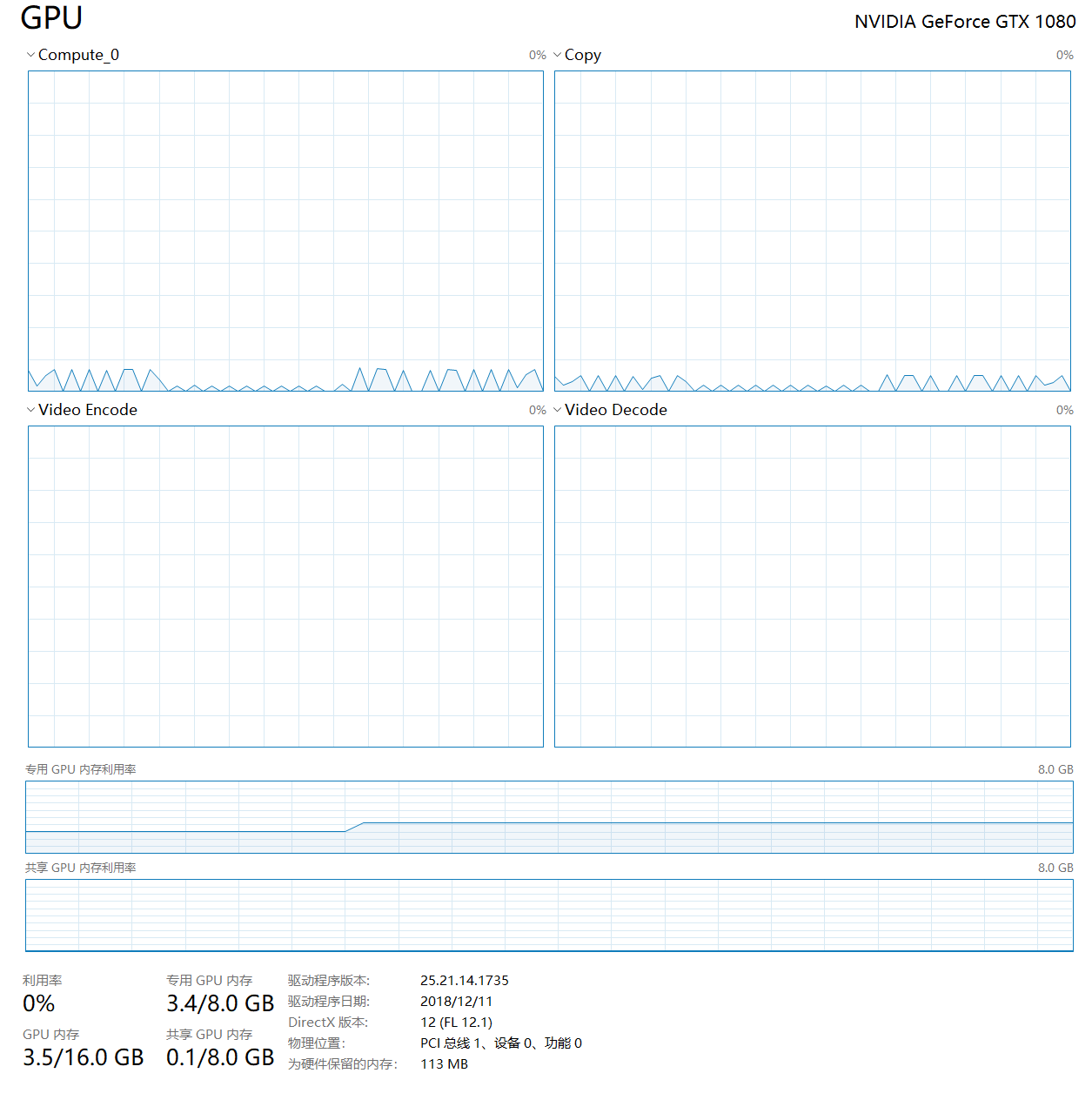