Hi @mrshenli,
After I
export GLOO_SOCKET_IFNAME=nonexist
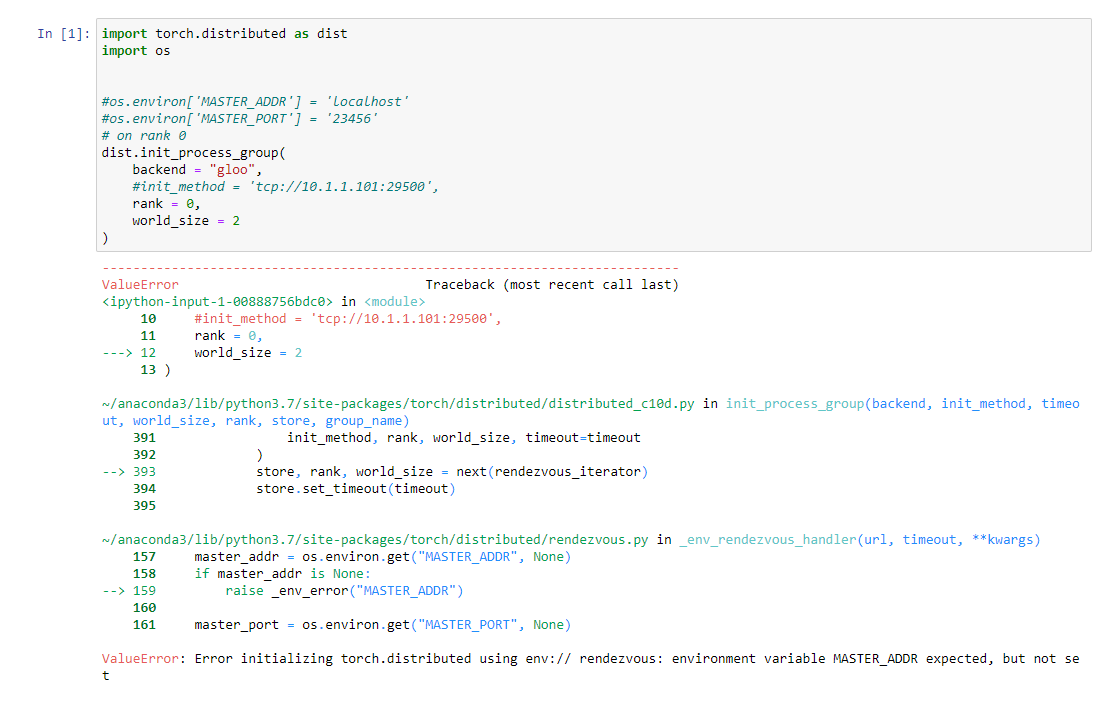
This is the error I got. Does it seem that it bypasses the nonexist and look at some others? If I add the master_address then it will just hang there for the second rank to come in.
Thanks,