I apologize if I’ve missed something obvious here - this question relates to issues I am having timing mixed precision vs float32 computation.
I have two servers - one with Pytorch 1.5 and Cuda 10.1, and the other with Pytorch 1.6 and Cuda 11.0. As far as I know there are no Pytorch CUDA 11.0 binaries, so that pytorch was compiled with 10.1. Both have 2080 Ti RTX GPU cards.
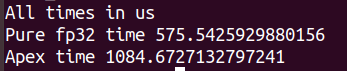
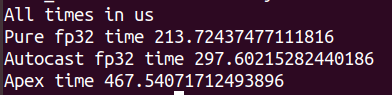
In both servers, I time pure fp32 computation as being significantly faster than mixed precision and I can’t work out why.
I am aware that for the Pytorch1.6 server the mismatch between CUDA versions is not ideal, but I’m still not sure why there should be an issue on the Pytorch 1.5 server.
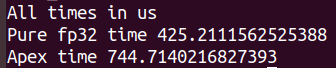
My times are as follows:
Pytorch 1.5:
Pytorch 1.6
I’ve attached gists for the two scripts that I’m using to compute times below.
I experienced a similar phenomenon when running very small networks with amp.autocast. In that case, pure fp16 inference was the fastest followed by fp32 and amp.autocast was the slowest.
Autocasting requires type conversion of input and the corresponding layers before the main computation. Type casting could take more time than the saved time from main computation in lower precision. In larger networks, the gains in computation will be more than the loss from the type conversion.
In your scripts you are rightfully synchronizing before starting the timer, but no synchronization is used when you are stopping the timer.
Thus your timing might be wrong and in fact you might profile the PyTorch overhead and the kernel launch times.
Add syncs before starting and stopping the timer and execute the real workload (forward/backward) inside a loop to get more stable results.
Also, setting torch.backends.cudnn.benchmark = True and cudnn.deterministic = False might also help, as cudnn will profile different algos and will select the fastest one.
Note that this setup would increase the first iteration time (for forward and backward) significantly, as the profiling would be executed, so you should add warmup iterations.
I would also recommend to use the CUDA10.2 binaries, which ship with cudnn7.6.5.32 or the nightly CUDA11.0 binaries, which come now with cudnn8.0.4.30.
Changed the two bools as suggested, added an extra synch call before stopping the timer, add an additional backward pass before timing for profiling for fp32 and a fwd/backward autocast pass. New timing with the additional synch call for the Pytorch 1.5 server:
So the timings went down - due to changing the bool values, as suggested - but still the wrong (intuitively) order.
@seungjun - thanks as well for the tip. I tried with Resnet18 and Resnet50 and the timings are even, which seems more reasonable, though is still a bit surprising.
The 1.6 server is currently occupied, will be able to update tomorrow. Unfortunately, I’m using a cloud provider that only has certain docker images - in this case:
pytorch:1.5.0-cuda10.1-cudnn7-devel
pytorch:1.6.0-cuda10.1-cudnn7-devel
and the two @ptrblck mentioned aren’t available :(.
The CUDA10.2 binaries are available here and you would only have to select this particular version.
The CUDA11 nightly binaries can be installed by using cudatoolkit=11.0 in the conda install command.