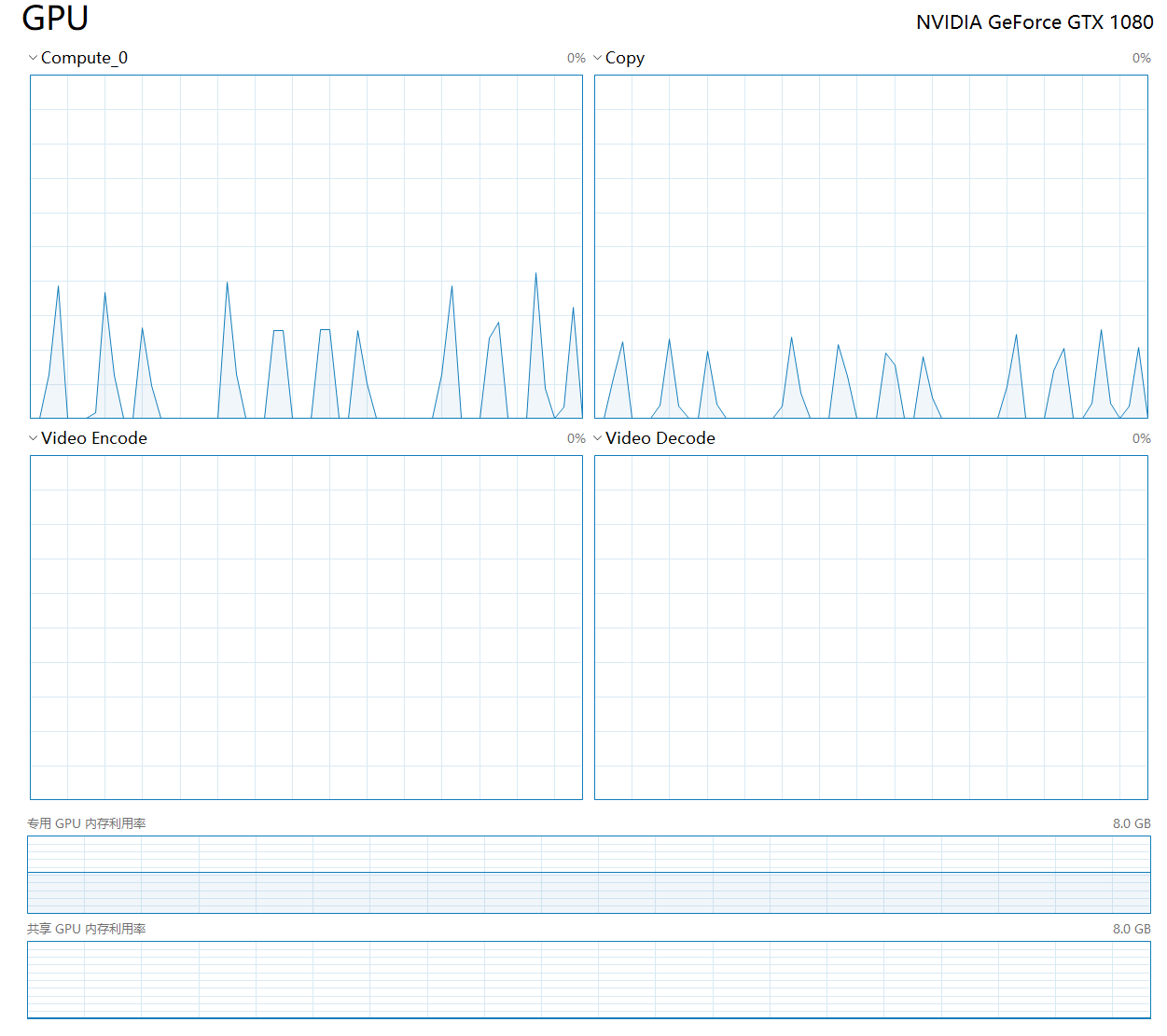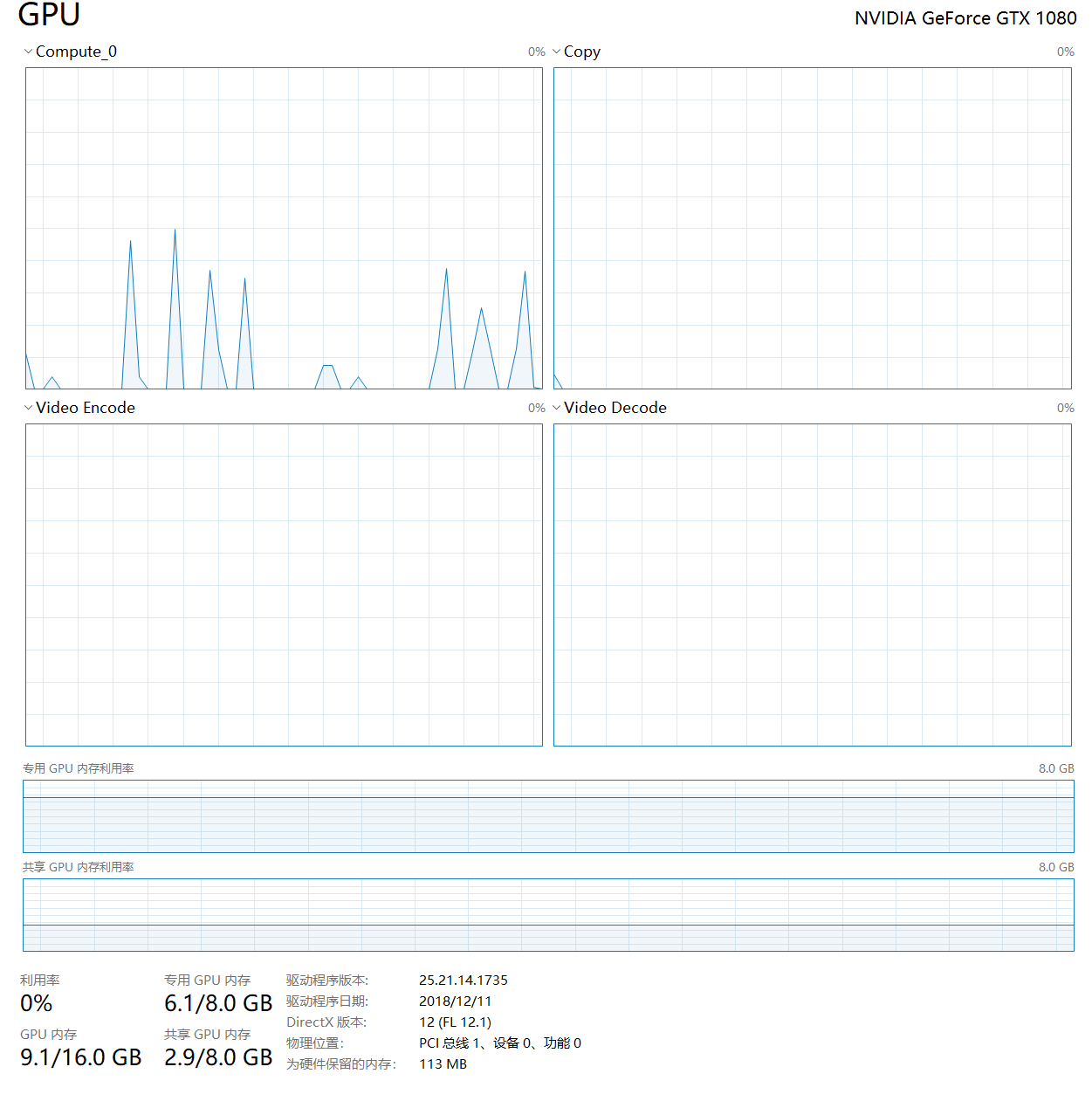