Hi,
In the image below I have described a process that I want to construct.
The environment: I have n scenes and in each scene I have m snapshots.
My goal: For each scene, a dataloader should sample B batch size number of snapshots. These samples are then to be appropriately processed and entered into the red pool in the form of a pytorch dataset. After this, the base dataloader can take A batch size number of scenes from the n number of scenes (processed snapshots from corresponding scenes).
So what I need is nested dataloaders inside of dataloaders.
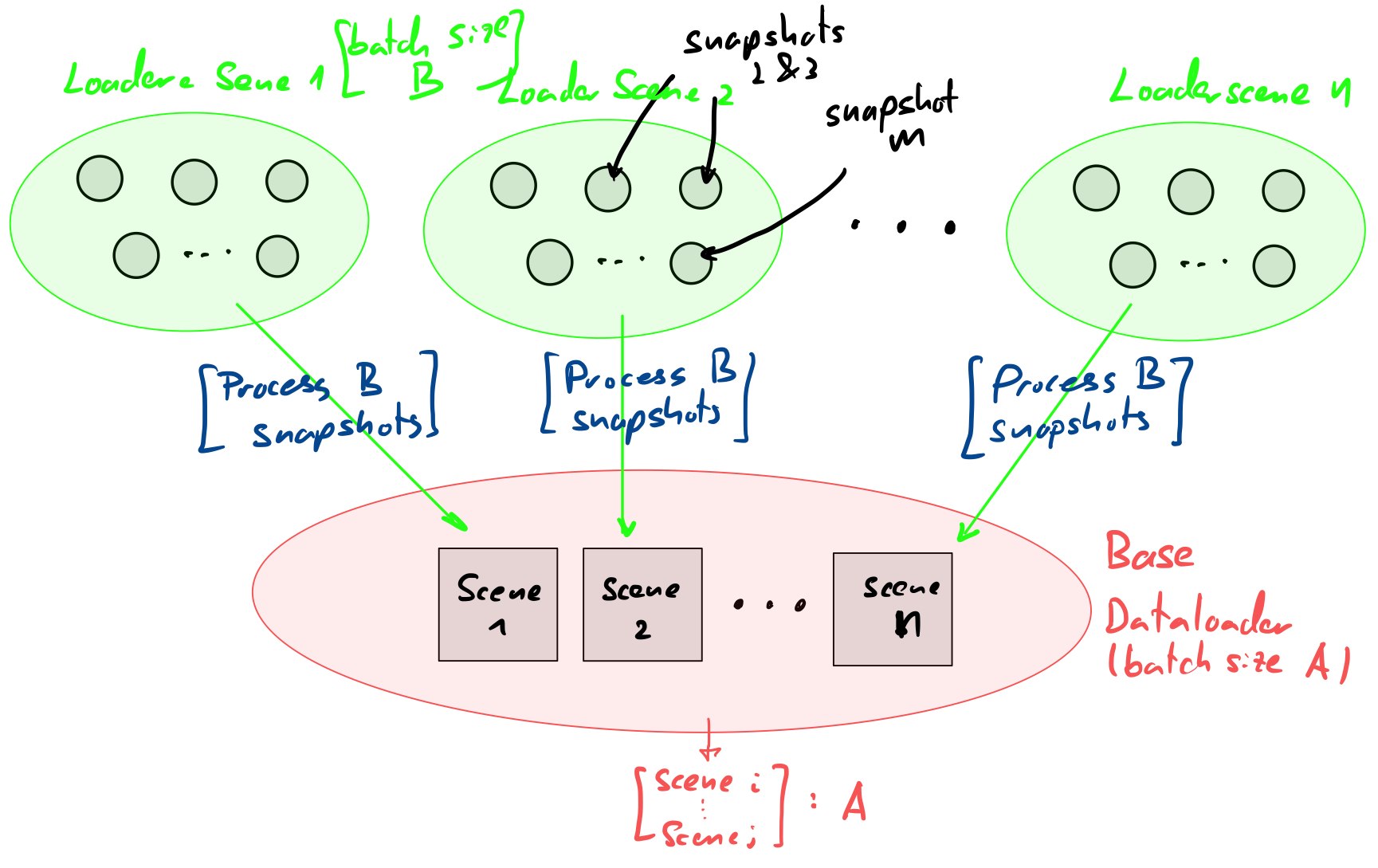
For the case where I simply take the entire m number of snapshots from a given scene (i.e. I do not need the nested DataLoader) I have written the following code:
class MyDataset(Dataset):
def __init__(self, data_dir):
self.data_dir = data_dir
self.data_files = os.listdir(self.data_dir)
self.data_files.sort()
def __getitem__(self, idx):
return self.load_file(self.data_files[idx])
def __len__(self):
return len(self.data_files)
def load_file(self, hdf5_file):
f = File(self.data_dir+'/'+hdf5_file, "r")
inputs, target = some_irrelevant_function_for_processing_data(f.get('...'))
return inputs, target
if __name__ == '__main__':
processed_path = 'some/path'
dataset = MyDataset(data_dir=processed_path)
loader = DataLoader(dataset, num_workers=8, batch_size=1)
for inputs, target in loader:
print(inputs.shape, target.shape)
Finally what I would like is to efficiently leverage workers across the DataLoading framework.
I have not been able to find relevant posts about this. If you can link me relevant posts or give me advice on how to set this up that would be great!
Thanks in advance.