Hi there,
I want to implement a class of sparse neural networks, the picture is an example for the class H_0 for the parameters d = 5, d_star = 1, M_star = 2.
This network class works kind of good, but when I use a random uniform distributed values as input, I get always an almost constant output (untrained).
When I train the network, it gets better sometimes (if I use y_train = f(x_train) as labels for some nonlinear function f).
Unfortunally I want to use this network class, to implement an even deeper network class which uses H_0 networks as its layers.
Because the H_0 give almost constant output, the output of my “bigger” class is completely constant even after training.
Any ideas why the networks behave like that?
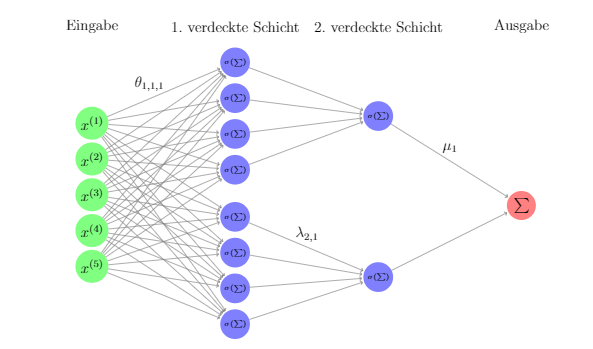
This is my class, which uses the class smallDense to obtain the sparsity.
`
import math
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
class smallDense(nn.Module):
def __init__(self, d, d_star):
super(smallDense, self).__init__()
self.fc1 = nn.Linear(d,4*d_star)
self.fc2 = nn.Linear(4*d_star,1)
def forward(self, input):
x = torch.sigmoid(self.fc1(input))
x = torch.sigmoid(self.fc2(x))
return x
class H_0(nn.Module):
def __init__(self, d, d_star, M_star):
super(H_0, self).__init__()
self.networks = nn.ModuleList([smallDense(d, d_star) for i in range(M_star)])
self.fc_out = nn.Linear(M_star, 1)
def forward(self, input):
outputs = []
for i in range(len(self.networks)):
x = torch.sigmoid(self.networks[i](input))
outputs.append(x)
result = torch.cat(outputs, dim=1)
x = self.fc_out(result)
return x
net = H_0(5,1,3)
x_train = torch.rand(100,5)
net(x_train)`

 thank you! Training progress also works fine now on the bigger model!
thank you! Training progress also works fine now on the bigger model!