Hi All,
Thank you for your time. I will try to clarify my questions, with text and figures.
Problem Background
-
I am training and reproducing a Generative Adversarial Net (GAN) with pretrained weights (repo link: https://github.com/MiaoyunZhao/GANmemory_LifelongLearning).
-
With BatchSize=16 and GPU=1, without DP and DDP (i.e., total Batchsize=16), I can achieve the expected performance (in FID score, lower is better), see figure below (green line).
-
With BatchSize=2 per GPU and GPU=8, with DP (i.e., total Batchsize=16), I can also achieve similar performance, see figure below (brown line, pls note the index of iteration)
-
With BatchSize=2 per GPU and GPU=8, with DDP (i.e., total Batchsize=16, purple line), the performance is poor.
However, if I increase the BatchSize, e.g., BatchSize=8 per GPU and GPU=8, with DDP (i.e., total Batchsize=64, pink line), or BatchSize=16 per GPU and GPU=8, with DDP (i.e., total Batchsize=128, orange line), the performance will be better and better and gets close to the BatchSize=16 on a single GPU, or BatchSize=2 on 8 GPUs with DP. See figure below.
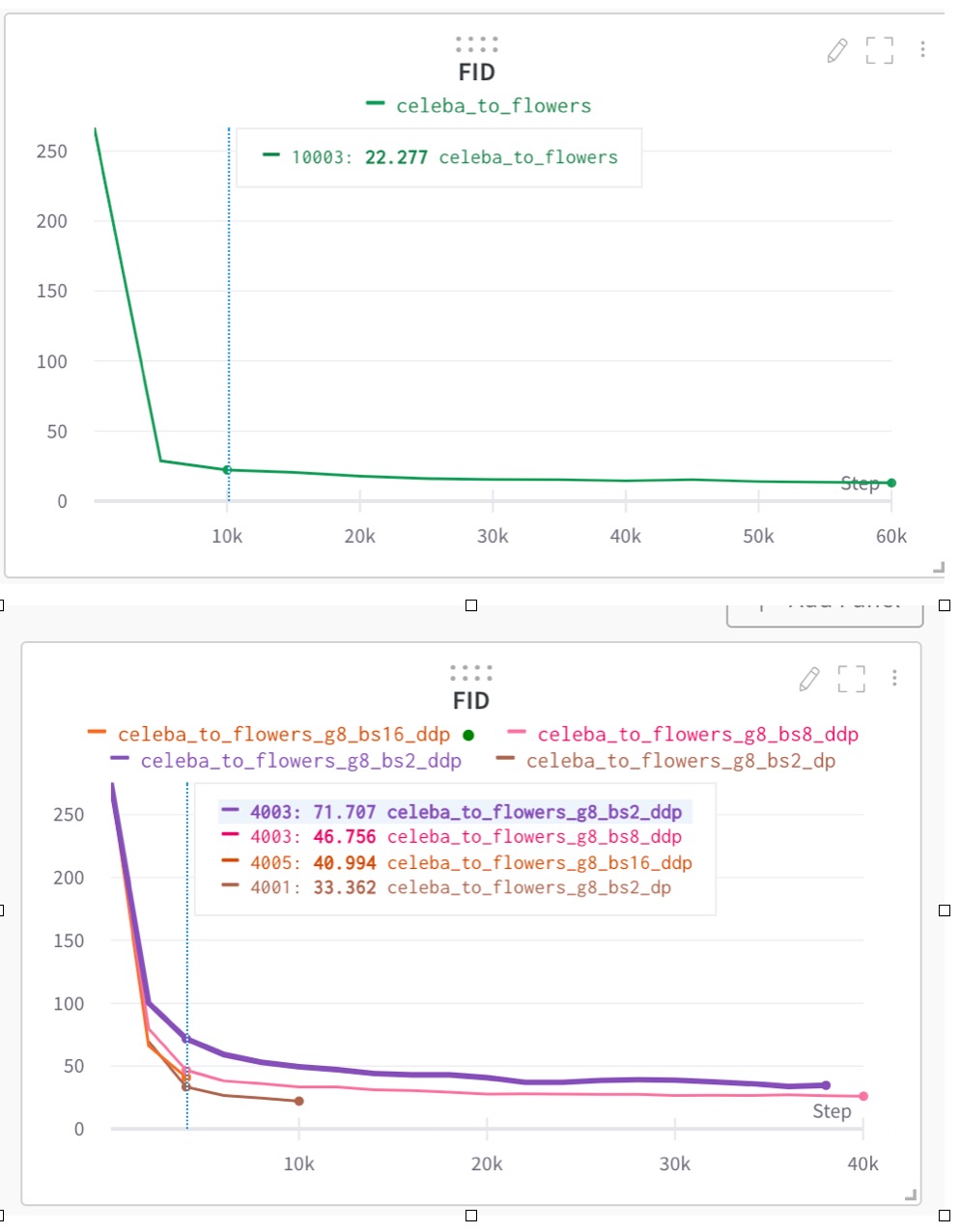
-
Note: There are no BatchNorm Layers in my model. For all settings, I did not change all other hyper-parameters, e.g., learning rate.
