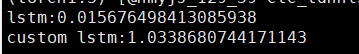I write an example to compare the cumputation capability of native lstm and custom lstm.
But I found that the speed of custom lstm is 100 times slower than native lstm class.
My torch version is 1.3.1, GPU is TITANV with Cuda10 and cuDNN7.4.1
I also tried on pytorch 1.1, GPU TITAN XP with CUDA9.1, which has same ratio of speed.
The TorchScript runtime does some optimizations on the first pass (it assumes you will be running your compiled model’s inference many times), so this is likely why it looks much slower. Could you try running custom_lstm a couple times before you benchmark it and comparing?
I met the same problem. is there any way to disable the optimization or choose the optimization level or after optimization we can save the model.because when I load the torchscript model in C++, the first pass takes about 20s while the others’ infer time is about 0.5s.
you could try setting torch._C._jit_set_profiling_mode() to True and torch._C._jit_set_profiling_mode to False
This mode was specifically added for speeding up compilation times for inference.
You could also indeed try with torch.jit.optimized_execution() if compilation times are still high for you. The latter runs even fewer optimizations.
when I use python the torch.jit.optimized_execution() could solve the problem, thanks
however, how should I solve this problem in C++?
thanks in andvanve
Hi, I still have some questions about the custom RNN:
I am able to reproduce senmao’s results that lstm and custom lstm have similar performance in 1000 times, but this is partly due to the original lstm becomes worse. This can be seen in senmao’s results. The first run of the original lstm is 0.015. If the performance is consistent, 1000 runs would take 15 seconds instead of 49.758 as reported (I have verified this myself).
Although I have no idea why the original lstm becomes worse, I get rid of the problem by changing the hyper parameters to:
input_size = 37
cell_size =256
batch_size =128
seq_len = 60
Now the original lstm becomes stable. In this case, the custom lstm is 10 times slower than the original lstm. Here are the results of 1000 runs: lstm:1.54s, custom lstm:19.75s. Can anyone please suggest how the custom lstm can be modified to have comparable performance with the original lstm?
Hi senmao! I’m writting you because I tried to get your results by my own… but, I cound’t get them. I have the same as you posted and I’m getting the time by this code: