Attached is the profile summary of a pytorch network training session (2 epochs):
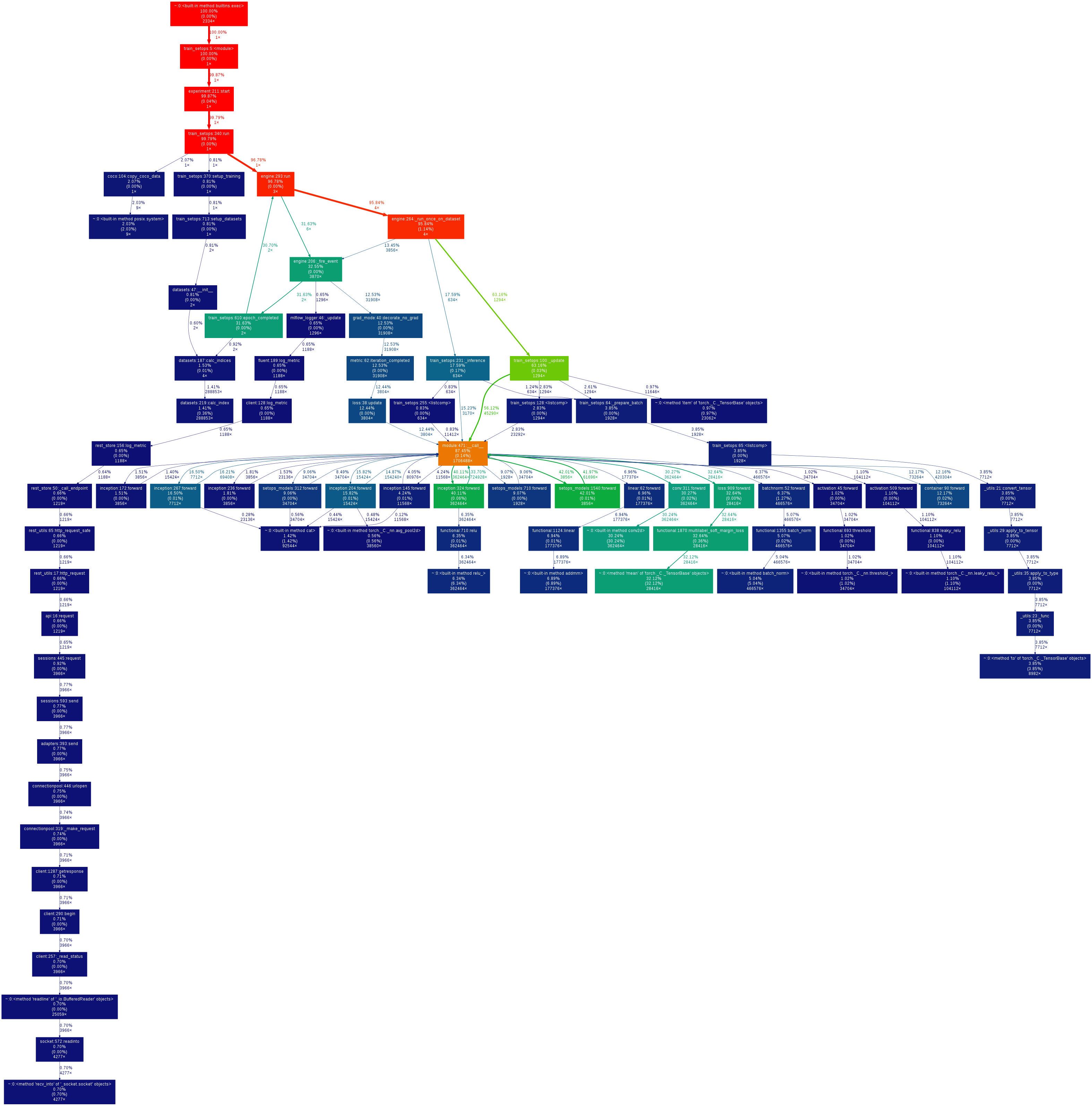
As can be seen, a large part of the time (32%) is spent in the ‘mean’ method of the ‘multilabel_soft_margin_loss’. The networks that I am training have several layers of large (1024) FC layers, so I would expect that most of the time would be spent in the FC layers not in the ‘mean’ method. All tensors reside on the GPU.
The reason I profiled my code, was that I it doesn’t achive full utilization of the GPU (It fluctuates between 60-90% utilization).
Will appreciate any advice on how to improve the performance of the code.
Thanks.