-
Library Version: Python 3.6.9, Pytorch 1.7.0
My question is: How can I get the same performance between:
a) BatchSize 16 and GPU=1 (i.e., total Batchsize=16), no DP and no DDP.
b) BatchSize 2 per GPU and GPU=8 (i.e., total Batchsize=16), with DDP.
Here is my code snippet:
import torch
from torch import nn
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.nn.parallel import DataParallel as DP
from distributed import (
get_rank,
synchronize,
reduce_loss_dict,
reduce_sum,
get_world_size,
)
def seed_torch(seed=1029):
"""
set the random seeds
"""
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # for multi-GPU
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
def data_sampler(dataset, shuffle, distributed):
if distributed:
return torch.utils.data.distributed.DistributedSampler(dataset, shuffle=shuffle)
if shuffle:
return torch.utils.data.RandomSampler(dataset)
else:
return torch.utils.data.SequentialSampler(dataset)
def sample_data(loader):
while True:
for batch in loader:
yield batch
def train(args, train_loader, generator, discriminator, generator_ema, g_optimizer, d_optimizer, trainer, evaluator, device):
for idx in pbar:
# Step 1. Sample a mini-batch of data
x_real, y = next(train_loader)
x_real, y = x_real.to(device), y.to(device)
y.clamp_(None, nlabels-1)
# Step 2. Update G and D
z = zdist.sample((int(args.batch_size),))
# Generators updates
g_loss, x_fake, _ = trainer.generator_trainstep(y, z)
# Discriminator updates
d_loss, reg = trainer.discriminator_trainstep(x_real, y, x_fake)
# Step 3. Update statistics
g_scheduler.step()
d_scheduler.step()
# Step 4. Optionally record and data and checkpoints
with torch.no_grad():
# Evaluate during training (FID score, etc,)
if args.eval_in_training and ((i) % args.eval_in_training_freq) == 0:
if get_rank() == 0:
inception_mean, inception_std, fid = evaluator.compute_inception_score()
if wandb and args.wandb:
wandb.log(
{
"IS mean": inception_mean,
"IS std" : inception_std,
"FID" : fid,
}
)
if __name__ == "__main__":
device = "cuda"
seed_torch(999)
parser = argparse.ArgumentParser(description='gan_memory trainer')
parser.add_argument("--exp", type=str, default='gan_memory')
parser.add_argument("--run_name", type=str, default='test')
parser.add_argument("--data_path", type=str, default='Flowers')
parser.add_argument("--config_path", type=str, default='celeba_to_flowers.yaml')
parser.add_argument("--iter", type=int, default=60000)
parser.add_argument("--start_iter", type=int, default=0)
parser.add_argument("--lr", type=float, default=0.0001)
parser.add_argument("--batch_size", type=int, default=16, help='batch size on each gpu')
parser.add_argument("--size", type=int, default=256, help="size of the img, must be square")
parser.add_argument("--noise", default='None', help='if load a fixed noise (.pt)')
parser.add_argument("--local_rank", type=int, default=0, help="local rank for distributed training")
parser.add_argument("--n_gpus", type=int, default=8)
parser.add_argument("--n_sample_train", type=int, default=10, help="# of training samples")
parser.add_argument("--n_sample_test", type=int, default=10000)
parser.add_argument("--n_sample_store", type=int, default=25, help="# of generated images using intermediate models")
parser.add_argument("--ckpt_source", type=str, default='source_celeba.pt', help="pretrained model")
parser.add_argument("--ema", action="store_false")
parser.add_argument("--wandb", action="store_true", help="use weights and biases logging")
parser.add_argument("--debug_mode", default=False)
parser.add_argument("--store_samples", action="store_true")
parser.add_argument("--store_checkpoints", action="store_true")
parser.add_argument("--eval_in_training", action="store_true")
parser.add_argument("--samples_freq", type=int, default=5000)
parser.add_argument("--checkpoints_freq", type=int, default=5000)
parser.add_argument("--eval_in_training_freq", type=int, default=5000)
args = parser.parse_args()
