Hi,
in a recent project I’ve noticed a performance impact in backward pass when packing/unpacking data for LSTMs. To demonstrate, I’ve created a simple LSTM-based network for binary sequence classification:
Net(
(embedding): Embedding(10, 16, padding_idx=0)
(lstm): LSTM(16, 32, batch_first=True)
(linear): Linear(in_features=32, out_features=2, bias=True)
)
Setup A: No padding
- input_ids (shape: batch_size x seq_len):
tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
-
input_lens (shape: batch_size):
tensor([10, 10, 10, 10, 10, 10, 10, 10]) -
target_ids (dummy values, all sequences belong to class ‘0’, shape: batch_size):
tensor([0, 0, 0, 0, 0, 0, 0, 0])
Using pack/unpack only adds minimal overhead, both during forward pass and forward & backward pass. This is good! (see figure below)
Setup B: Padded data
- input_ids (pad_id is 0, shape: batch_size x seq_len):
tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 0, 0, 0, 0, 0, 0, 0]])
-
input_lens (shape: batch_size):
tensor([10, 9, 8, 7, 6, 5, 4, 3]) -
target_ids (dummy values, all sequences belong to class ‘0’, shape: batch_size):
tensor([0, 0, 0, 0, 0, 0, 0, 0])
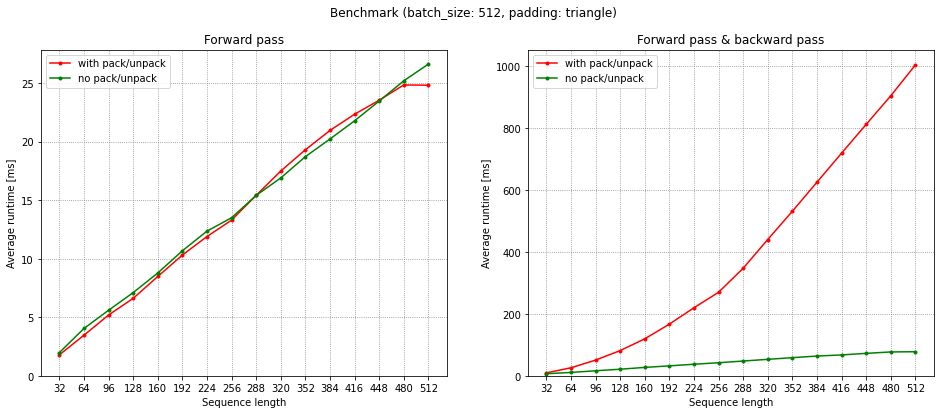
While the forward pass only shows minor overhead using pack/unpack (as expected), there is a performance penalty in backward pass. Is this expected? (see figure below)
Environment
- Torch: 1.12.1+cu116
- OS: Ubuntu 22.04, kernel 5.15
Code
"""
Benchmark torch pack/unpack
"""
import contextlib
import logging
from typing import Optional
import torch
from torch import nn
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
from tqdm import tqdm
import matplotlib.pyplot as plt
logging.basicConfig(
format="%(asctime)s %(message)s",
level=logging.INFO,
datefmt="%H:%M:%S",
)
logger = logging.getLogger(__name__)
def create_batch(
max_seq_len: int,
batch_size: int,
padding_mode: Optional[str],
pad_id: int,
):
input_ids_list = []
input_lens_list = []
length = max_seq_len
for _ in range(batch_size):
if padding_mode is None:
input_ids_list.append([1] * max_seq_len)
input_lens_list.append(max_seq_len)
elif padding_mode == "triangle":
input_ids_list.append(
[1] * length + [pad_id] * (max_seq_len - length)
)
input_lens_list.append(length)
length -= 1
if length == 0:
length = max_seq_len
else:
raise NotImplementedError(padding_mode)
# Dummy target_id values
target_id_list = [0] * batch_size
# Determine sort indices for pack/unpack
sort_ids = sorted(
range(len(input_lens_list)),
key=input_lens_list.__getitem__,
reverse=True,
)
# Apply sorting
input_ids_list = [input_ids_list[sort_id] for sort_id in sort_ids]
input_lens_list = [input_lens_list[sort_id] for sort_id in sort_ids]
target_id_list = [target_id_list[sort_id] for sort_id in sort_ids]
# Convert to tensors
input_ids = torch.tensor(input_ids_list)
input_lens = torch.tensor(input_lens_list)
target_ids = torch.tensor(target_id_list)
return input_ids, input_lens, target_ids
class Net(nn.Module):
def __init__(
self,
vocab_size: int,
embedding_dim: int,
hidden_dim: int,
pad_id: int,
out_features: int,
):
super().__init__()
self.pad_id = pad_id
self.embedding = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=embedding_dim,
padding_idx=pad_id,
)
self.lstm = nn.LSTM(
input_size=embedding_dim,
hidden_size=hidden_dim,
num_layers=1,
bias=True,
batch_first=True,
bidirectional=False,
)
self.linear = nn.Linear(
in_features=hidden_dim,
out_features=out_features,
bias=True,
)
def forward(
self,
input_ids: torch.Tensor,
input_lens: torch.Tensor,
use_pack_unpack: bool,
):
x = self.embedding(input_ids)
if use_pack_unpack:
x = pack_padded_sequence(
input=x,
lengths=input_lens,
batch_first=True,
enforce_sorted=True,
)
x, _ = self.lstm(x)
if use_pack_unpack:
x, _ = pad_packed_sequence(
sequence=x,
batch_first=True,
padding_value=self.pad_id,
)
else:
# Multiply with binary tensor to account for padding
mask = (
input_ids.not_equal(self.pad_id)
.unsqueeze(2)
.repeat((1, 1, x.size(2)))
)
x = torch.mul(x, mask)
x = self.linear(x)
logits = torch.sum(x, dim=1)
return logits
def run_experiment(
net: Net,
min_seq_len: int,
max_seq_len: int,
seq_step: int,
num_runs: int,
batch_size: int,
padding_mode: Optional[str],
pad_id: int,
use_pack_unpack: bool,
