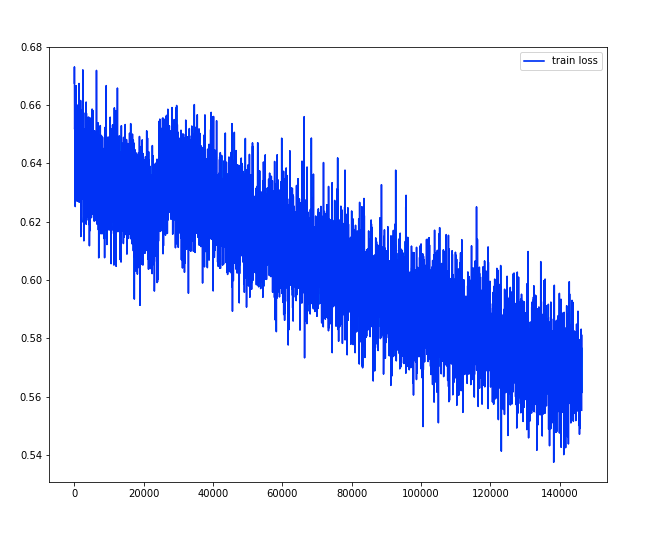
I have a quite odd problem with my loss function during training. I have a function train(n_epochs, batch_size) that performs training with a certain number of epochs and a certain batch_size. The problem is that when i restart training, the loss suddenly increases.
For example, in the following figure we can see that the loss suddenly increases around 30000 iterations, that corresponds to a second training I started. At first, I thought this was due to the running means on the batch normalization, but I reset them and that does not seem to change anything.
Could be your learning rate? If it decays based on the number of iterations, make sure that when training restarts the number of iterations is correct.
Yes, it could, i’m using anealing for decreasing it, but anyway I’m restarting with the same learning rate as the end of the last training, but thanks!
Do you shuffle your training data? It might be bad samples at the beginning of you dataset which might effect the training restart. Do you observe similar pattern if you restart multiple times?
Yes, I do shuffle the data, but with replacement… I’m doing a word2vec kind of thing, so I drawing with probabilities that varies with the number of times a certain word appears in my dataset. So the distribution must always be the same.
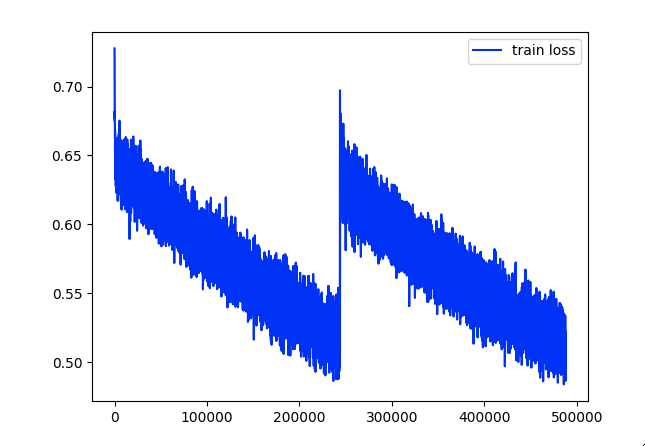
I’ve just run two trainings, saving all the parameters from the optimizer (the state dict and learning rate) and i got this:
Without knowing what exactly your code does, I can think of the following other reason:
If you are using Adam optimizer, your learning rates that you set from your script might mess things up. Because Adam inherently has a square root decay of learning rate. So at the restart of training, even though reloading the optimizer state dict will resume training, I am guessing you again set you annealed learning rate. This might cause your problem.
I thought about that (that the problem was coming from adam decay of the learning rate) and changed the optimizer for SGD and still got the same result
I see. I still feel some problem with the data. Maybe you can try on an official example and see if it’s some problem with pytorch itself. If not then you can probably debug you data.