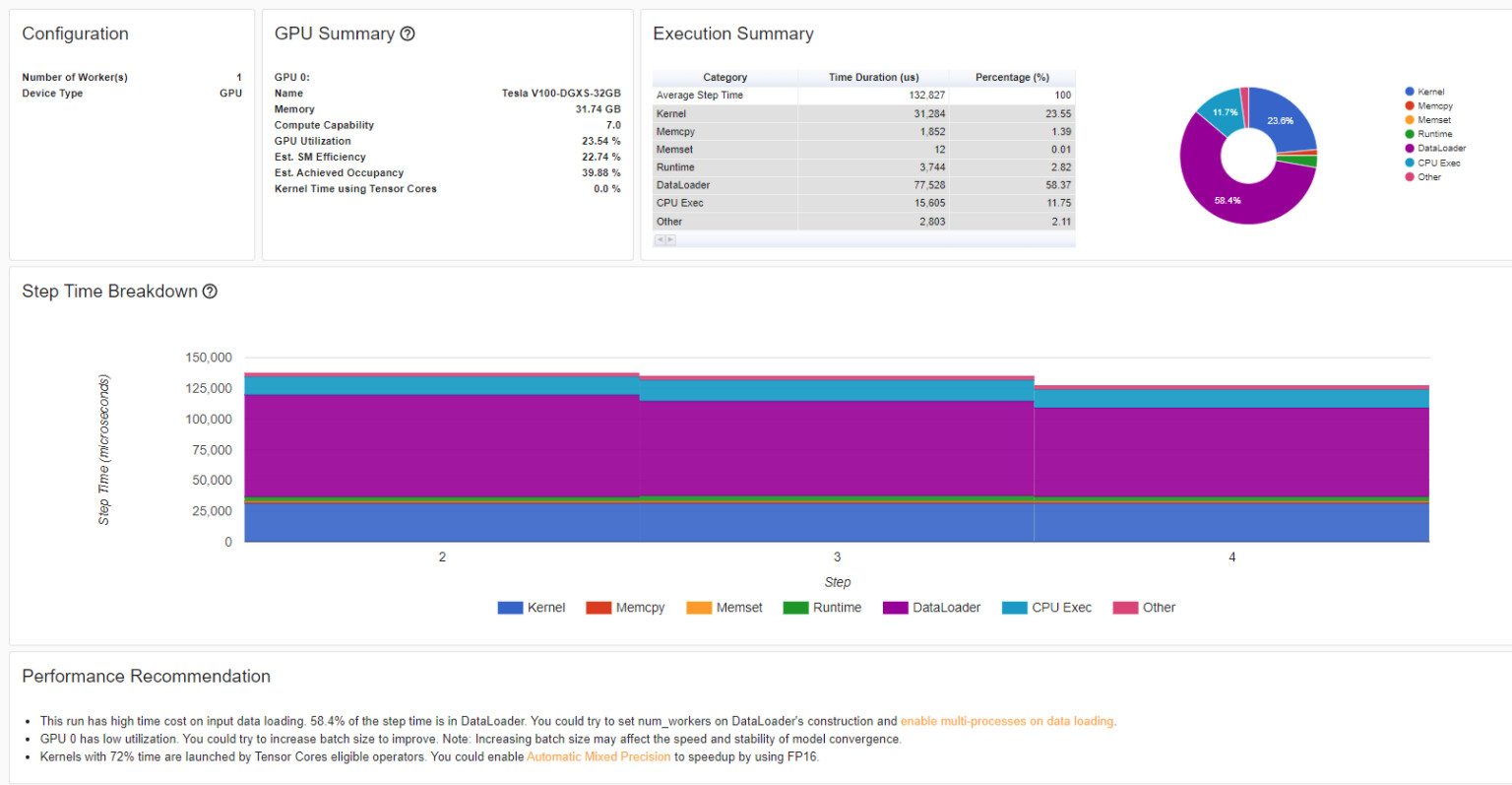
Hi
I’m trying to profile my PyTorch Code. My issue is, that it takes up too much time to train the whole dataset for one epoch,…
I went through the forums and had a look at the synchronization issue between cpu and gpu which I also think is the real bottleneck of my training… However, can it really be, that synchronization takes up most time… and is there a way to overcome this issue and speed it up? - Below you can see my code and I post my bottleneck.txt file which is the output of running my python script with: python -m torch.utils.bottleneck .train.py once without synchronization and once with torch.cuda.synchronize() before x,y = x.to(device), y.to(device)
Additionally, If I set BatchSize to 32 I already run out of Cuda memory, which seems a bit strange since I one Batch would roughly take (since 3234484484) ~ 77MB, or am I missing something?
