I am using a customized convolutional function, including F.unfold and F.fold. However, both training time and inference time is much longer than the original conv2d operation in pytorch. Anyone know how can I speed up F.unfold and F.fold? Thank you!
Hi,
unfold and fold should be very fast as they only play with stride in general. Are you sure they are responsible for the slowdown.
If you compare with a general convolution algorithm, depending on the input, it is not always the most efficient to do the unfold, mm, fold.
Hi,
Thank you so much for your kind reply! That is strange because I used torchprof to measure the time cost of each operation and found im2col (I believe it’s unfold) and col2img (fold) account for the most of the time cost. Below is the profiling results:

I also attach my unfold and fold code. I would be really appreciate if you can tell me where is the problem.
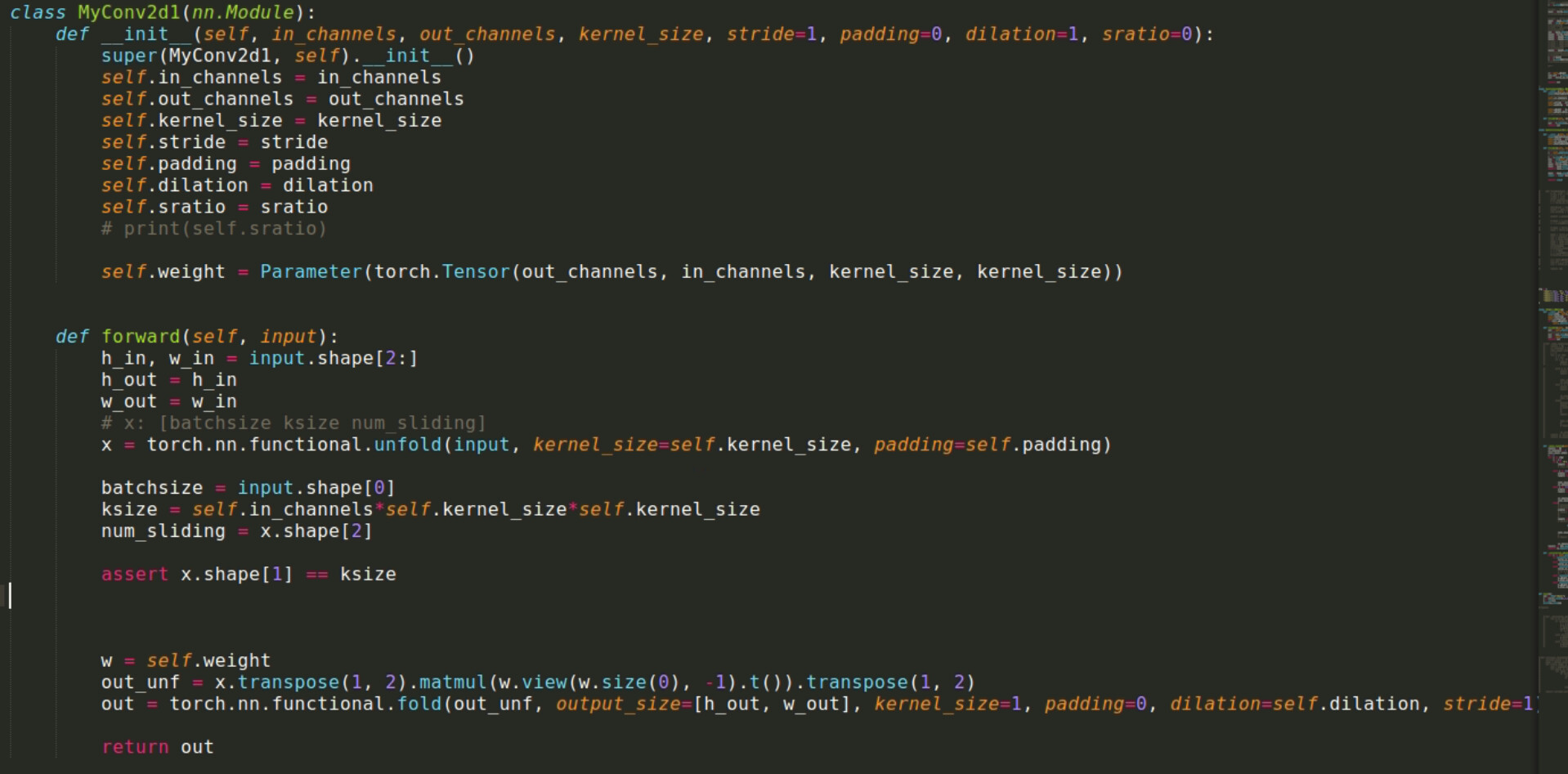
Thank you so much!
