HI all.
I have strange problem: I’m trying to run 2 tasks on 2 machines via following
trivial script:
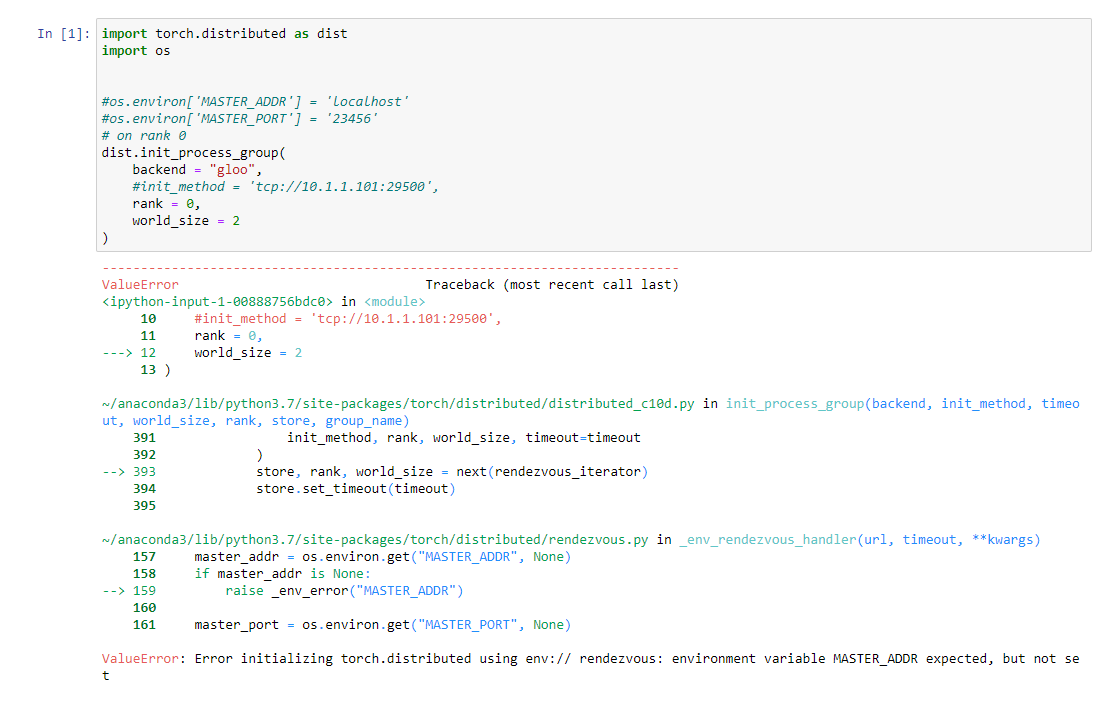
dist.init_process_group(backend = "gloo",init_method = 'tcp://192.168.0.1:29500',rank = irank,world_size = iwsize)
arg = None
if(dist.get_rank()==0):
arg = Dist_Trainer()
run(dist.get_rank(),dist.get_world_size(),arg)
When I run them on one machine, all works fine.
But when I start process with rank = 0 on one machine,
and process with rank = 1 on another machine,
process with rank = 0 fails with the following output:
python train_dist.py 0 2
RANK: 0 wsize: 2
terminate called after throwing an instance of ‘gloo::IoException’ what(): [/opt/conda/conda-bld/pytorch_1544176307774/work/third_party/gloo/gloo/transport/tcp/pair.cc:724] connect [127.0.0.1]:45965: Connection refused
This happens only when I start process with rank=1. If I don’t started it,
process with rank =0 is waiting for connection.
i.e.,I assume that tcp connection happens, but then process with rank = 0
tries to work with 127.0.0.1?
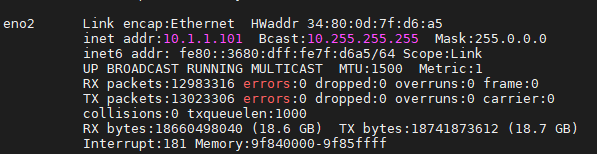
Upd: I tried setting export GLOO_SOCKET_IFNAME=enp2s0,
the problem still remains.