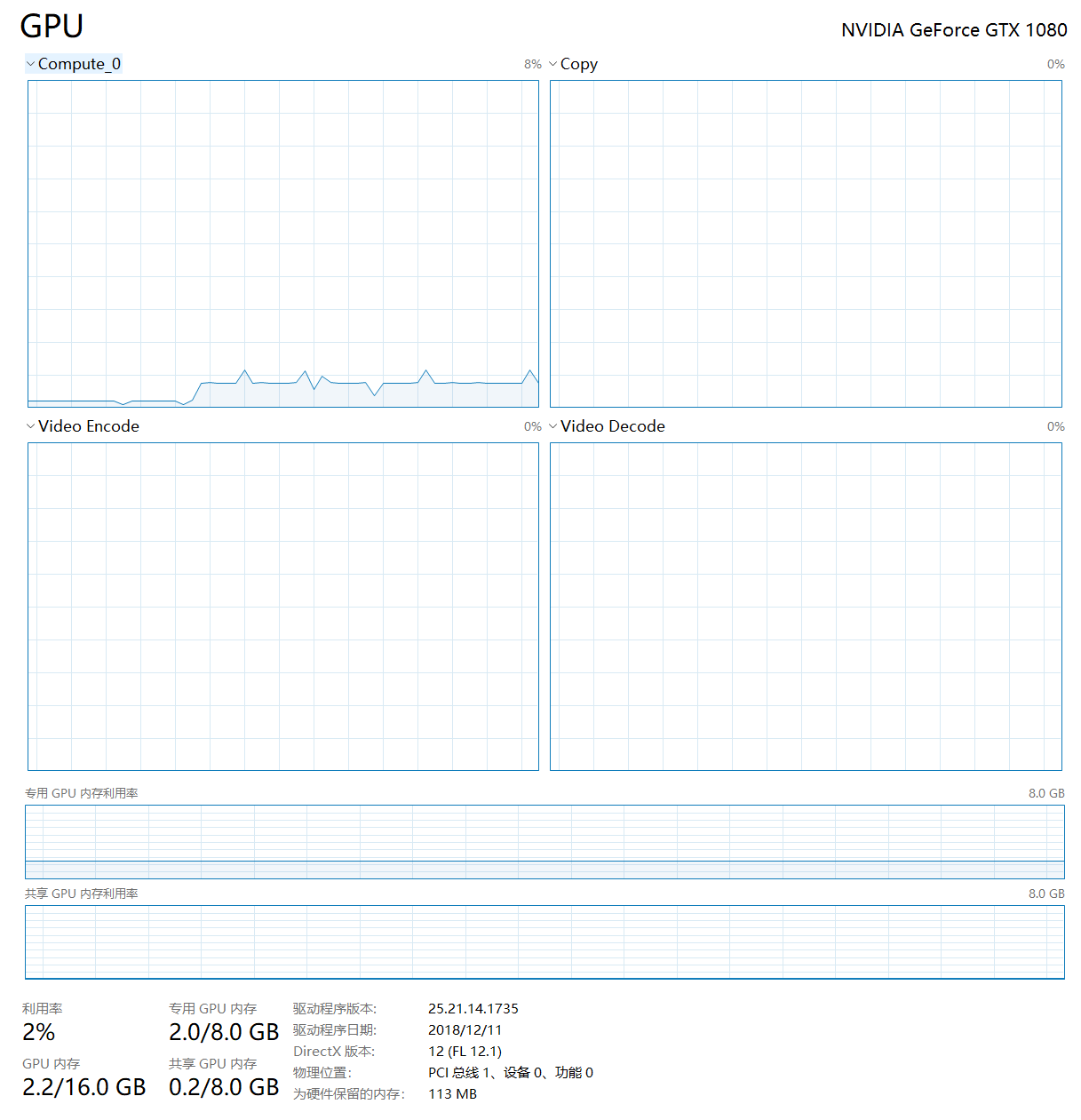