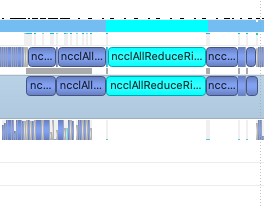
Sure. The code is attached below. The GPU is NVIDIA V100, and GPUDirect is used.
To run the code,
- a dummy fixed-size sample dataset has to be generated. Sample size is 3 * 224 * 224 * 4 Byte. The attached script can be used to generate this dataset.
#! /bin/bash
base="base.file"
dataset_base="your_dir_path"
truncate -s 602112 $base
for class in {0..9}
do
dir="$dataset_base/${class}"
/bin/rm -rf $dir
mkdir -p $dir
echo $dir created
for img_id in {0..1300}
do
fpath="${dataset_base}/${class}/${img_id}.fake"
cp $base $fpath
done
done
-
You have to set master addr and port as env variable, and change the root path in vgg11.py to the created dir path
-
we have two files (one vgg, one data_loader).
-
My test case: 1 GPU per node, 16 nodes, 128 samples per GPU
-
python vgg11.py [batch_size] [rank] [rank_sizes]
-
The print out at the end of the output is the allreduce time spent for applying allreduce directly on each parameter.
vgg11.py
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
import os
import sys
import time
import data_loader
cfg = {
'VGG11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'VGG19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
class VGG(nn.Module):
def __init__(self, vgg_name):
super(VGG, self).__init__()
self.features = self.large_make_layers(cfg[vgg_name])
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(),
nn.Linear(4096, 1000),
)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def large_make_layers(self, cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU()]
else:
layers += [conv2d, nn.ReLU()]
in_channels = v
return nn.Sequential(*layers)
def sync_gradients(model, batch_idx, timer):
""" Gradient averaging. """
global record_event_cnt
for param in model.parameters():
print(param.grad.data.shape)
print("record_event_cnt: %d, batch_idx: %d" % (record_event_cnt, batch_idx))
if batch_idx > 0:
put_timer(record_event_cnt, 1, timer)
dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
if batch_idx > 0:
put_timer(record_event_cnt, 0, timer)
record_event_cnt += 1
def cal_single_time(count, timer):
tot_time = 0.0
global para_cnt
for i in range(count):
print("i: %d" % (i))
time = timer[i].elapsed_time(timer[i + para_cnt])
print("%d time: %lf" % (i, time))
def put_timer(i, start, timer):
global para_cnt
if i >= 0:
if start == 1:
timer[i].record()
print("put start for %d " % (i))
elif start == 0:
#print("put timer for iteration: " + str(i))
timer[para_cnt + i].record()
print("put end for %d" % (para_cnt + i))
N = int(sys.argv[1])
rank = int(sys.argv[2])
world_size = int(sys.argv[3])
record_event_cnt = 0
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # PyTorch device
dist.init_process_group(backend='nccl', rank=rank, world_size=world_size)
net = VGG('VGG11')
net = net.cuda()
#net = torch.nn.parallel.DistributedDataParallel(net, device_ids=[0])
para_cnt = 22
sync_timer=[]
for i in range(para_cnt * 2):
sync_timer.append(torch.cuda.Event(enable_timing=True))
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
optimizer = optim.SGD(net.parameters(), lr=0.1, momentum=0.9)
criterion = nn.CrossEntropyLoss()
#inputs = torch.ones([N, 3, 224, 224], device=device)
#labels = torch.empty(N, dtype=torch.long, device=device).random_(1000)
root_path='your_dir_path'
res_size=224
trainset = data_loader.DatasetFolder(root=root_path, loader=data_loader.raw_data_loader, \
img_size=res_size, extensions=data_loader.IMG_EXTENSIONS, transform=None)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=N, shuffle=True, num_workers=1, pin_memory=True)
torch.cuda.synchronize()
for batch_idx, (inputs, labels) in enumerate(trainloader):
inputs, labels = inputs.to(device), labels.to(device)
if batch_idx == 1:
torch.cuda.synchronize()
start = time.time()
start_event.record()
out = net(inputs)
loss = criterion(out, labels)
loss.backward()
sync_gradients(net, batch_idx, sync_timer)
