Hi,
I need to track the computation and storage of different parts of my network training.
To be on the same page, let’s assume the simple following scenario (biases omitted)
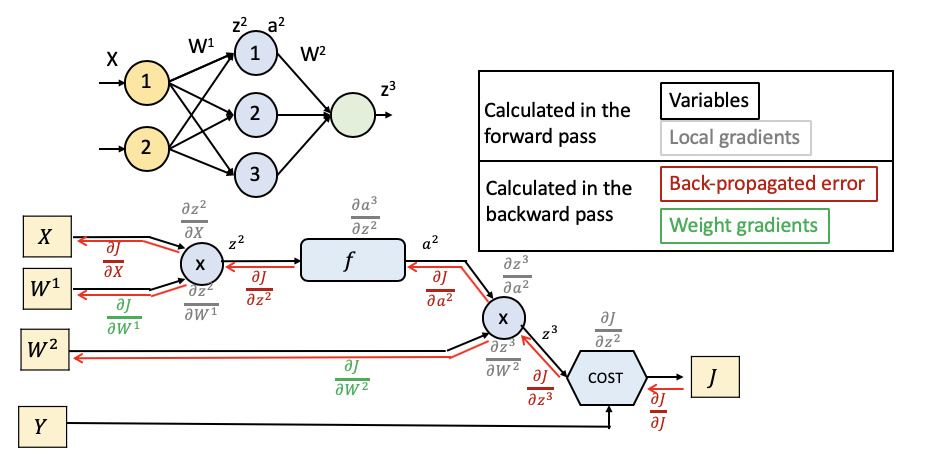
Questions
Local Gradients
- Are the intermediate gradients always stored in memory until they are consumed in the backward pass, being eliminated after that? Or is there an option to not storing but recompute them when needed during the backward pass?
- How can I access those values right after they are computed in the forward pass? Is there anything similar to
self.layer_i.weight.data.numpy()?
Back-Propagated Error
- Is it right the theoretical understanding of back-propagated error?
In the Glorot and Bengio paper (equations 13 and 14 in particular) they make a different analysis for weight gradients and back-propagated gradients and I want to make sure I got that right before analyzing anything. - Is it possible again to access directly these values from the networks attributes? Something like required_grad = True that could allow me to use
self.layer_i.weight.data.numpy()for the input instead of for the parameters (weights)?
Thank you