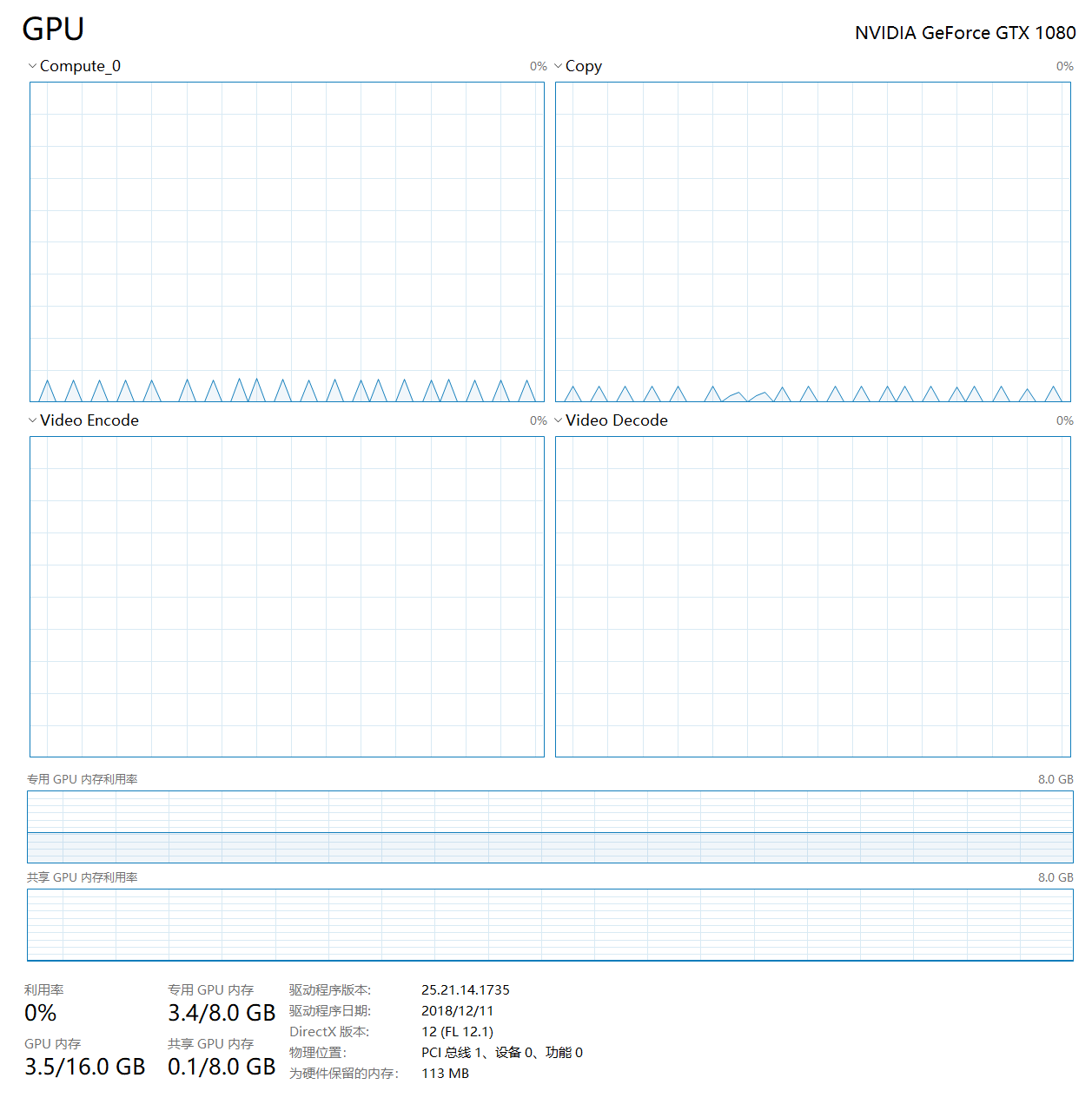
Is it normal? What might have led to this strange shape of utilization?
