import torch
import torch.nn as nn
import torch.nn.functional as f
import spacy
import torchtext
from torchtext.data import TabularDataset,BucketIterator,Field
import pandas as pd
import numpy as np
df_train = pd.read_csv('V:\\pythonproject\\nlp\\New folder\\headlines\\train.csv')
df_test = pd.read_csv('V:\\pythonproject\\nlp\\New folder\\headlines\\test.csv')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
spacy_eng = spacy.load('en')
stop_words = spacy.lang.en.stop_words.STOP_WORDS
def tokenize(text):
return [tok.text for tok in spacy_eng.tokenizer(text) if tok.text not in stop_words]
text = Field(tokenize=tokenize,lower=True,batch_first=True)
label = Field(sequential=False,use_vocab=False)
auth = Field(sequential=False,use_vocab=False)
#short_d = Field(tokenize=tokenize,lower=True,batch_first=True)
fields = {'healine':('t1',text),'short_description':('t2',text),'author':('au',auth),'label':('l',label)}
train_data,test_data = TabularDataset.splits(path='V:\\pythonproject\\nlp\\New folder\\headlines',
train='train.csv',validation='test.csv',
format = 'CSV',fields = fields)
text.build_vocab(train_data,max_size=50000,min_freq = 1)
train_iterator, test_iterator = BucketIterator.splits(
(train_data, test_data), batch_size=4, device=device,sort = False,shuffle=False
)
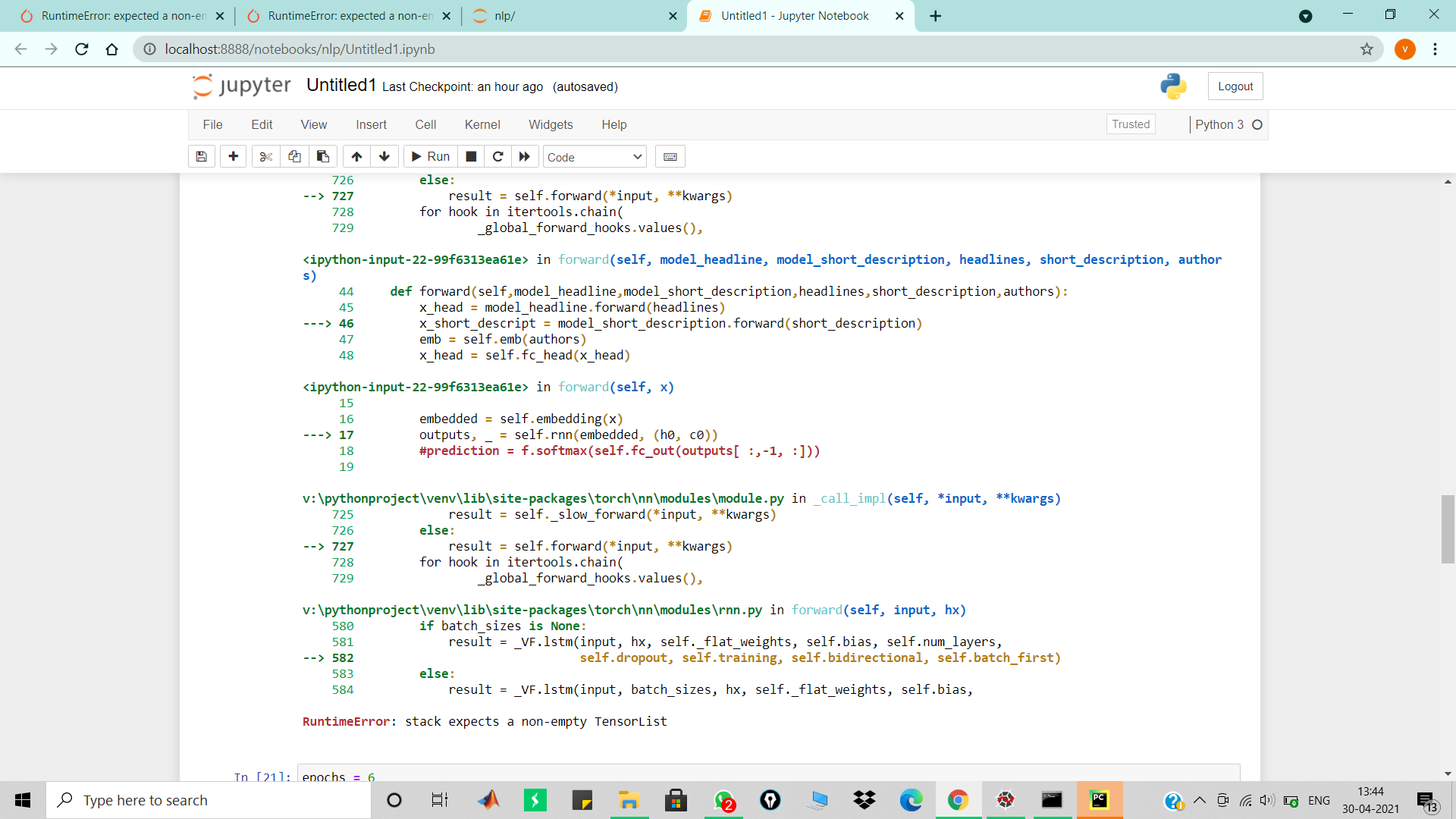
class RNN_LSTM(nn.Module):
def __init__(self, input_size, embed_size, hidden_size, num_layers):
super(RNN_LSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.embedding = nn.Embedding(input_size, embed_size)
self.rnn = nn.LSTM(embed_size, hidden_size, num_layers,batch_first=True)
#self.fc_out = nn.Linear(hidden_size, 41)
def forward(self, x):
# Set initial hidden and cell states
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
embedded = self.embedding(x)
outputs, _ = self.rnn(embedded, (h0, c0))
#prediction = f.softmax(self.fc_out(outputs[ :,-1, :]))
return outputs[ :,-1, :]
#hyper parameters
input_size = len(text.vocab)
hidden_size = 128
num_layers = 1
embedding_size = 100
learning_rate = 0.005
num_epochs = 6
model_headline = RNN_LSTM(input_size, embedding_size, hidden_size, num_layers).to(device)
model_short_description = RNN_LSTM(input_size, embedding_size, hidden_size, num_layers).to(device)
