I found the similar issue #4932, but it didn’t help.
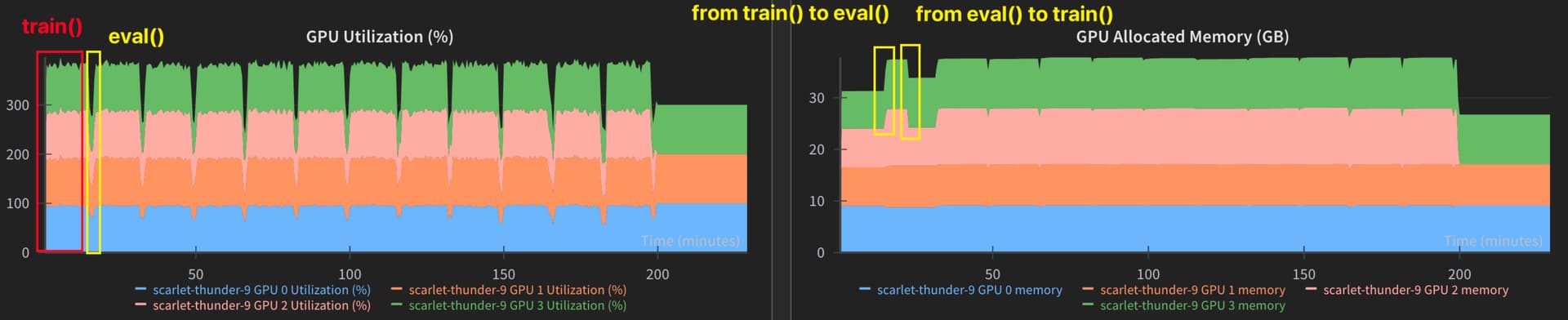
I did the train() and eval() in the same epoch. I found a strange memory increase during eval(), but I used torch.no_grad() and eval(). The code and GPU performance are listed below.
for epoch in range(start_epoch, args.epochs):
# setting
if args.distributed:
data_loader_train.sampler.set_epoch(epoch)
# train
batch_loss = []
model.train()
start_time = time.time()
total_step = len(data_loader_train)
for ii, (src, tgt) in enumerate(data_loader_train):
# print(src.shape,tgt.shape)
src = src.to(device)
tgt = tgt.to(device)
outputs = model(src, tgt)
optimizer.zero_grad()
# nb cross entropy require input as (N,Class_num, d...) and target (N, d...)
loss = criterion(outputs.permute(0, 2, 1), tgt)
loss.backward()
optimizer.step()
batch_loss.append(loss.item())
torch.cuda.empty_cache()
continue_training = evaluate(args, model, data_loader_val,epoch, num_epochs, num_bad_epochs,best_loss, device, criterion)
@torch.no_grad()
def evaluate(args, model, data_loader_val,epoch, num_epochs, num_bad_epochs,best_loss, device, criterion):
model.eval()
test_loss = 0
for src, tgt in data_loader_val:
src = src.to(device)
tgt = tgt.to(device)
# bug in the third batch, once the output is done, the VRAM changed from 4G to 8G
outputs = model(src, tgt)
loss = criterion(outputs.permute(0, 2, 1), tgt)
test_loss += loss.item()
avg_test_loss = test_loss / len(data_loader_val)
print(f'Epoch {epoch+1}/{num_epochs}, Test Loss: {avg_test_loss}')
# nb early stopping is implemented
if avg_test_loss < args.loss_threshold:
print(f"Test loss {avg_test_loss} is below the threshold {args.loss_threshold}.")
print("Early stopping triggered due to reaching loss threshold.")
return False
if avg_test_loss < best_loss:
best_loss = avg_test_loss
num_bad_epochs = 0
else:
num_bad_epochs += 1
if num_bad_epochs >= args.patience:
print("Early stopping triggered")
return False
return True
Thank you for any hint.