Hi,
I am trying to quantize a UNet model using builtin static quantization functions.
- Pytorch CPU version 1.9.1
- Ubuntu 20.04 LTS (conda env)
The model itself is referenced from here. I modified the model as follows (showing the quantization parts alone) :
class UNet(nn.Module):
def __init__(self, num_classes, quantize=False):
super(UNet, self).__init__()
self.num_classes = num_classes
""" QUANTIZED VERSION ADDITIONS """
self.quantize = quantize
self.quant = torch.quantization.QuantStub()
self.dequant = torch.quantization.DeQuantStub()
def forward(self, X):
# Outputs are dequantized
if self.quantize == True:
output_out = self.dequant(output_out)
# pass through other layers
# Outputs are dequantized
if self.quantize == True:
output_out = self.dequant(output_out)
return output_out
The quantization function is as follows:
def quantizeUNet(model, device, dataLoader, use_fbgemm=False):
model.to(device)
model.eval()
modules_to_fuse = [['contracting_11.0', 'contracting_11.2'],
['contracting_11.3', 'contracting_11.5'],
['contracting_21.0', 'contracting_21.2'],
['contracting_21.3', 'contracting_21.5'],
['contracting_31.0', 'contracting_31.2'],
['contracting_31.3', 'contracting_31.5'],
['contracting_41.0', 'contracting_41.2'],
['contracting_41.3', 'contracting_41.5'],
['middle.0', 'middle.2'],
['middle.3', 'middle.5'],
['expansive_12.0', 'expansive_12.2'],
['expansive_12.3', 'expansive_12.5'],
['expansive_22.0', 'expansive_22.2'],
['expansive_22.3', 'expansive_22.5'],
['expansive_32.0', 'expansive_32.2'],
['expansive_32.3', 'expansive_32.5'],
['expansive_42.0', 'expansive_42.2'],
['expansive_42.3', 'expansive_42.5']]
#print(modules_to_fuse)
model = torch.quantization.fuse_modules(model, modules_to_fuse)
if use_fbgemm == True:
model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
else:
model.qconfig = torch.quantization.default_qconfig
torch.quantization.prepare(model, inplace=True)
## Calibrate Quantization parameters on input dataset
print('Calibrating Quantization parameters on input dataset ...')
model.eval()
with torch.no_grad():
for data, target in dataLoader:
model(data)
torch.quantization.convert(model, inplace=True)
print('### Static Quantization complete ###')
return model
During inference, the output tensor (shape [1, 10, 256, 256]) contains 0s only.
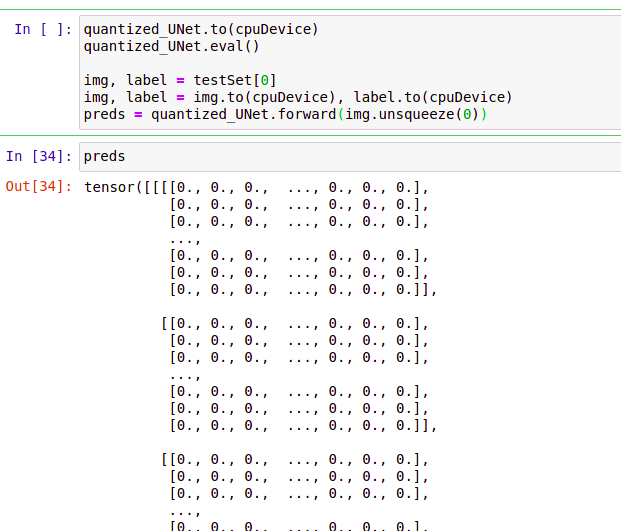
I expected the output to have probabilities for each class (10 classes in total). But its essentially zero matrix. Is there something I’m missing? How to do static quantization of the model correctly?