Hello
While returning to training from a checkpoint spikes on training loss occurs as shown in the figure below
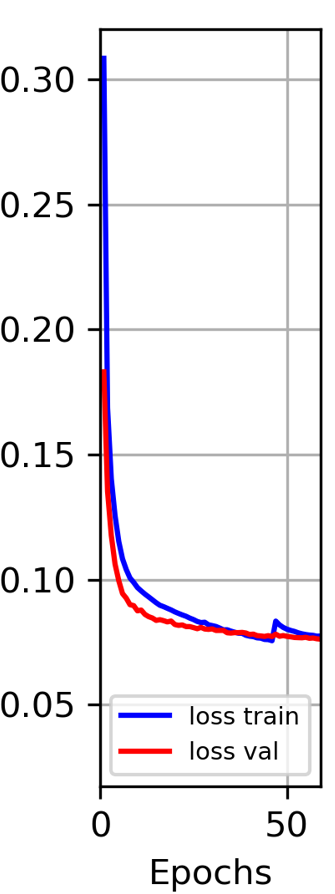
While defining loss, optimizer and learning rate scheduler I use
criterion=torch.nn.MSELoss(size_average=True, reduce=True, reduction='mean')
optimizer=torch.optim.Adam(model.parameters(), lr=learning_rate)
lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer,
mode='min',
factor=0.75,
patience=math.ceil(patience_chunk_count),
threshold=0.0001,
threshold_mode='rel',
cooldown=0,
min_lr=0,
eps=1e-08,
verbose=True,
)
While saving checkpoint I use
checkpoint = {
...
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'lr_scheduler_state_dict': lr_scheduler.state_dict(),
...
}
While loading from a checkpoint I use
checkpoint = torch.load(path_checkpoints_file, map_location=torch.device('cpu'))
model.load_state_dict(checkpoint['model_state_dict'])
model.to(device)
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler_state_dict'])
And my training loop is something like below
for epoch in range (currentEpoch, num_epochs+1):
...
learning_rate = optimizer.param_groups[0]['lr']
...
model.train()
for i,(inputs, labels, inputs_metadata) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss_train=criterion(outputs, labels)
optimizer.zero_grad()
loss_train.backward()
optimizer.step()
...
I see other people struggling with the same problem.
Does anyone know the reason for the problem?
How can I solve the problem in a naive way?