I have written a small gist of a self-contained experiment:
I am working with high dimensionality (~50000). This profile below is that of the train procedure with num_workers = 0.
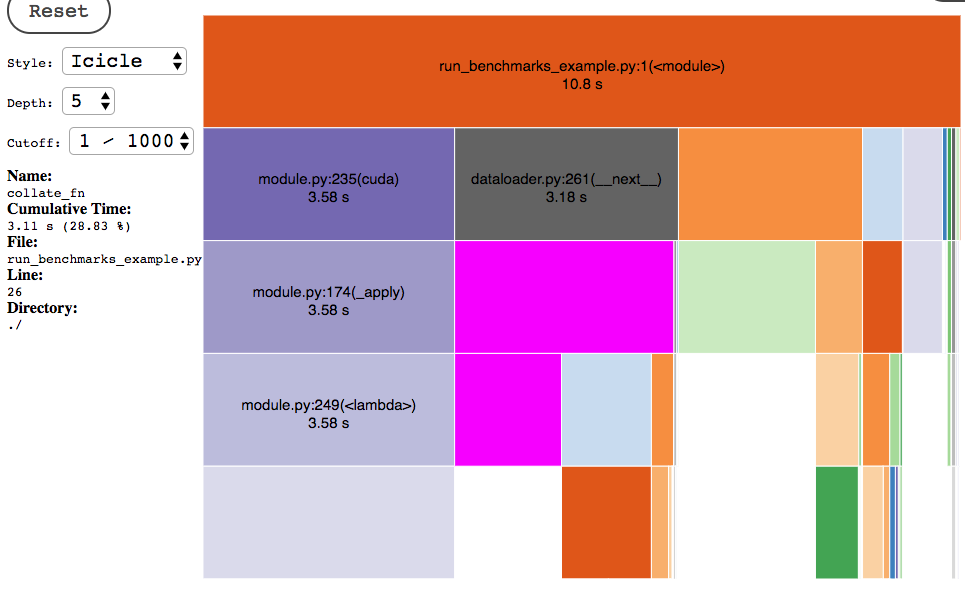
I am wondering how much I could optimize the dataloader iteration step which looks time-consuming to me.
Adding more workers doesn’t seem to change anything, even with torch.multiprocessing.set_start_method(“spawn”) ( which by the way had to be set with flag force=True, otherwise raising a “context already set” error ).
I have in mind a blog article (Optimizing PyTorch training code - Sagivtech), where they claim that “no time is spent on data-loading / preprocessing”. But it didn’t make things any faster in my case.
When reducing significantly the dimensionality, say to 1000 (instead of 50000), the dataloader is really minor for the overall time of the training procedure. So, is the behaviour in the first expected or would there be any way to reduce that time ?