I would really appreciate your help.
I’m using rgb images with size 448by448 loaded as torch tensors.
BatchSize of 16
I’m using the following Enwironment: with a NVIDIA GeForce RTX 2060 Super with 8GB VRAM
PyTorch 1.9.1 DEBUG compiled w/ CUDA 10.2
Running with Python 3.9 and CUDA 11.2.152
I use the WIDEFace Dataset
def train_fn(train_loader, model, optimizer, loss_fn, epoch, NUM_EPOCHS, device):
loop = tqdm(train_loader)
mean_loss = []
for batch_idx, (x, y) in enumerate(loop):
x, y = x.to(device), y.to(device)
out = model(x)
loss = loss_fn(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_dataset = WiderFace(
train_dir/"train_dataset.csv",
img_dir=train_dir/"images",
target_dir=train_dir/"targets",
transform=transform,
)
train_loader = DataLoader(
dataset=train_dataset,
batch_size=BATCH_SIZE,
num_workers=NUM_WORKERS,
pin_memory=PIN_MEMORY,
shuffle=True,
drop_last=False,
)
for epoch in range(Loaded_Epoch, NUM_EPOCHS):
train_fn(train_loader, model, optimizer, loss_fn, epoch, NUM_EPOCHS, device)
and this is the mentioned bottleneck.txt file:
for batch_idx, (x, y) in enumerate(loop):
x, y = x.to(device), y.cuda()
out = model(x)
loss = loss_fn(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
PS C:\Users\myworkspace> python -m torch.utils.bottleneck .\train.py
`bottleneck` is a tool that can be used as an initial step for debugging
bottlenecks in your program.
It summarizes runs of your script with the Python profiler and PyTorch's
autograd profiler. Because your script will be profiled, please ensure that it
exits in a finite amount of time.
For more complicated uses of the profilers, please see
https://docs.python.org/3/library/profile.html and
https://pytorch.org/docs/master/autograd.html#profiler for more information.
Running environment analysis...
Running your script with cProfile
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 805/805 [02:37<00:00, 5.12it/s]
Running your script with the autograd profiler...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 805/805 [02:36<00:00, 5.15it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 805/805 [02:52<00:00, 4.67it/s]
--------------------------------------------------------------------------------
Environment Summary
--------------------------------------------------------------------------------
PyTorch 1.9.1 DEBUG compiled w/ CUDA 10.2
Running with Python 3.9 and CUDA 11.2.152
`pip3 list` truncated output:
numpy==1.20.3
torch==1.9.1
torchaudio==0.9.1
torchsummary==1.5.1
torchvision==0.10.1
--------------------------------------------------------------------------------
cProfile output
--------------------------------------------------------------------------------
4323004 function calls (4240663 primitive calls) in 159.331 seconds
Ordered by: internal time
List reduced from 4265 to 15 due to restriction <15>
ncalls tottime percall cumtime percall filename:lineno(function)
929 124.101 0.134 124.101 0.134 {method 'to' of 'torch._C._TensorBase' objects}
49910 8.365 0.000 8.365 0.000 {method 'sqrt' of 'torch._C._TensorBase' objects}
805 5.981 0.007 5.981 0.007 {method 'run_backward' of 'torch._C._EngineBase' objects}
8 3.511 0.439 3.512 0.439 {method 'dump' of '_pickle.Pickler' objects}
16100 3.055 0.000 3.055 0.000 {built-in method conv2d}
99820 2.487 0.000 2.487 0.000 {method 'add_' of 'torch._C._TensorBase' objects}
49910 1.484 0.000 1.484 0.000 {method 'addcdiv_' of 'torch._C._TensorBase' objects}
99820 1.227 0.000 1.227 0.000 {method 'mul_' of 'torch._C._TensorBase' objects}
805 1.174 0.001 15.302 0.019 C:\ProgramData\Miniconda3\lib\site-packages\torch\optim\_functional.py:54(adam)
1610 0.826 0.001 1.043 0.001 .\utils\utils.py:67(intersection_over_union)
16100 0.648 0.000 0.648 0.000 {built-in method batch_norm}
49910 0.552 0.000 0.552 0.000 {method 'addcmul_' of 'torch._C._TensorBase' objects}
