I have a classifier, and I want to compute outputs from the model in the training and validation modes. I am also checking their respective accuracies. However, I found one interestingly strange behaviour.
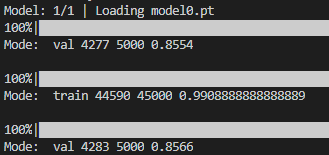
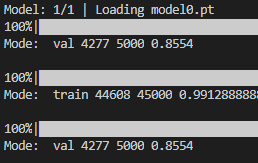
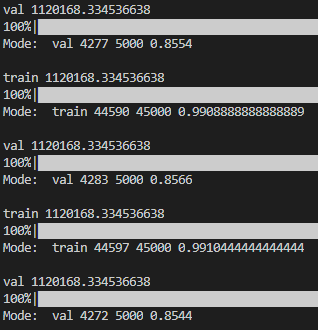
I have already pre-trained the model (ResNet-18) on Cifar-10 and saved the best model on the validation set with accuracy 85.54%. When I run get_outputs function on the same data, I get same accuracy in the val set. However, if I will change the order of mode, s.t. instead of for mode in ['val', 'train'] I will write for mode in ['train', 'val'], val accuracy will be 85.66%. I do not understand why this happens.
@torch.no_grad()
def get_outputs(model, loader_dict, device):
batches = {'train': [], 'val': []}
correct = {'train': 0, 'val': 0}
total = {'train': 0, 'val':0}
for params in model.parameters():
params.requires_grad = False
for mode in [ 'val', 'train']:
if mode == 'train':
model.train()
else:
model.eval()
for _, (inputs, targets) in enumerate(tqdm(loader_dict[mode])):
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
batches[mode].append(outputs.detach().cpu())
_, predicted = outputs.max(1)
predicted = predicted.cpu()
total[mode] += targets.size(0)
correct[mode] += predicted.eq(targets.cpu()).sum().item()
return correct, total
The way I create a loader_dict:
train_size = int(0.9 * len(dataset))
val_size = len(dataset) - train_size
train_data, val_data = random_split(dataset, [train_size, val_size], generator = torch.Generator().manual_seed(42))
train_loader = DataLoader(train_data, batch_size = 128, shuffle = True,
num_workers = 8, pin_memory = True, generator = torch.Generator().manual_seed(42))
val_loader = DataLoader(val_data, batch_size = 128, shuffle = False,
num_workers = 8, pin_memory = True, generator = torch.Generator().manual_seed(42) )
loader_dict = {'train': train_loader,
'val': val_loader}

In the picture above you can see that if mode
'val' is before 'train', then the number of correct images is 4277. However, when the mode 'val' is after 'train', then the number of correct images is 4283. As for the training set, they are same.