class NN(nn.Module):
def __init__(self):
super().__init__()
self.emb = nn.Embedding(max(df_train['author'].max(),df_test['author'].max())+1,128)
self.fc_head = nn.Linear(128,32)
self.fc_short = nn.Linear(128,16)
self.fc_emb = nn.Linear(128,8)
self.fc1 = nn.Linear(56,128)
self.fc2 = nn.Linear(128,41)
def forward(self,model_headline,model_short_description,headlines,short_description,authors):
x_head = model_headline.forward(headlines)
x_short_descript = model_short_description.forward(short_description)
emb = self.emb(authors)
x_head = self.fc_head(x_head)
x_short_descript = self.fc_short(x_short_descript)
x_authors = self.fc_emb(emb)
x = torch.cat((x_head,x_short_descript,x_authors),dim=1)
return f.softmax(self.fc2(self.fc1(x)),dim=1)
model = NN().to(device=device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr = learning_rate)
def train(model,rnn_models, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
for batch_idx, batch in enumerate(iterator):
head = batch.t1.to(device=device)
short = batch.t2.to(device=device)
author = batch.au.to(device=device)
targets = batch.l.to(device=device)
scores = model(rnn_models[0],rnn_models[1],head,short,author)
loss = criterion(scores, targets).to(device)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def evaluate(model, rnn_models, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
for batch_idx, batch in enumerate(iterator):
head = batch.t1.to(device=device)
short = batch.t2.to(device=device)
author = batch.au.to(device=device)
targets = batch.l.to(device=device)
scores = model(rnn_models[0], rnn_models[1], head, short, author)
loss = criterion(scores, targets).to(device)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
import time
for epoch in range(6):
start_time = time.time()
train_loss = train(model,[model_headline,model_short_description] ,train_iterator, optimizer, criterion)
valid_loss = evaluate(model,[model_headline,model_short_description], test_iterator, criterion)
end_time = time.time()
print(f'Epoch: {epoch + 1:02} | Epoch Time: {(end_time - start_time) / 60}')
print(f'\tTrain Loss: {train_loss:.3f}')
print(f'\t Val. Loss: {valid_loss:.3f}')
dataset is from News Category Dataset | Kaggle