805 0.515 0.001 2.058 0.003 .\loss.py:35(forward)
16100 0.423 0.000 1.330 0.000 C:\ProgramData\Miniconda3\lib\site-packages\torch\nn\modules\batchnorm.py:133(forward)
49908 0.388 0.000 0.388 0.000 {method 'zero_' of 'torch._C._TensorBase' objects}
--------------------------------------------------------------------------------
autograd profiler output (CPU mode)
--------------------------------------------------------------------------------
top 15 events sorted by cpu_time_total
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
aten::slice 25.88% 768.665ms 25.88% 768.665ms 768.665ms 1
Optimizer.step#Adam.step 0.08% 2.453ms 16.83% 499.711ms 499.711ms 1
aten::sqrt 16.55% 491.380ms 16.55% 491.380ms 491.380ms 1
enumerate(DataLoader)#_MultiProcessingDataLoaderIter... 12.00% 356.295ms 12.00% 356.297ms 356.297ms 1
aten::linear 0.00% 10.500us 11.42% 339.156ms 339.156ms 1
aten::addmm 0.00% 118.700us 11.42% 339.136ms 339.136ms 1
aten::expand 11.42% 339.010ms 11.42% 339.017ms 339.017ms 1
struct torch::autograd::AccumulateGrad 0.00% 12.400us 11.33% 336.566ms 336.566ms 1
aten::add_ 11.33% 336.554ms 11.33% 336.554ms 336.554ms 1
Optimizer.step#Adam.step 8.34% 247.565ms 8.54% 253.622ms 253.622ms 1
struct torch::autograd::AccumulateGrad 0.00% 12.600us 7.55% 224.365ms 224.365ms 1
aten::add_ 7.55% 224.353ms 7.55% 224.353ms 224.353ms 1
aten::to 0.00% 12.400us 6.85% 203.357ms 203.357ms 1
aten::copy_ 6.85% 203.336ms 6.85% 203.336ms 203.336ms 1
aten::to 0.00% 15.000us 6.15% 182.690ms 182.690ms 1
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 2.970s
--------------------------------------------------------------------------------
autograd profiler output (CUDA mode)
--------------------------------------------------------------------------------
top 15 events sorted by cpu_time_total
Because the autograd profiler uses the CUDA event API,
the CUDA time column reports approximately max(cuda_time, cpu_time).
Please ignore this output if your code does not use CUDA.
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg
# of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
aten::slice 26.84% 880.812ms 26.84% 880.813ms 880.813ms 0.000us 0.00% 0.000us 0.000us
1
Optimizer.step#Adam.step 0.24% 7.926ms 20.70% 679.331ms 679.331ms 5.210ms 0.24% 552.289ms 552.289ms
1
aten::sqrt 16.48% 540.855ms 16.48% 540.855ms 540.855ms 540.856ms 24.42% 540.856ms 540.856ms
1
struct torch::autograd::AccumulateGrad 0.00% 22.600us 12.36% 405.571ms 405.571ms 18.875us 0.00% 302.106ms 302.106ms
1
aten::add_ 12.36% 405.548ms 12.36% 405.548ms 405.548ms 302.087ms 13.64% 302.087ms 302.087ms
1
Optimizer.step#Adam.step 8.31% 272.593ms 11.89% 390.295ms 390.295ms 254.762ms 11.50% 263.848ms 263.848ms
1
aten::linear 0.00% 20.400us 11.49% 377.110ms 377.110ms 8.219us 0.00% 336.345ms 336.345ms
1
aten::addmm 0.00% 131.700us 11.49% 377.078ms 377.078ms 336.337ms 15.19% 336.337ms 336.337ms
1
aten::expand 11.48% 376.939ms 11.48% 376.946ms 376.946ms 0.000us 0.00% 0.000us 0.000us
1
enumerate(DataLoader)#_MultiProcessingDataLoaderIter... 10.42% 342.066ms 10.42% 342.069ms 342.069ms 342.175ms 15.45% 342.175ms 342.175ms
1
Optimizer.step#Adam.step 0.75% 24.614ms 9.46% 310.651ms 310.651ms 3.558ms 0.16% 184.869ms 184.869ms
1
struct torch::autograd::AccumulateGrad 0.00% 23.700us 7.63% 250.523ms 250.523ms 19.703us 0.00% 242.705ms 242.705ms
1
aten::add_ 7.63% 250.500ms 7.63% 250.500ms 250.500ms 242.685ms 10.96% 242.685ms 242.685ms
1
aten::addcmul_ 5.22% 171.234ms 5.22% 171.297ms 171.297ms 171.254ms 7.73% 171.299ms 171.299ms
1
Optimizer.step#Adam.step 0.27% 8.945ms 4.96% 162.845ms 162.845ms 15.687ms 0.71% 29.100ms 29.100ms
1
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 3.282s
Self CUDA time total: 2.215s
PS C:\Users\myworkspace> python -m torch.utils.bottleneck .\train.py
`bottleneck` is a tool that can be used as an initial step for debugging
bottlenecks in your program.
