Hello everyone,
I am working on building a DANN (Ganin et al. 2016) in PyTorch. This model is used for domain adaptation, and forces a classifier to only learn features that exist in two different domains, for the purpose of generalization across these domains. The DANN uses a Gradient Reversal layer to achieve this.
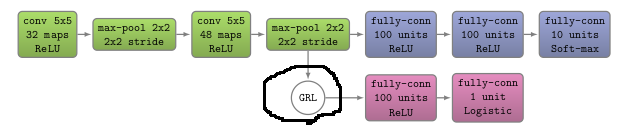
I have seen some suggestions on this forum on how to modify gradients manually. However, I found it difficult to apply in my case, as the gradients are reversed midway through the backward pass (see the image, the gradients are reversed once the backward pass reaches the feature extractor, through the GRL (grad reverse layer)).
Below is my take on this, though I am not sure if I have used the hook correctly. I would greatly appreciate some suggestions on how to use these hooks effectively!
# this is the hook to reverse the gradients
def grad_reverse(grad):
return grad.clone() * -lambd
lambd = 1
# 2) train feature_extractor and domain_classifier on full batch x
# reset gradients
f_ext.zero_grad()
d_clf.zero_grad()
# calculate domain_classifier predictions on batch x
d_out = d_clf(f_ext(x).view(batch_size, -1))
# use normal gradients to optimize domain_classifier
f_d_loss = d_crit(d_out, yd.float())
f_d_loss.backward(retain_variables = True)
d_optimizer.step()
# use reversed gradients to optimize feature_extractor
d_out.register_hook(grad_reverse)
f_d_loss = d_crit(d_out, yd.float())
f_d_loss.backward(retain_variables = True)
f_optimizer.step()
Thanks,
Daniel
