Environment:
PyTorch 0.3.0.post4 with CUDA 9.0.176 and CUDNN 7.0 (“7003”) installed via conda on Python 3.5, with NVIDIA driver 387.34.
Ran a simple test doing 100 forward passes (batch size 16, image size 3x224x224) on torchvision.models.vgg16.
On 1080 Ti, this takes ~1.20ms per pass.
On Titan V, this takes ~1.64ms per pass.
Titan V is about 37% slower.
Here’s the code used:
import torch
from torchvision.models import vgg16
print('cuda version=', torch.version.cuda)
print('cudnn version=', torch.backends.cudnn.version())
model = vgg16().cuda()
model.eval()
durations = []
num_runs = 100
for i in range(num_runs + 1):
x = torch.rand(16, 3, 224, 224)
x_var = torch.autograd.Variable(x).cuda()
t1 = time()
model(x_var)
t2 = time()
# treat the initial run as warm up and don't count
if i > 0:
durations.append(t2 - t1)
print(t2-t1)
print('avg over {} runs: {}'.format(len(durations), sum(durations) / len(durations)))
Has anyone seen this sort of performance degradation on Titan V against 1080 Ti?
I can provide the “nvvp” profiling output, if anyone thinks it would be helpful to troubleshoot.
With torch.backends.cudnn.benchmark = True added, here are the results!!!
vgg16 passes:
1080 Ti: 41.4ms
Titan V: 31.3ms
resnet152 passes:
1080 Ti: 60.4ms
Titan V: 49.0ms
densenet121 passes:
1080 Ti: 29.9ms
Titan V: 26.2ms
Looks like adding this magic line works!!!
Thanks @Soumith_Chintala!
As a user, I was expecting that simply popping in a Titan V would work a little faster than a 1080 Ti without modifying my code (I posted a toy example here, but my VGG16-based MVCNN that I used for object classification ran much slower as well, so that’s why I posted this.)
it enables cudnn autotuner, it is the same line used in the official imagenet example. it cannot be enabled by default because if your inputs to your network are variable size (i.e. change in shape every time), then autotuner will kick-in everytime, which is a high overhead.
Let me get this correctly.
You recommend using torch.backends.cudnn.benchmark = True in any program where the dimensions of the input to the net doesn’t change over the batches.
By the way, what if I use PyTorch as “GPU Accelerated NumPy”, should I use this as well?
It would be great to a guideline how to use this feature.
Look like Titan V is not so fast compared to 1080Ti.
Could you test full timing of forward-backward pass for your both card. Here is the script which I prepare, which test 3 mentioned architecture in both FP32 and FP16 (I’m not sure if FP16 is used in right way, anybody could check?). I would like to compare Tesla V100 vs Titan V vs 1080Ti (in that case only FP32).
import torch
from torchvision.models import vgg16,densenet121,resnet152
from time import time
import torch.nn as nn
import torch.backends.cudnn as cudnn
import torch.optim
from torch.autograd import Variable
import torchvision.models as models
torch.backends.cudnn.benchmark=True
model_names = sorted(name for name in models.__dict__
if name.islower() and not name.startswith("__")
and callable(models.__dict__[name]))
print('cuda version=', torch.version.cuda)
print('cudnn version=', torch.backends.cudnn.version())
for arch in ['densenet121', 'vgg16', 'resnet152']:
model = models.__dict__[arch]().cuda()
loss = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.SGD(model.parameters(), 0.001,
momentum=0.9,
weight_decay=1e-5)
durations = []
num_runs = 100