If I use a general nn.conv2d, the training time of each batch (256 batch size) is only 80ms. However, if I use my customized conv2d, the training time will increase to 800ms.
That is indeed very surprising.
Are all the timings measured with proper cuda synchronization?
Also could you share a text version of your module so that I can easily copy paste it and make an independent repro of the timing?
Of course, thank you for your help. Below is the text code:
class MyConv2d1(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, sratio=0):
super(MyConv2d1, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.dilation = dilation
self.sratio = sratio
# print(self.sratio)
self.weight = Parameter(torch.cuda.FloatTensor(out_channels, in_channels, kernel_size, kernel_size))
def forward(self, input):
h_in, w_in = input.shape[2:]
h_out = h_in
w_out = w_in
# x: [batchsize ksize num_sliding]
x = torch.nn.functional.unfold(input, kernel_size=self.kernel_size, padding=self.padding)
batchsize = input.shape[0]
ksize = self.in_channels*self.kernel_size*self.kernel_size
num_sliding = x.shape[2]
assert x.shape[1] == ksize
w = self.weight
out_unf = x.transpose(1, 2).matmul(w.view(w.size(0), -1).t()).transpose(1, 2)
out = torch.nn.functional.fold(out_unf, output_size=[h_out, w_out], kernel_size=1, padding=0, dilation=self.dilation, stride=1)
return out
Running the following on CPU is slower but not that bad:
In particular, the fold is “almost free” as it does not do any copy.
And the two other ops have a similar cost as they go through the big unfolded Tensor once each.
import torch
from torch import nn
from torch.nn import Parameter
import time
class MyConv2d1(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, sratio=0):
super(MyConv2d1, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.dilation = dilation
self.sratio = sratio
# print(self.sratio)
# CHANGED: Remove cuda
self.weight = Parameter(torch.rand(out_channels, in_channels, kernel_size, kernel_size))
def forward(self, input):
h_in, w_in = input.shape[2:]
h_out = h_in
w_out = w_in
# x: [batchsize ksize num_sliding]
start = time.time()
x = torch.nn.functional.unfold(input, kernel_size=self.kernel_size, padding=self.padding)
print(" Unfold: ", time.time() - start)
batchsize = input.shape[0]
ksize = self.in_channels*self.kernel_size*self.kernel_size
num_sliding = x.shape[2]
assert x.shape[1] == ksize
w = self.weight
start = time.time()
out_unf = x.transpose(1, 2).matmul(w.view(w.size(0), -1).t()).transpose(1, 2)
print(" Mm: ", time.time() - start)
start = time.time()
out = torch.nn.functional.fold(out_unf, output_size=[h_out, w_out], kernel_size=1, padding=0, dilation=self.dilation, stride=1)
print(" Fold: ", time.time() - start)
return out
in_c = 10
out_c = 15
kernel = 3
padding = 1 # Custom Module only works when output is same size as input
inp = torch.rand(2, in_c, 50, 50)
conv = torch.nn.Conv2d(in_c, out_c, kernel, padding=padding)
custom_conv = MyConv2d1(in_c, out_c, kernel, padding=padding)
start = time.time()
out = conv(inp)
print("Regular: ", time.time() - start)
start = time.time()
out = custom_conv(inp)
print("Custom: ", time.time() - start)
Sorry, I am a little bit confused. First, I think my code is running on the GPU. Second, I re-compare Myconv2d1 and nn.Conv2d. The training time of each batch is 450ms vs 100ms. I guess the extra 300ms is coming from fold and unfold, is that correct?
Thank you!
Is it that possible the the cost of these two operations during training are much larger than inference?
I also compare the inference time cost which is: customize(200ms) vs conv2d (30ms). According to your testing results, the difference should not be such large, right? Sorry, I am a new learner, there are a lot of things that confused me. Thank you.
You are correct. I changed it to run on CPU because timing on GPU is a bit trickier (synchonization etc).