do_backward_pass: bool,
device: str,
):
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
optimizer = torch.optim.AdamW(params=net.parameters(), lr=1e-5)
criterion = nn.CrossEntropyLoss(ignore_index=-100)
seq_lens = []
elapsed_times = []
for seq_len in tqdm(range(min_seq_len, max_seq_len + seq_step, seq_step)):
input_ids, input_lens, target_ids = create_batch(
max_seq_len=seq_len,
batch_size=batch_size,
padding_mode=padding_mode,
pad_id=pad_id,
)
input_ids = input_ids.to(device)
target_ids = target_ids.to(device)
# Warmup to prevent powersaving interfere with benchmark
with torch.no_grad():
for _ in range(3):
logits = net(input_ids, input_lens, use_pack_unpack)
# Start benchmark
if do_backward_pass:
context = contextlib.suppress()
else:
context = torch.no_grad()
start.record()
with context:
for _ in range(num_runs):
optimizer.zero_grad()
logits = net(input_ids, input_lens, use_pack_unpack)
loss = criterion(logits.view(-1, 2), target_ids)
if do_backward_pass:
loss.backward()
end.record()
torch.cuda.synchronize()
avg_elapsed_time = start.elapsed_time(end) / num_runs
# Collect results
seq_lens.append(seq_len)
elapsed_times.append(avg_elapsed_time)
return seq_lens, elapsed_times
if __name__ == "__main__":
# Model params
vocab_size = 10
embedding_dim = 16
hidden_dim = 32
out_features = 2
pad_id = 0
# Batch params
batch_size = 512
min_seq_len = 32
max_seq_len = 512
seq_step = 32
# padding_mode = None
padding_mode = "triangle"
# Benchmark params
num_runs = 20
device = "cuda"
# Create model
net = Net(
vocab_size=vocab_size,
embedding_dim=embedding_dim,
hidden_dim=hidden_dim,
pad_id=pad_id,
out_features=out_features,
)
net.to(device)
# Experiments
logger.info("Experiment 1/4: Forward pass, no pack/unpack")
seq_lens_fw, elapsed_times_fw = run_experiment(
net=net,
min_seq_len=min_seq_len,
max_seq_len=max_seq_len,
seq_step=seq_step,
num_runs=num_runs,
batch_size=batch_size,
padding_mode=padding_mode,
pad_id=pad_id,
use_pack_unpack=False,
do_backward_pass=False,
device=device,
)
logger.info("Experiment 2/4: Forward pass, with pack/unpack")
(
seq_lens_fw_use_pack_unpack,
elapsed_times_fw_use_pack_unpack,
) = run_experiment(
net=net,
min_seq_len=min_seq_len,
max_seq_len=max_seq_len,
seq_step=seq_step,
num_runs=num_runs,
batch_size=batch_size,
padding_mode=padding_mode,
pad_id=pad_id,
use_pack_unpack=True,
do_backward_pass=False,
device=device,
)
logger.info("Experiment 3/4: Forward pass & backward pass, no pack/unpack")
seq_lens_fw_bw, elapsed_times_fw_bw = run_experiment(
net=net,
min_seq_len=min_seq_len,
max_seq_len=max_seq_len,
seq_step=seq_step,
num_runs=num_runs,
batch_size=batch_size,
padding_mode=padding_mode,
pad_id=pad_id,
use_pack_unpack=False,
do_backward_pass=True,
device=device,
)
logger.info(
"Experiment 4/4: Forward pass & backward pass, with pack/unpack"
)
(
seq_lens_fw_bw_use_pack_unpack,
elapsed_times_fw_bw_use_pack_unpack,
) = run_experiment(
net=net,
min_seq_len=min_seq_len,
max_seq_len=max_seq_len,
seq_step=seq_step,
num_runs=num_runs,
batch_size=batch_size,
padding_mode=padding_mode,
pad_id=pad_id,
use_pack_unpack=True,
do_backward_pass=True,
device=device,
)
# Plot
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
fig.suptitle(
f"Benchmark (batch_size: {batch_size}, " f"padding: {padding_mode})"
)
# Forward pass
ax1.plot(
seq_lens_fw_use_pack_unpack,
elapsed_times_fw_use_pack_unpack,
".-r",
label="with pack/unpack",
)
ax1.plot(
seq_lens_fw,
elapsed_times_fw,
".-g",
label="no pack/unpack",
)
ax1.set_xticks(list(range(min_seq_len, max_seq_len + seq_step, seq_step)))
ax1.set_xlabel("Sequence length")
ax1.set_ylabel("Average runtime [ms]")
ax1.set_title("Forward pass")
ax1.grid(linestyle="dotted", color="gray")
ax1.set_ylim(bottom=0)
ax1.legend()
# Forward pass & backward pass
ax2.plot(
seq_lens_fw_bw_use_pack_unpack,
elapsed_times_fw_bw_use_pack_unpack,
".-r",
label="with pack/unpack",
)
ax2.plot(
seq_lens_fw_bw,
elapsed_times_fw_bw,
".-g",
label="no pack/unpack",
)
ax2.set_xticks(list(range(min_seq_len, max_seq_len + seq_step, seq_step)))
ax2.set_xlabel("Sequence length")
ax2.set_ylabel("Average runtime [ms]")
ax2.set_title("Forward pass & backward pass")
ax2.grid(linestyle="dotted", color="gray")
ax2.set_ylim(bottom=0)
ax2.legend()