for i in range(num_runs + 1):
x = torch.rand(16, 3, 224, 224)
x_var = torch.autograd.Variable(x).cuda()
target = Variable(torch.LongTensor(16).fill_(1).cuda())
torch.cuda.synchronize()
t1 = time()
out = model(x_var)
err = loss(out, target)
err.backward()
optimizer.step()
torch.cuda.synchronize()
t2 = time()
# treat the initial run as warm up and don't count
if i > 0:
durations.append(t2 - t1)
print('{} FP 32 avg over {} runs: {} ms'.format(arch, len(durations), sum(durations) / len(durations) * 1000))
model = models.__dict__[arch]().cuda().half()
loss = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.SGD(model.parameters(), 0.001,
momentum=0.9,
weight_decay=1e-5)
durations = []
num_runs = 100
for i in range(num_runs + 1):
x = torch.rand(16, 3, 224, 224)
x_var = torch.autograd.Variable(x).cuda().half()
target = Variable(torch.LongTensor(16).fill_(1).cuda())
torch.cuda.synchronize()
t1 = time()
out = model(x_var)
err = loss(out, target)
err.backward()
optimizer.step()
torch.cuda.synchronize()
t2 = time()
# treat the initial run as warm up and don't count
if i > 0:
durations.append(t2 - t1)
print('{} FP 16 avg over {} runs: {} ms'.format(arch, len(durations), sum(durations) / len(durations) * 1000))
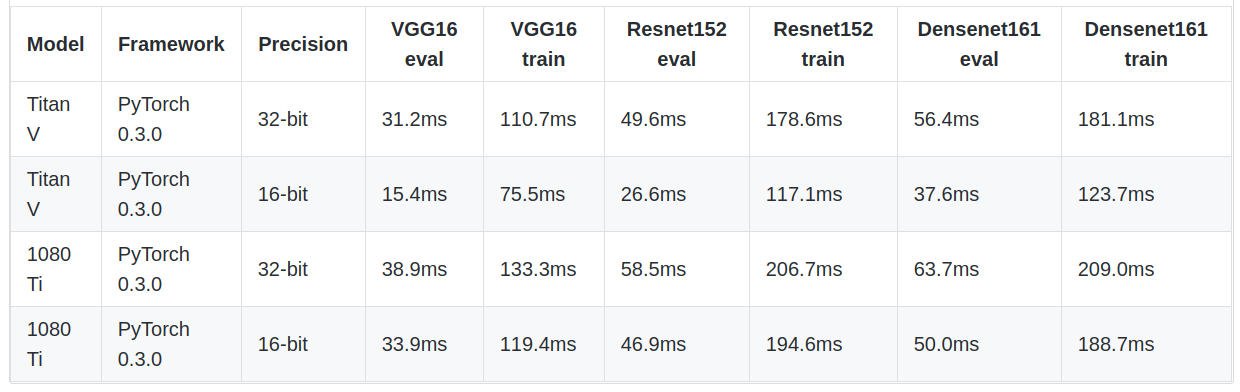
I have tested it V100 on AWS p3 instance and here are the results:
('cuda version=', '9.0.176')
('cudnn version=', 7003)
densenet121 FP 32 avg over 100 runs: 66.9194436073 ms
densenet121 FP 16 avg over 100 runs: 59.2770695686 ms
vgg16 FP 32 avg over 100 runs: 85.537352562 ms
vgg16 FP 16 avg over 100 runs: 56.5851545334 ms
resnet152 FP 32 avg over 100 runs: 134.783308506 ms
resnet152 FP 16 avg over 100 runs: 87.0116662979 ms
cuda version= 9.0.176
cudnn version= 7005
densenet121 FP 32 avg over 100 runs: 86.58529281616211 ms
densenet121 FP 16 avg over 10 runs: 71.90406322479248 ms
vgg16 FP 32 avg over 100 runs: 111.51945352554321 ms
vgg16 FP 16 avg over 10 runs: 71.55098915100098 ms
resnet152 FP 32 avg over 100 runs: 174.67097759246826 ms
resnet152 FP 16 avg over 10 runs: 109.48643684387207 ms
1080 Ti:
cuda version= 9.0.176
cudnn version= 7005
densenet121 FP 32 avg over 100 runs: 96.0409951210022 ms
densenet121 FP 16 avg over 10 runs: 84.02540683746338 ms
vgg16 FP 32 avg over 100 runs: 139.82041120529175 ms
vgg16 FP 16 avg over 10 runs: 120.87807655334473 ms
resnet152 FP 32 avg over 100 runs: 205.37179708480835 ms
resnet152 FP 16 avg over 10 runs: 193.45839023590088 ms
With fp16 inputs on v100 pytorch uses tensor cores when available. For mutrix multiplication to use tensor cores matrices dimensions should be multiples of 8.
I was also wondering if PyTorch is passing the right parameters to take advantage of the Tensor Cores, so I added debug statements in the PyTorch code, compiled from source, and ran it. From the looks of it, PyTorch was passing the right parameters to CuDNN and CUDA to take advantage wherever possible.
I also tried to use nvprof to capture the actual CUDA calls made. Even though it captures all the CUDA API calls made, it does not show if the execution was done on Tensor Cores or not (as @ngimel mentioned, specific conditions must be met, etc., even though API calls are made with the right parameters/algo.) I’ve filed a ticket on NVIDIA and they confirmed that they still need to expose such metrics (they are capturing the info, just not exposing) and that they are working on it.