I’m trying to use an LSTM model to predict the right hand side of the system of ODE’s for a pendulum.
Problem: There are several strange spikes in my learning curves:
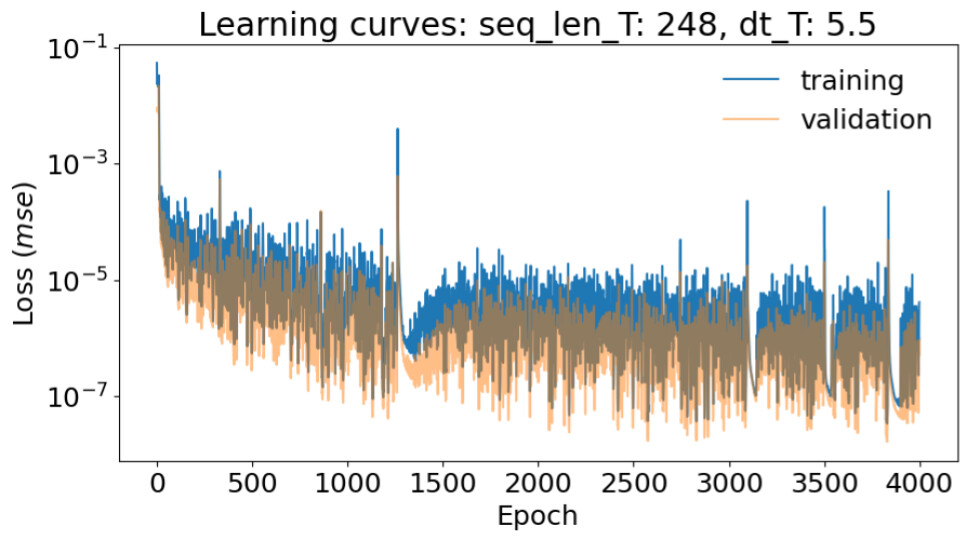
Turns out if I make drop_last=True in my dataloader those spikes disappear.
Dropping the last mini batch seems to be a workaround. Is there a better way to address this problem? Is there a bug in my training loop that causes this?
Also, this appears to only happen when the sequence length is long (this one is 248*5.5=1364). Smaller sequence lengths do not have spikes like that, which also makes me think I have a bug somewhere.
def train_model(datatrain_IP, datatrain_OP, time_data, n_val, batch_size, model, nepoch, lrate, reg_factor, reg_type, device_name,
epoch_in=0, train_loss_history=(), val_loss_history = (), drop_last=False):
# define the loss_func & optimizer
loss_func = nn.MSELoss()
running_loss = 0.0
optimizer = optim.NAdam(model.parameters(), lr=lrate)
# randomly split into train & validation data loaders
train_dl, val_dl = prepare_data(datatrain_IP, datatrain_OP, time_data, n_val, batch_size, drop_last=drop_last)
# enumerate epochs
for epoch in range(epoch_in,nepoch):
model.train()
# enumerate mini batches
for i, (inputs, targets, _) in enumerate(train_dl):
inputs = inputs.to(device_name, non_blocking=False)
targets = targets.to(device_name, non_blocking=False)
# clear the gradients
optimizer.zero_grad()
# compute the model output
yhat = model(inputs)
# calculate loss
loss = loss_func(yhat, targets)
# find gradient of loss w.r.t tensors
loss.backward()
# update model weights
optimizer.step()
# calculate statistics
running_loss += loss.item()
# calculate average mse amongst all mini-batches in current epoch
train_loss_history = train_loss_history + (running_loss/(i+1),)
running_loss = 0.0
# Validation
model.eval()
# validation loss
mse, actuals, predictions, val_time = evaluate_model(val_dl, model, device_name)
val_loss_history = val_loss_history + (mse,)
return train_loss_history, val_loss_history, optimizer, epoch, loss, val_data_actual, val_data_predictions, val_time