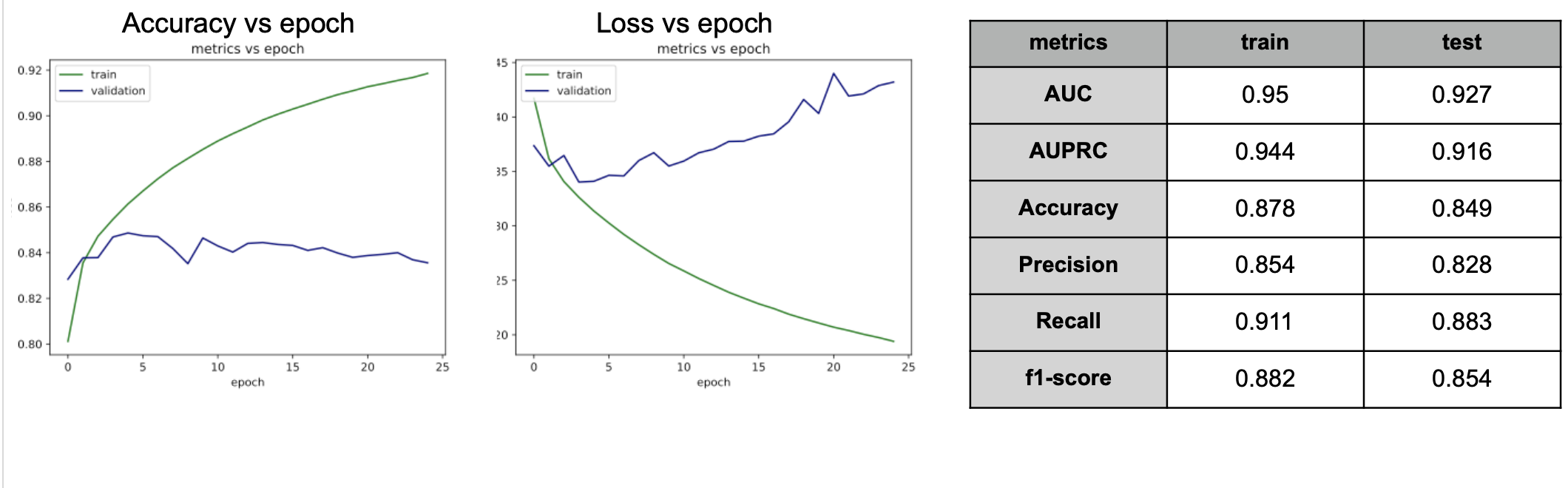
I have a balanced dataset - - positive:negative = 1:1. I have been record the accuracy and loss of train and validation for each epoch, selected the best model based on validation accuracy, then plot the roc curve on train and test set. The final AUC doesn’t look bad, but the metrics vs epoch during training is strange. The two question I have is:
- the first epoch have train accuracy as 0.8. I used pytorch’s default initiation and tried giving a uniformed distribution to sample the weights from. Both of them have larger than 0.75 starting accuracy on the training data. Is this normal?
- The validation performance reach its best at the 4th epoch, and it’s not very different from the first couple epochs. This means the model does not improved a lot after initiation. Does this mean the data set is just very hard to be trained?
