I am trying to train EG3D on a slurm cluster using multiple gpus. But am getting the following error:
File "/home/dmpribak/ondemand/data/sys/myjobs/projects/default/4/train.py", line 395, in main
launch_training(c=c, desc=desc, outdir=opts.outdir, dry_run=opts.dry_run)
File "/home/dmpribak/ondemand/data/sys/myjobs/projects/default/4/train.py", line 105, in launch_training
torch.multiprocessing.spawn(fn=subprocess_fn, args=(c, temp_dir), nprocs=c.num_gpus)
File "/home/dmpribak/.conda/envs/eg3d3/lib/python3.11/site-packages/torch/multiprocessing/spawn.py", line 246, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method="spawn")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/dmpribak/.conda/envs/eg3d3/lib/python3.11/site-packages/torch/multiprocessing/spawn.py", line 202, in start_processes
while not context.join():
^^^^^^^^^^^^^^
File "/home/dmpribak/.conda/envs/eg3d3/lib/python3.11/site-packages/torch/multiprocessing/spawn.py", line 163, in join
raise ProcessRaisedException(msg, error_index, failed_process.pid)
torch.multiprocessing.spawn.ProcessRaisedException:
-- Process 1 terminated with the following error:
Traceback (most recent call last):
File "/home/dmpribak/.conda/envs/eg3d3/lib/python3.11/site-packages/torch/multiprocessing/spawn.py", line 74, in _wrap
fn(i, *args)
File "/home/dmpribak/ondemand/data/sys/myjobs/projects/default/4/train.py", line 54, in subprocess_fn
training_loop.training_loop(rank=rank, **c)
File "/home/dmpribak/ondemand/data/sys/myjobs/projects/default/4/training/training_loop.py", line 196, in training_loop
torch.distributed.broadcast(param, src=0)
File "/home/dmpribak/.conda/envs/eg3d3/lib/python3.11/site-packages/torch/distributed/c10d_logger.py", line 47, in wrapper
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/home/dmpribak/.conda/envs/eg3d3/lib/python3.11/site-packages/torch/distributed/distributed_c10d.py", line 1906, in broadcast
work = default_pg.broadcast([tensor], opts)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: CUDA error: CUDA-capable device(s) is/are busy or unavailable
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
I have the latest version of pytorch installed with cuda 12.1. torch.cuda.is_available() returns true and I am able to see both gpus printed with
for i in range(torch.cuda.device_count()): print(torch.cuda.get_device_properties(i).name)
Here is my nvidia-smi output:
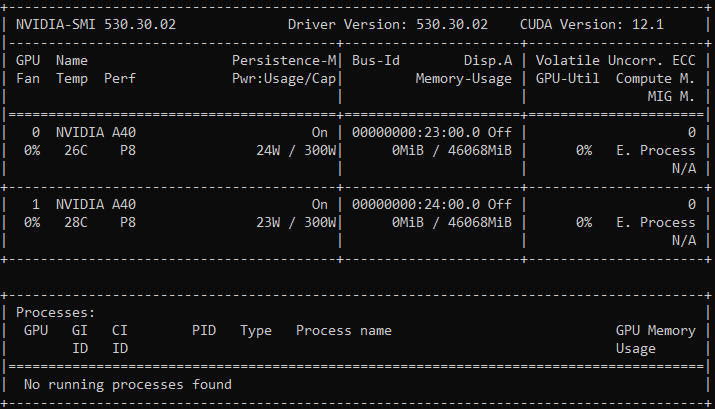
Please let me know if any further information would be helpful in pinning down the cause of this