It summarizes runs of your script with the Python profiler and PyTorch's
autograd profiler. Because your script will be profiled, please ensure that it
exits in a finite amount of time.
For more complicated uses of the profilers, please see
https://docs.python.org/3/library/profile.html and
https://pytorch.org/docs/master/autograd.html#profiler for more information.
Running environment analysis...
Running your script with cProfile
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 805/805 [02:37<00:00, 5.11it/s]
Running your script with the autograd profiler...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 805/805 [02:36<00:00, 5.16it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 805/805 [02:52<00:00, 4.67it/s]
--------------------------------------------------------------------------------
Environment Summary
--------------------------------------------------------------------------------
PyTorch 1.9.1 DEBUG compiled w/ CUDA 10.2
Running with Python 3.9 and CUDA 11.2.152
`pip3 list` truncated output:
numpy==1.20.3
torch==1.9.1
torchaudio==0.9.1
torchsummary==1.5.1
torchvision==0.10.1
--------------------------------------------------------------------------------
cProfile output
--------------------------------------------------------------------------------
4355290 function calls (4272949 primitive calls) in 159.608 seconds
Ordered by: internal time
List reduced from 4276 to 15 due to restriction <15>
ncalls tottime percall cumtime percall filename:lineno(function)
805 120.567 0.150 120.567 0.150 {built-in method torch._C._cuda_synchronize}
49910 6.984 0.000 6.984 0.000 {method 'addcmul_' of 'torch._C._TensorBase' objects}
805 6.706 0.008 6.706 0.008 {method 'run_backward' of 'torch._C._EngineBase' objects}
929 3.964 0.004 3.964 0.004 {method 'to' of 'torch._C._TensorBase' objects}
8 3.516 0.440 3.517 0.440 {method 'dump' of '_pickle.Pickler' objects}
16100 3.092 0.000 3.092 0.000 {built-in method conv2d}
805 2.546 0.003 14.196 0.018 C:\ProgramData\Miniconda3\lib\site-packages\torch\optim\_functional.py:54(adam)
99820 2.142 0.000 2.142 0.000 {method 'add_' of 'torch._C._TensorBase' objects}
99820 1.250 0.000 1.250 0.000 {method 'mul_' of 'torch._C._TensorBase' objects}
1610 0.838 0.001 1.060 0.001 .\utils\utils.py:67(intersection_over_union)
16100 0.654 0.000 0.654 0.000 {built-in method batch_norm}
49910 0.640 0.000 0.640 0.000 {method 'addcdiv_' of 'torch._C._TensorBase' objects}
49910 0.620 0.000 0.620 0.000 {method 'sqrt' of 'torch._C._TensorBase' objects}
805 0.524 0.001 2.104 0.003 .\loss.py:35(forward)
16100 0.434 0.000 1.352 0.000 C:\ProgramData\Miniconda3\lib\site-packages\torch\nn\modules\batchnorm.py:133(forward)
--------------------------------------------------------------------------------
autograd profiler output (CPU mode)
--------------------------------------------------------------------------------
top 15 events sorted by cpu_time_total
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
aten::slice 24.42% 734.698ms 24.42% 734.699ms 734.699ms 1
Optimizer.step#Adam.step 0.08% 2.342ms 16.87% 507.608ms 507.608ms 1