model
class Net(torch.nn.Module):
def __init__(self, n_class):
super(Net, self).__init__()
self.n_class = n_class
self.Conv1 = nn.Conv1d(in_channels=4,
out_channels=320,
kernel_size=30)
self.Conv2 = nn.Conv1d(in_channels=320,
out_channels=160,
kernel_size=12)
self.Maxpool = nn.MaxPool1d(kernel_size=13,
stride=11)
self.Drop1 = nn.Dropout(0.1)
self.BiLSTM = nn.LSTM(input_size=87, hidden_size=40,
num_layers=2,
batch_first=True,
dropout=0.4,
bidirectional=True)
self.Linear1 = nn.Linear(12800, 256)
self.Linear2 = nn.Linear(256, 256)
self.Linear3 = nn.Linear(256, self.n_class)
self.Drop2 = nn.Dropout(0.2)
def forward(self, input):
x = self.Conv1(input)
x = F.relu(x)
x = self.Conv2(x)
x = F.relu(x)
x = self.Maxpool(x)
x = self.Drop2(x)
x, _ = self.BiLSTM(x)
#print(f'output shape from LSTM layer: {x.shape}')
# x = self.attention(x,x,x)
x = torch.flatten(x, 1)
#print(f'output shape from flatten layer: {x.shape}')
x = self.Linear1(x)
x = F.relu(x)
x = self.Linear2(x)
x = F.relu(x)
x = self.Linear3(x)
x = torch.sigmoid(x)
return x
def __str__(self):
"""
Just like any class in Python, you can also define custom method on PyTorch modules
"""
summary(Complex_DanQ, (4, 1000))
Code to train the model
def train(self):
""" train """
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = self._model.to(device)
train_loss_hist = []
eval_loss_hist = []
train_acc_hist = []
eval_acc_hist = []
with open(os.path.join(self.plot_path, "train_vali_record.txt"), 'w') as file:
file.write("Epoch \t Data \t Loss \t Acc \n")
file.close()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
if self.weight == "NA":
criterion = nn.BCELoss().to(device)
else:
criterion = nn.BCELoss(weight = torch.tensor([self.weight])).to(device) ## for cluster 1(none dominant)
optimizer = torch.optim.Adam(model.parameters(), lr=self._learning_rate, weight_decay=self._weight_decay)
train_loader = torch.utils.data.DataLoader(self.train_data, batch_size=self._batch_size, shuffle=True)
eval_loader = torch.utils.data.DataLoader(self.eval_data, batch_size=self._batch_size, shuffle=True)
#model.apply(self._weights_init_uniform_rule) # TODO Uniform Initialization added on 0303
for epoch in range(self._num_epochs):
print('Epoch {}/{}'.format(epoch, self._num_epochs - 1))
print('-' * 10)
# Train
train_loss = 0.0
train_acc = 0.0
model.train() # set to train mode, use dropout and batchnorm ##
for X, y in tqdm(train_loader):
X = X.to(device)
y = y.to(device)
# Forward pass: Compute predicted y by passing x to the model
y_pred_prob = model(X.float()) # predicted value
#_, preds = torch.max(y_pred, 1) # TODO understand this line
# Compute and print loss
loss = criterion(y_pred_prob.float(), y.float())
# Backward and optimize
# Zero gradients, perform a backward pass, and update the weights.
optimizer.zero_grad() # clears old gradients from the last step
loss.backward() # for each parameter, calculate d(loss)/d(weight)
optimizer.step() # update weights, causes the optimizer to take a step based on the gradients of the parameters
# statistics
y_pred = (y_pred_prob > 0.5).float() ## 0/1
train_loss += loss.item() * X.size(0) #loss.item() has be reducted by batch size
train_acc += torch.sum(y_pred == y)
if epoch % 1 == 0:
train_loss = train_loss/len(train_loader.dataset)
train_acc = train_acc.double() / len(train_loader.dataset)
print('Epoch {} {} Loss: {:.4f} Acc: {:.4f}'.format(epoch, 'train', train_loss, train_acc))
with open(os.path.join(self.plot_path, "train_vali_record.txt"), 'a') as file:
file.write("{} \t {} \t {:.4f} \t {:.4f} \n".format(epoch, 'train', train_loss, train_acc))
file.close()
train_loss_hist.append(train_loss)
train_acc_hist.append(train_acc)
# Evaluation
eval_loss = 0
eval_acc = 0
model.eval() # added to not use drop out and batch norm for validation
with torch.no_grad(): # disable gradiant calculation
for X, y in tqdm(eval_loader):
optimizer.zero_grad() # make sure training and eval has minimum diff
X, y = X.to(device), y.to(device)
y_pred_prob = model(X.float()) #TODO check whether the weights updated here since optimizer.step()
eva_loss = criterion(y_pred_prob.float(), y.float())
y_pred = (y_pred_prob > 0.5).float() ## 0/1
# statistics
eval_loss += eva_loss.item() * X.size(0)
eval_acc += torch.sum(y_pred == y)
eval_loss = eval_loss / len(eval_loader.dataset)
eval_acc = eval_acc.double() / len(eval_loader.dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format("validation", eval_loss, eval_acc))
with open(os.path.join(self.plot_path, "train_vali_record.txt"), 'a') as file:
file.write("{} \t {} \t{:.4f} \t {:.4f} \n".format(epoch, 'validation', eval_loss, eval_acc))
file.close()
eval_loss_hist.append(eval_loss)
eval_acc_hist.append(eval_acc)
if eval_acc > best_acc:
best_acc = eval_acc
best_model_wts = copy.deepcopy(model.state_dict())
# load best model weights
model.load_state_dict(best_model_wts)
torch.save(model.state_dict(), self._model_path)
self._plot_metrics(train_loss_hist, eval_loss_hist, "loss_history.pdf")
self._plot_metrics(train_acc_hist, eval_acc_hist, "acc_history.pdf")