Hi @mrshenli,
This is different from the RPC problem. Back then I was using Google Cloud VMs. The torch.distributed and RPC worked fine there.
However, just recently we built up new servers with GPU in our lab and connect them using an electrical packet switch. They can ping each other using the internal IP. For me now it is 10.1.1.101 for rank 0 and 10.1.1.102 for rank 1. So I run the following:
import torch.distributed as dist
# on rank 0
dist.init_process_group(
backend = "gloo",
init_method = 'tcp://10.1.1.101:29500',
rank = 0,
world_size = 2
)
import torch.distributed as dist
# on rank 1
dist.init_process_group(
backend = "gloo",
init_method = 'tcp://10.1.1.101:29500',
rank = 1,
world_size = 2
)
However, it failed with
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-1-532df564c254> in <module>
6 init_method = 'tcp://10.1.1.101:29500',
7 rank = 1,
----> 8 world_size = 2
9 )
~/anaconda3/lib/python3.7/site-packages/torch/distributed/distributed_c10d.py in init_process_group(backend, init_method, timeout, world_size, rank, store, group_name)
401 store,
402 group_name=group_name,
--> 403 timeout=timeout)
404
405 _pg_group_ranks[_default_pg] = {i: i for i in range(_default_pg.size())}
~/anaconda3/lib/python3.7/site-packages/torch/distributed/distributed_c10d.py in _new_process_group_helper(world_size, rank, group_ranks, backend, store, group_name, timeout)
469 rank,
470 world_size,
--> 471 timeout=timeout)
472 _pg_map[pg] = (Backend.GLOO, store)
473 _pg_names[pg] = group_name
RuntimeError: [/opt/conda/conda-bld/pytorch_1587428398394/work/third_party/gloo/gloo/transport/tcp/pair.cc:769] connect [127.0.0.1]:31662: Connection refused
Which I guess is the same problem for @Oleg_Ivanov too. In terms of
export GLOO_SOCKET_IFNAME=eno2
Should I simply do it in any terminal? eno2 is my NIC.
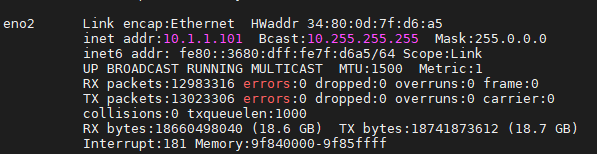
Please let me know if you have any thoughts. Thank you very much for your help!