Hello,
I am currently following the official PyTorch static quantization tutorial for quantizing my model. The model uses a ResNet backbone and implements other things as a Generalized Mean Pooling, the complete code can be accessed here in this gist.
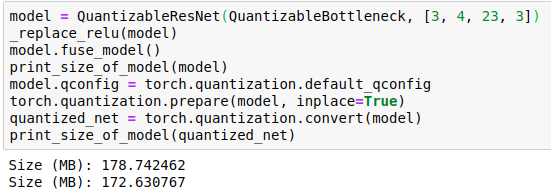
I could follow the tutorial steps and run the torch.quantization.convert(myModel, inplace=True) line to finally quantize my model, but when I check the size of the model, it’s almost the same size as before quantizing (186mb to 174mb).
The main code is this (complementary to the gist):
# My own function to load the checkpoint
ckpt = common.load_checkpoint(settings.CKPT_MODEL, False)
# The definition of QuantizableRMAC is in the gist
# But it is similar to how is done in the tutorial
qnet = QuantizableRMAC(**ckpt["model_options"])
qnet.fuse_model() # Fuse model here!!!!
qnet.eval()
qnet.qconfig = torch.quantization.default_qconfig
torch.quantization.prepare(qnet, inplace=True)
data_loader = quantizable_dataloader("path/to/images")
def evaluate(model, data_loader):
cnt = 0
with torch.no_grad():
for image, _ in data_loader:
model(image)
evaluate(qnet, data_loader, 1)
quantized_net = torch.quantization.convert(qnet)
def print_size_of_model(model):
torch.save(model.state_dict(), "temp.p")
print('Size (MB):', os.path.getsize("temp.p")/1e6)
os.remove('temp.p')
print_size_of_model(quantized_net)
for p in quantized_net.parameters():
print(p.dtype)
The last line prints only torch.float32.