aten::sqrt 16.60% 499.445ms 16.60% 499.445ms 499.445ms 1
enumerate(DataLoader)#_MultiProcessingDataLoaderIter... 11.78% 354.522ms 11.78% 354.523ms 354.523ms 1
aten::linear 0.00% 8.100us 11.02% 331.525ms 331.525ms 1
aten::addmm 0.00% 133.200us 11.02% 331.506ms 331.506ms 1
aten::expand 11.01% 331.365ms 11.01% 331.373ms 331.373ms 1
struct torch::autograd::AccumulateGrad 0.00% 12.600us 10.77% 324.141ms 324.141ms 1
aten::add_ 10.77% 324.128ms 10.77% 324.128ms 324.128ms 1
struct torch::autograd::AccumulateGrad 0.00% 16.900us 7.77% 233.701ms 233.701ms 1
aten::add_ 7.77% 233.684ms 7.77% 233.684ms 233.684ms 1
Optimizer.step#Adam.step 7.41% 223.067ms 7.61% 228.971ms 228.971ms 1
Optimizer.step#Adam.step 0.07% 2.254ms 5.45% 163.997ms 163.997ms 1
aten::addcmul_ 5.16% 155.399ms 5.17% 155.450ms 155.450ms 1
struct torch::autograd::AccumulateGrad 4.91% 147.732ms 4.91% 147.741ms 147.741ms 1
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 3.009s
--------------------------------------------------------------------------------
autograd profiler output (CUDA mode)
--------------------------------------------------------------------------------
top 15 events sorted by cpu_time_total
Because the autograd profiler uses the CUDA event API,
the CUDA time column reports approximately max(cuda_time, cpu_time).
Please ignore this output if your code does not use CUDA.
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg
# of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
aten::slice 25.20% 812.245ms 25.20% 812.246ms 812.246ms 0.000us 0.00% 0.000us 0.000us
1
Optimizer.step#Adam.step 0.64% 20.729ms 21.05% 678.569ms 678.569ms 3.578ms 0.17% 552.039ms 552.039ms
1
aten::sqrt 16.74% 539.544ms 16.74% 539.544ms 539.544ms 539.542ms 24.99% 539.542ms 539.542ms
1
Optimizer.step#Adam.step 8.22% 265.041ms 11.84% 381.797ms 381.797ms 249.114ms 11.54% 255.477ms 255.477ms
1
aten::linear 0.00% 18.900us 11.54% 372.123ms 372.123ms 15.969us 0.00% 331.311ms 331.311ms
1
aten::addmm 0.00% 128.100us 11.54% 372.092ms 372.092ms 331.295ms 15.34% 331.295ms 331.295ms 1
aten::expand 11.54% 371.957ms 11.54% 371.964ms 371.964ms 0.000us 0.00% 0.000us 0.000us 1
struct torch::autograd::AccumulateGrad 0.00% 43.500us 11.29% 364.049ms 364.049ms 20.516us 0.00% 260.755ms 260.755ms 1
aten::add_ 11.29% 364.005ms 11.29% 364.005ms 364.005ms 260.735ms 12.08% 260.735ms 260.735ms 1
enumerate(DataLoader)#_MultiProcessingDataLoaderIter... 10.84% 349.536ms 10.84% 349.541ms 349.541ms 349.642ms 16.19% 349.642ms 349.642ms 1
Optimizer.step#Adam.step 1.09% 35.262ms 9.71% 313.002ms 313.002ms 3.569ms 0.17% 188.701ms 188.701ms 1
struct torch::autograd::AccumulateGrad 0.00% 21.800us 7.52% 242.532ms 242.532ms 18.531us 0.00% 234.683ms 234.683ms 1
aten::add_ 7.52% 242.510ms 7.52% 242.510ms 242.510ms 234.664ms 10.87% 234.664ms 234.664ms 1
aten::addcmul_ 5.44% 175.450ms 5.45% 175.514ms 175.514ms 175.477ms 8.13% 175.520ms 175.520ms 1
Optimizer.step#Adam.step 1.45% 46.832ms 5.26% 169.472ms 169.472ms 11.611ms 0.54% 25.606ms 25.606ms 1
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 3.223s
Self CUDA time total: 2.159s