print("================")
optimizer.step()
optimizer.zero_grad()
if batch_idx == 2:
break
record_event_cnt = 0
end_event.record()
torch.cuda.synchronize()
end = time.time()
print(end-start)
print("iter:%d, %d: %lf, cuda time: %lf"% (batch_idx, N, (end - start), start_event.elapsed_time(end_event)))
print("end record_event_cnt: %d"% (record_event_cnt))
cal_single_time(record_event_cnt, sync_timer)
data_loader.py (some codes are borrowed from original torchvision data loader)
from torchvision import datasets, transforms
import torch
import torchvision
import os
import os.path
import time
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # PyTorch device
def raw_data_loader(path, size, d):
file_content = torch.from_file(path, dtype=torch.float, size=size)
#file_content = file_content.to(torch.float)
file_content.resize_((3, d, d))
return file_content
IMG_EXTENSIONS = ('.jpg', '.jpeg', '.png', '.ppm', '.bmp', '.pgm', '.tif', '.tiff', '.webp', '.fake')
def has_file_allowed_extension(filename, extensions):
"""Checks if a file is an allowed extension.
Args:
filename (string): path to a file
extensions (tuple of strings): extensions to consider (lowercase)
Returns:
bool: True if the filename ends with one of given extensions
"""
return filename.lower().endswith(extensions)
def make_dataset(directory, class_to_idx, extensions=None, is_valid_file=None):
instances = []
directory = os.path.expanduser(directory)
both_none = extensions is None and is_valid_file is None
both_something = extensions is not None and is_valid_file is not None
if both_none or both_something:
raise ValueError("Both extensions and is_valid_file cannot be None or not None at the same time")
if extensions is not None:
def is_valid_file(x):
return has_file_allowed_extension(x, extensions)
for target_class in sorted(class_to_idx.keys()):
class_index = class_to_idx[target_class]
target_dir = os.path.join(directory, target_class)
if not os.path.isdir(target_dir):
continue
for root, _, fnames in sorted(os.walk(target_dir, followlinks=True)):
for fname in sorted(fnames):
path = os.path.join(root, fname)
if is_valid_file(path):
item = path, class_index
instances.append(item)
return instances
class DatasetFolder(datasets.VisionDataset):
def __init__(self, root, loader, img_size, extensions=None, transform=None,
target_transform=None, is_valid_file=None):
super(DatasetFolder, self).__init__(root, transform=transform,
target_transform=target_transform)
classes, class_to_idx = self._find_classes(self.root)
samples = make_dataset(self.root, class_to_idx, extensions, is_valid_file)
if len(samples) == 0:
msg = "Found 0 files in subfolders of: {}\n".format(self.root)
if extensions is not None:
msg += "Supported extensions are: {}".format(",".join(extensions))
raise RuntimeError(msg)
self.loader = loader
self.extensions = extensions
self.img_size = img_size * img_size * 3
self.img_res = img_size
self.classes = classes
self.class_to_idx = class_to_idx
self.samples = samples
self.targets = [s[1] for s in samples]
def _find_classes(self, dir):
"""
Finds the class folders in a dataset.
Args:
dir (string): Root directory path.
Returns:
tuple: (classes, class_to_idx) where classes are relative to (dir), and class_to_idx is a dictionary.
Ensures:
No class is a subdirectory of another.
"""
classes = [d.name for d in os.scandir(dir) if d.is_dir()]
classes.sort()
class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}
return classes, class_to_idx
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (sample, target) where target is class_index of the target class.
"""
path, target = self.samples[index]
sample = self.loader(path, self.img_size, self.img_res)
if self.transform is not None:
sample = self.transform(sample)
if self.target_transform is not None:
target = self.target_transform(target)
return sample, target
def __len__(self):
return len(self.samples)