# Step 1. Pre-experiment setups
# init DDP setups
if not args.debug_mode:
args.n_gpus = int(os.environ["WORLD_SIZE"]) if "WORLD_SIZE" in os.environ else 1
args.distributed = args.n_gpus > 1
if args.distributed:
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend="nccl", init_method="env://")
synchronize()
else:
pass
# Step 2. Construct Dataset and DataLoader (now with DDP)
train_dataset, nlabels = get_dataset(
name= config['data']['type'],
data_dir= args.data_path,
size= args.size,
)
test_dataset, _ = get_dataset(
name=config['data']['type'],
data_dir=args.data_path,
size=128,
)
# train_sampler = data_sampler(train_dataset, shuffle=True, distributed=False)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=int(args.batch_size), # batch size per device (with DDP)
num_workers=0,
# shuffle=True,
pin_memory=True, sampler=data_sampler(train_dataset, shuffle=True, distributed=args.distributed), drop_last=True
)
train_loader = sample_data(train_loader)
# test_sampler = data_sampler(test_dataset, shuffle=True, distributed=False)
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size=int(args.batch_size), # batch size per device (with DDP)
num_workers=0,
# shuffle=True,
pin_memory=True, sampler=data_sampler(test_dataset, shuffle=True, distributed=args.distributed), drop_last=True
)
test_loader = sample_data(test_loader)
# Number of labels
sample_nlabels = config['training']['sample_nlabels']
nlabels = min(nlabels, config['data']['nlabels'])
sample_nlabels = min(nlabels, sample_nlabels)
# Step 3. Create models and Load pretrained weights
generator, discriminator = build_models(config)
if args.ckpt_source is not None:
ckpt_dict = torch.load(load_dir + args.ckpt_source, map_location=torch.device('cpu'))
generator = load_weights_without_module(generator, ckpt_dict['generator'])
discriminator = load_weights_without_module(discriminator, ckpt_dict['discriminator'])
else:
if get_rank() == 0:
print('Pretrained Model not found, start training from scratch.')
g_optimizer, d_optimizer = build_optimizers(generator, discriminator, config)
# --- --- --- --- Construct DDP Model --- --- --- --- #
# generator, discriminator = generator.to(device), discriminator.to(device) # by default, no DDP
generator = generator.to(device)
discriminator = discriminator.to(device)
if args.distributed:
generator = nn.parallel.DistributedDataParallel(
generator,
device_ids=[args.local_rank],
output_device=args.local_rank,
broadcast_buffers=False,
)
discriminator = nn.parallel.DistributedDataParallel(
discriminator,
device_ids=[args.local_rank],
output_device=args.local_rank,
broadcast_buffers=False,
)
# --- --- --- --- --- --- --- --- --- --- --- --- --- #
# Learning rate anneling
g_scheduler = build_lr_scheduler(g_optimizer, config, last_epoch=-1)
d_scheduler = build_lr_scheduler(d_optimizer, config, last_epoch=-1)
# Prepare g_ema
if args.ema:
generator_ema = copy.deepcopy(generator)
checkpoint_io.register_modules(generator_ema=generator_ema)
else:
generator_ema = generator
# Step 4. Init input data and training miscs
ydist = get_ydist(nlabels, device=device)
zdist = get_zdist(config['z_dist']['type'], args.size, device=device)
x_real, ytest = utils.get_nsamples(train_loader, args.n_sample_store)
ytest.clamp_(None, nlabels-1)
ytest = ytest.to(device)
ztest = zdist.sample((args.n_sample_store,)).to(device)
x_real_FID, _ = utils.get_nsamples(test_loader, args.n_sample_test)
evaluator = Evaluator(generator_ema, zdist, ydist,
batch_size=int(args.batch_size),
device=device,
fid_real_samples=x_real_FID,
inception_nsamples=args.n_sample_test,
fid_sample_size=args.n_sample_test)
# Step 5. Start the training loop
trainer = Trainer(
generator, discriminator, g_optimizer, d_optimizer,
gan_type =config['training']['gan_type'],
reg_type =config['training']['reg_type'],
reg_param=config['training']['reg_param'])
train(args, train_loader, generator, discriminator, generator_ema,
g_optimizer, d_optimizer, trainer, evaluator, device)