=running_loss, acc=running_accuracy)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = (running_accuracy / dataset_sizes[phase])
writer.add_scalar("Accuracy[train]", epoch_acc, epoch)
if phase == 'val':
writer.add_scalar("Accuracy[val]", epoch_acc, epoch)
print(f'{phase} loss: {epoch_loss:.4f} acc: {epoch_acc:.4f} ')
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
# load best model weights
model.load_state_dict(best_model_wts)
return model
if __name__ == "__main__":
# Training parameters
data_file = '../../datasets/resized_dataset.csv'
num_classes = 6
feature_extract=True
batch_size = 64
writer = SummaryWriter()
torch.backends.cudnn.benchmark = True
preprocess = T.Compose([
T.ToPILImage(),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
dataset = MyCustomDataset(data_file=data_file,transform = preprocess)
model_ft = models.mobilenet_v3_small(weights='MobileNet_V3_Small_Weights.DEFAULT')
print(model_ft)
model_ft.classifier[3] = nn.Linear(in_features=1024, out_features=num_classes, bias=True)
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
set_parameter_requires_grad(model_ft.features, feature_extract)
# Gather the parameters to be optimized/updated in this run. If we are
# finetuning we will be updating all parameters. However, if we are
# doing feature extract method, we will only update the parameters
# that we have just initialized, i.e. the parameters with requires_grad
# is True.
params_to_update = model_ft.parameters()
print("Params to learn:")
if feature_extract:
params_to_update = []
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t",name)
else:
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
print("\t",name)
criterion = nn.CrossEntropyLoss()
#per layer learning rate
#optimizer_ft = optim.Adam(params_to_update, lr= 1e-2)
optimizer_ft = optim.Adam([
{'params': model_ft.features.parameters()},
{'params': model_ft.classifier.parameters(), 'lr': 1e-2}
], lr=1e-4)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
model_ft = model_ft.to(device)
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
batch_size=batch_size,num_epochs=35)
torch.save(model_ft,'saved_weights/savedmodel.pth')
writer.flush()
writer.close()
since Pytorch conda installtion ships with its own cuda and cudnn libraries, would having a driver that uses CUDA 12.0 (as shown in nvidia-smi`) be the culprit