Hello, everyone. I am new to Pytorch and recently I learned to implement a CNN training for semantic segmentation. However I meet some strange GPU memory behavior and can not find the reason.
[1] Different memory consumption on different GPU platform
I have 2 GPU platforms for model training.
Same code, same ResNet50 CNN, same training data, same batchsize = 1 platform 1 [GTX 970 (4G), cuda-8.0, cudnn-5.0, Nvidia Driver-375.26] consume 3101M GPU memory platform 2 [GTX TITAN X (12G), cuda-7.5, cudnn-5.0, Nvidia Driver-352.30] consume 1792M GPU memory
There is a big difference in GPU memory consumption, and I can not find the reason. Can anyone give some help?
[2] Strange out of memory error when training
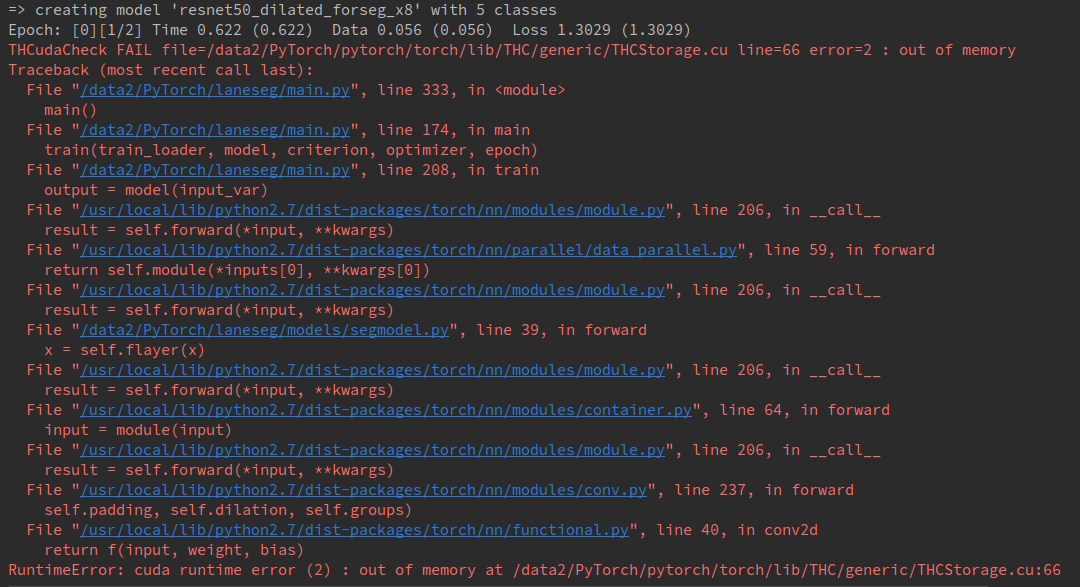
On platform 1, when there is only one image/label pair in the training data list, the model is trained normally for 100 epochs.(batchsize = 1. thus 1 iteration per epoch) However, if I repeat the training pair thus there are 2 image/label pairs in the training data list, the training break down at the second iteration with out of memory error showed in the following image (batchsize = 1. thus 2 iteration per epoch). This error does not occur on the platform 2. So strange.
Thanks very much, @smthThat is exactly the reason for different memory consumption on 2 platforms. (cudnn)
On platform 1, the torch.backends.cudnn.enabled did not work, even it was set true. The memory consumption is still 3101M. However on platform 2, 1792M if torch.backends.cudnn.enabled=true, and 3100M if torch.backends.cudnn.enabled = false. So there are maybe something wrong with cudnn on platform 1.
And what do you think of the second problem? The strange out of memory behavior. cudnn.enabled and cudnn.benchmark seems not the reason.
I meet a similar problem.
Which is caused by torch.backends.cudnn.benchmark = True, when change to torch.backends.cudnn.enabled = True, everything is ok.
more error info
Traceback (most recent call last):
File “main_test.py”, line 14, in
t.test()
File “code/test.py”, line 64, in test
output = self.model(input)
File “/home/.local/lib/python2.7/site-packages/torch/nn/modules/module.py”, line 224, in call
result = self.forward(*input, **kwargs)
File “code/model/model.py”, line 46, in forward
x = self.headConv(x)
File “/home/.local/lib/python2.7/site-packages/torch/nn/modules/module.py”, line 224, in call
result = self.forward(*input, **kwargs)
File “/home/.local/lib/python2.7/site-packages/torch/nn/modules/conv.py”, line 254, in forward
self.padding, self.dilation, self.groups)
File “/home/.local/lib/python2.7/site-packages/torch/nn/functional.py”, line 52, in conv2d
return f(input, weight, bias)
RuntimeError: CUDNN_STATUS_INTERNAL_ERROR
It seems that error occurs in Conv Module. If it happens only when cudnn is enabled, there may be something wrong in cudnn library. Wrong version or something else.
Sorry I can not figure out the reason exactly.
my pytorch version is 0.2.0, install using pip command follow official guide. I also suspect it is environment problem. but I don’t know how to resolve it.
Sorry, I usually build pytorch from source and do not know what’s wrong with the pytorch you installed.
Maybe you can check if your pytorch link all libraries correctly.
cd /usr/local/lib/python2.7/dist-packages/torch
ldd _C.so
Enter the installation path and check the library link.
It looks like all libraries are linked correctly. Maybe you can create a new topic in pytorch forums to get help from others. I am so sorry that I can not figure out the reason for this error.
I am facing some similar issue where GPU memory consumed by the network on one platform one is 15 GB and platform 2 is 11 GB.
Platform1: NVIDIA Tesla P100 GPU 16GB, Cuda 9.1.85, Pytorch 0.4.0
Platform2: GTX 1080 GPU 12GB, Cuda 8.0.61 , Pytorch 0.4.0
Both print cudnn version to be 7102 inside python by torch,backends.cuda.version()
Strangely, when i turn torch.backends.cudnn.enabled=False in platform1 my gpu consumption becomes 11 GB. But i think gpu consumption should be lesser using cudnn as suggested in above answers. Can anyone help what could be the problem?