The training code is as follows:
torch.cuda.empty_cache()
# Train the detector with given data:
import time
import torch.optim as optim
# specify loss function (categorical cross-entropy)
criterion = torch.nn.CrossEntropyLoss()
# specify optimizer (stochastic gradient descent) and learning rate = 0.001
optimizer = optim.Adam(hfdetector.parameters(), lr=0.0001)
start = time.time()
print(f'Training started at {time.ctime()}')
# number of epochs to train the model
n_epochs = 1000 # you may increase this number to train a final model
stop_criterion = 50
valid_loss_min = np.Inf # track change in validation loss
early_stop_count = 0
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs
hfdetector = torch.nn.DataParallel(hfdetector)
for epoch in range(1, n_epochs+1):
# keep track of training and validation loss
train_loss = 0.0
valid_loss = 0.0
# early stop mechanism:
if early_stop_count >= stop_criterion:
print(f'Validation loss stops decresing for {stop_criterion} epochs, early stop triggered.')
break
###################
# train the model #
###################
hfdetector.train()
try:
for data, target in train_loader:
# move tensors to GPU if CUDA is available
if torch.cuda.is_available():
data, target = data.cuda(), target.cuda()
# clear the gradients of all optimized variables
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
output = hfdetector(data)
# calculate the batch loss
loss = criterion(output, target)
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# update training loss
train_loss += loss.item() * data.size(0)
except Exception as e:
print(f'Bad image skipped.')
######################
# validate the model #
######################
hfdetector.eval()
try:
for data, target in valid_loader:
# move tensors to GPU if CUDA is available
if torch.cuda.is_available():
data, target = data.cuda(), target.cuda()
# forward pass: compute predicted outputs by passing inputs to the model
output = hfdetector(data)
# calculate the batch loss
loss = criterion(output, target)
# update average validation loss
valid_loss += loss.item() * data.size(0)
except Exception as e:
print(f'Bad image skipped.')
# calculate average losses
train_loss = train_loss/len(train_loader.dataset)
valid_loss = valid_loss/len(valid_loader.dataset)
# print training/validation statistics
print('Epoch: {} \tTraining Loss: {:.6f} \tValidation Loss: {:.6f}'.format(
epoch, train_loss, valid_loss))
# save model if validation loss has decreased
if valid_loss <= valid_loss_min:
print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(
valid_loss_min,
valid_loss))
torch.save(hfdetector.state_dict(), 'model_cifar.pt')
valid_loss_min = valid_loss
early_stop_count = 0
else:
early_stop_count += 1
end = time.time()
t = int(end - start)
print(f'Training ended at {time.ctime()}, total training time is {t//3600}hours {(t%3600)//60}minutes {(t%3600)%60} seconds.')
The model definition is as follows:
import torch
import torch.nn as nn
import torch.nn.functional as F
# Define NN architecture to distinguish human and dog
class HumanFaceDetector(nn.Module):
def __init__(self):
super().__init__()
# convolutional layers
self.conv1 = nn.Conv2d(3, 16, 3, stride=1, padding=1)
self.conv2 = nn.Conv2d(16, 32, 3, stride=1, padding=1)
self.conv3 = nn.Conv2d(32, 32, 3, stride=1, padding=1)
self.conv4 = nn.Conv2d(32, 64, 3, stride=1, padding=1)
# max pooling layer
self.pool = nn.MaxPool2d(2, 2)
# dropout layer
self.dropout = nn.Dropout(0.25)
# fully connected layer
self.fc1 = nn.Linear(16 * 16 * 64, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 64)
self.fc4 = nn.Linear(64, 2)
def forward(self, x):
# add sequence of convolutional and max pooling layers
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = F.relu(self.conv3(x))
x = self.pool(F.relu(self.conv4(x)))
x = x.view(-1, 64 * 16 * 16)
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = F.relu(self.fc2(x))
x = self.dropout(x)
x = F.relu(self.fc3(x))
x = self.fc4(x)
return x
# initialize the NN
hfdetector = HumanFaceDetector()
print(hfdetector)
hfdetector = hfdetector.cuda()