when i implemented a neural network to fitting a function of some datas with numpy and i noticed that its performance is so bad and even with no any use .i found its gradient is so big that the parameters W go to minus-large number immediatly. obviously, it didnt work for the test data.in that program,i use params-=grad(compute by Chain derivative)*learningrate.when i implement the same network with pytorch,i found it works well than numpy-version. i start to find the diffrence between the two version.i find the rule of torch.optim.Adam().step() dont work as my thoughts,it update the weights(params) by params-=(the sign of grad(+or-)lr,not the gradlearningrate,why is this.is that pytorch will do some Optimization of processing to help training my model?and i didnt see some Similar operation in torch.optim.Adam().step()'s sorce code from pytorch’s Document.hope someone can help me expain this.thanks in advance.
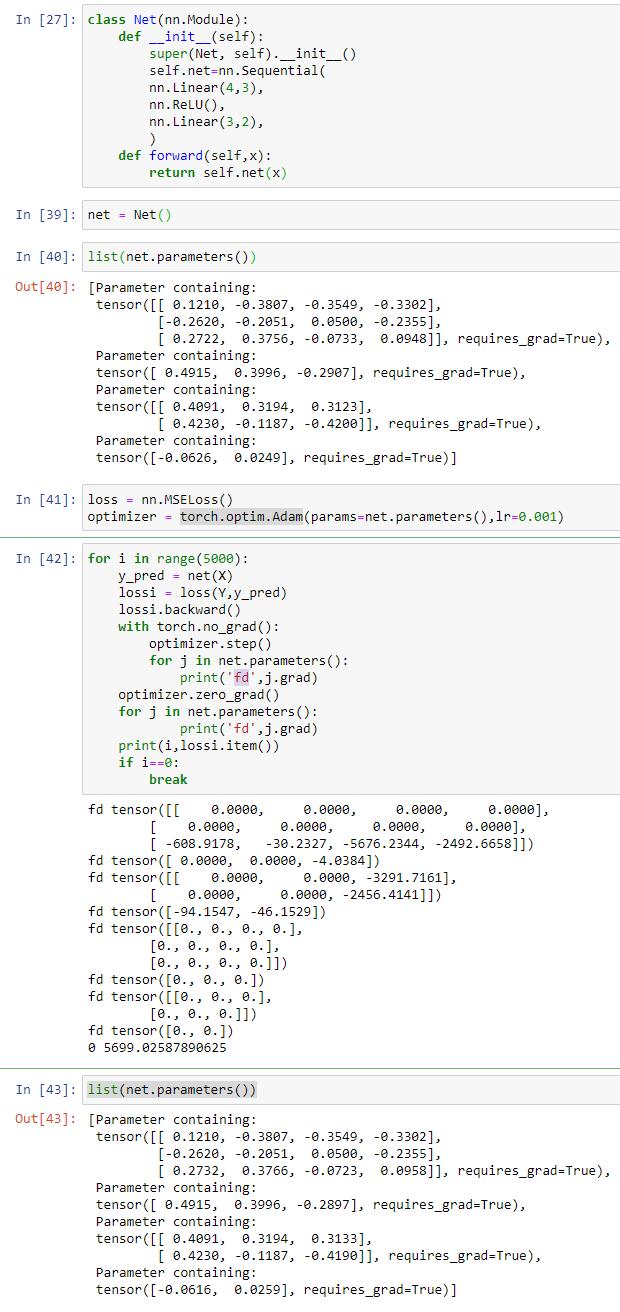
sry i forgot the optimizer i choose is Adam…not SGD