The overall backward time is similar to the forward one:
import torch
from torch import nn
from torch.nn import Parameter
import time
class MyConv2d1(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, sratio=0):
super(MyConv2d1, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.dilation = dilation
self.sratio = sratio
# print(self.sratio)
# CHANGED: Remove cuda
self.weight = Parameter(torch.rand(out_channels, in_channels, kernel_size, kernel_size))
def forward(self, input):
h_in, w_in = input.shape[2:]
h_out = h_in
w_out = w_in
# x: [batchsize ksize num_sliding]
start = time.time()
x = torch.nn.functional.unfold(input, kernel_size=self.kernel_size, padding=self.padding)
print(" Unfold: ", time.time() - start)
batchsize = input.shape[0]
ksize = self.in_channels*self.kernel_size*self.kernel_size
num_sliding = x.shape[2]
assert x.shape[1] == ksize
w = self.weight
start = time.time()
mat_inp1 = x.transpose(1, 2)
mat_inp2 = w.view(w.size(0), -1).t()
mat_out = mat_inp1.matmul(mat_inp2)
out_unf = mat_out.transpose(1, 2)
print(" Mm: ", time.time() - start)
start = time.time()
out = torch.nn.functional.fold(out_unf, output_size=[h_out, w_out], kernel_size=1, padding=0, dilation=self.dilation, stride=1)
print(" Fold: ", time.time() - start)
# Setup backward hooks to time backward
# This does not count the backward of all the view/transposes
backward_times = []
out.register_hook(lambda grad: backward_times.append(time.time()))
mat_out.register_hook(lambda grad: backward_times.append(time.time()))
x.register_hook(lambda grad: backward_times.append(time.time()))
out_unf.register_hook(lambda grad: print(" Back fold: ", time.time() - backward_times[-1]))
mat_inp1.register_hook(lambda grad: print(" Back mm: ", time.time() - backward_times[-1]))
input.register_hook(lambda grad: print(" Back unfold: ", time.time() - backward_times[-1]))
return out
in_c = 10
out_c = 15
kernel = 3
padding = 1 # Custom Module only works when output is same size as input
inp = torch.rand(2, in_c, 50, 50, requires_grad=True)
conv = torch.nn.Conv2d(in_c, out_c, kernel, padding=padding)
custom_conv = MyConv2d1(in_c, out_c, kernel, padding=padding)
start = time.time()
out = conv(inp)
print("Regular: ", time.time() - start)
start = time.time()
out.sum().backward()
print("Regular backward: ", time.time() - start)
start = time.time()
out = custom_conv(inp)
print("Custom: ", time.time() - start)
start = time.time()
out.sum().backward()
print("Custom backward: ", time.time() - start)
I also compare the inference time cost which is: customize(200ms) vs conv2d (30ms). According to your testing results, the difference should not be such large, right?
Right, at least not on CPU.
Thank you so much for helping me! In that case, do you have ideas that can speed up fold and unfold on GPU? I want to use my customized conv2d to training models, but the time cost is really expensive.
Interesting, when I increased the batchsize in your code (inp = torch.rand(2, in_c, 50, 50, requires_grad=True) → inp = torch.rand(512, in_c, 50, 50, requires_grad=True) ), the time cost of both training and inference of costumize conv2d increased dramatically. Am I correct? Thank you!
Both gets slower right?
Regular: 0.21726393699645996
Regular backward: 0.42275333404541016
Unfold: 0.357952356338501
Mm: 0.4160928726196289
Fold: 0.08525800704956055
Custom: 0.8644123077392578
Back fold: 0.07413196563720703
Back mm: 0.2995262145996094
Back unfold: 0.44156312942504883
Custom backward: 0.8373520374298096
But the custom is still between 2 and 4 times slower.
Thank you so much for helping me! In that case, do you have ideas that can speed up fold and unfold on GPU?
I am not sure if there is anything you can do.
The thing is that on GPU, cudnn has very fine tuned algorithms to do convolution that are significantly better than MM.
Can you try comparing the runtimes on GPU when cudnn is disabled via torch.backends.cudnn.enabled = False?
You are right! When I set torch.backends.cudnn.enabled = False, the training time cost increased from 50ms to 200ms, which similar to customized conv2d.
Ok.
So the unfold/mm/fold is as good as a specialized conv implementation based on mm
But cudnn implementation is much better for your particular sizes.
Sorry about that 
1 Like
You help me a lot! I really appreciate that. Thank you! 