I wanted to implement sequence classification of videos, so far I have been using a pretrained feature extractor to get a d-dimensional vector representation of a frame for all frames and pass this to an LSTM.
All this while I have been using sequence length = number of frames in the video and batch size of 1.
Since all my videos have varying number of sequence lengths I understand that I will have to pad them in some way like in the pad_sequence() function in utils.rnn
I understand that I will have to arrange the data as seq_length x batch_size x (…) and doing so would have a trade off between generalizability and memory
My question is which would be better - padding with zero vectors or randomly picking random frames and repeating it until total length equals max_length ?
@gtm2122 padding with zero is fine. The padded regions are not actually used in computation if you use pack_padded_sequence() and give the packed sequence to nn.LSTM
I am also dealing with a similar problem, where I need to feed some feature vectors (75-dimensional) for each of the frame into LSTM, my problem is based on the classification one, so the output of LSTM is passed to a Dense layer. I was wondering what should be the output of LSTM be like, should I output a set of 75-dimensional vectors and pass them to the dense layer, or something else?
Any suggestion would be appreciated. Thank you very much.
Grid search is what I use. I train multiple models looping through layers = 1:5 for hidden dim in 200 to 3000 droput 0, 0.2 , 0.5. do this and keep a note of the train and Val curve. More importantly the Val curve to see when to lower learning rate. Make several copies of your train wrapper file and run it on mutliple tmux windows.
Hi,
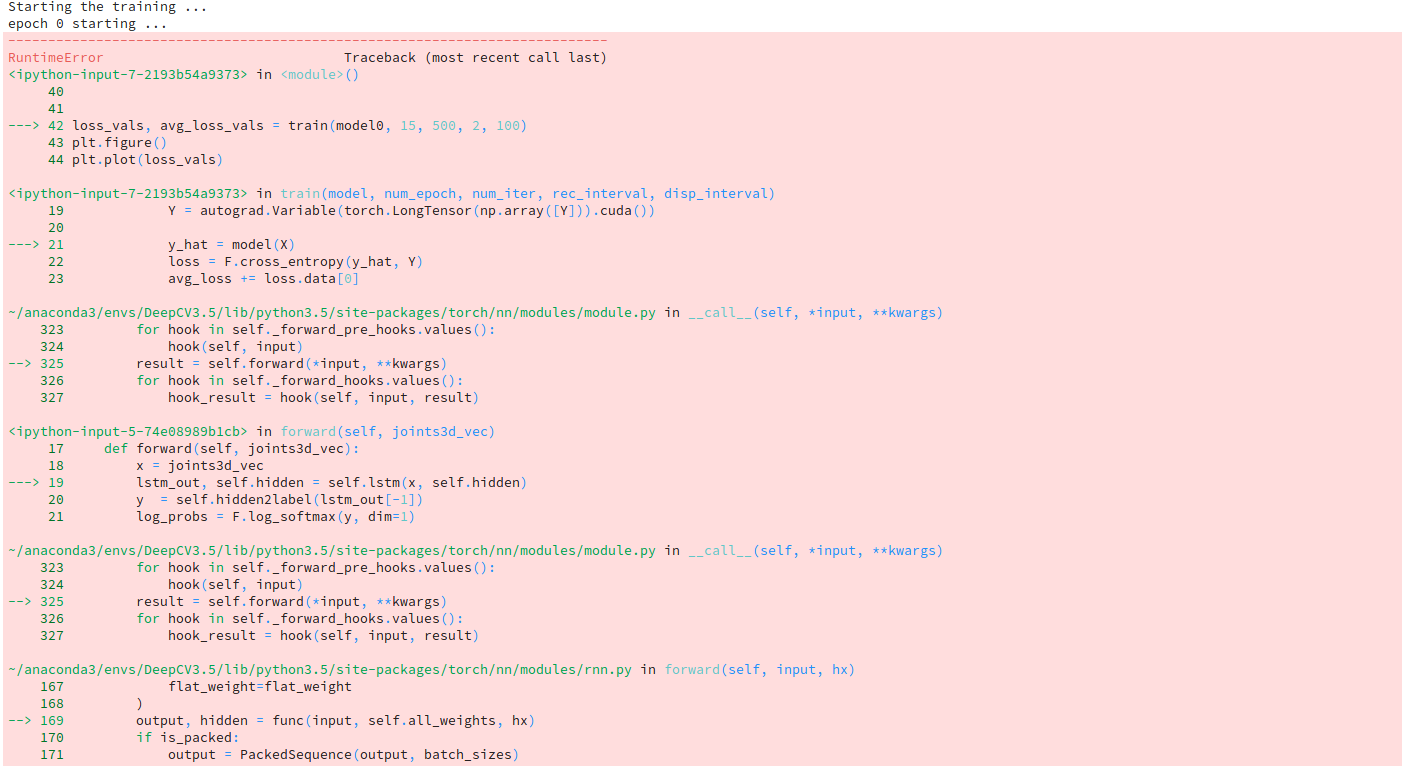
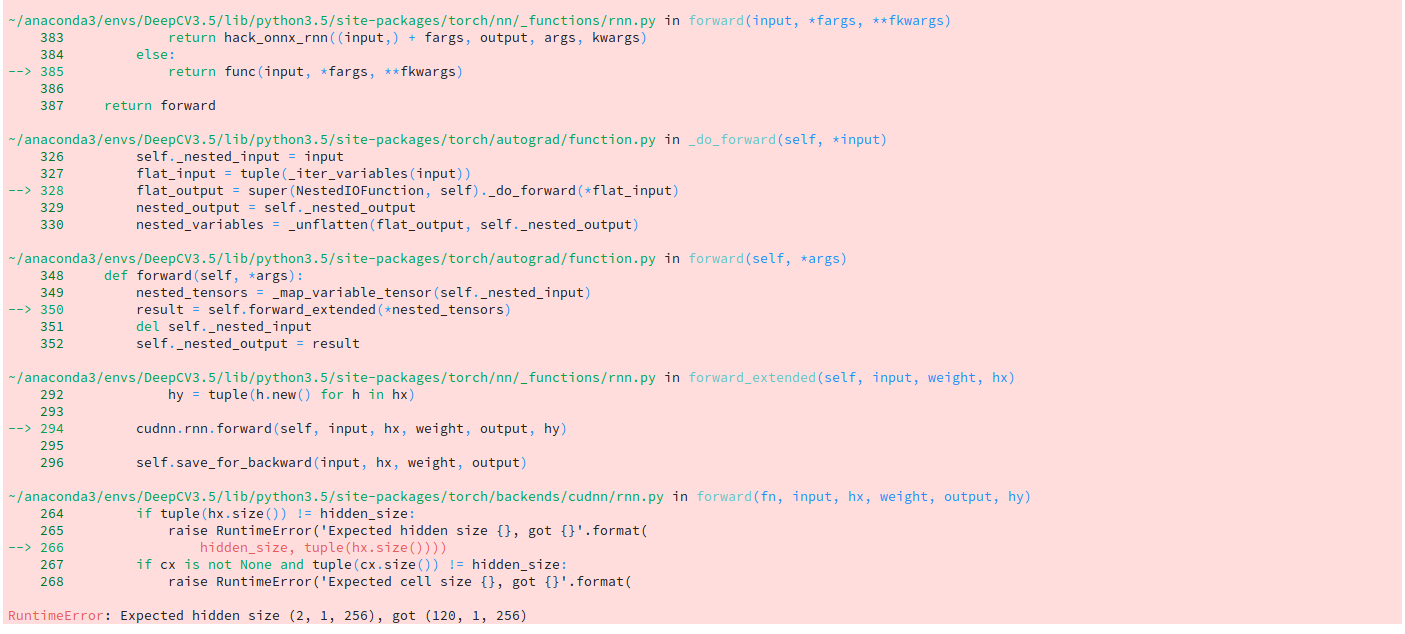
I was able to get my model running on cpu, when I am trying to use cuda, I’m running into the following problem. Did you face something similar? any clues?
Specifically I wanted to know why should num_layers parameter in LSTM has to be equal to the lenth of my sequence (according to the error).
It seems that using nn.LSTM with and without CUDA have different semantics (even in initialization).
Consider the following case:
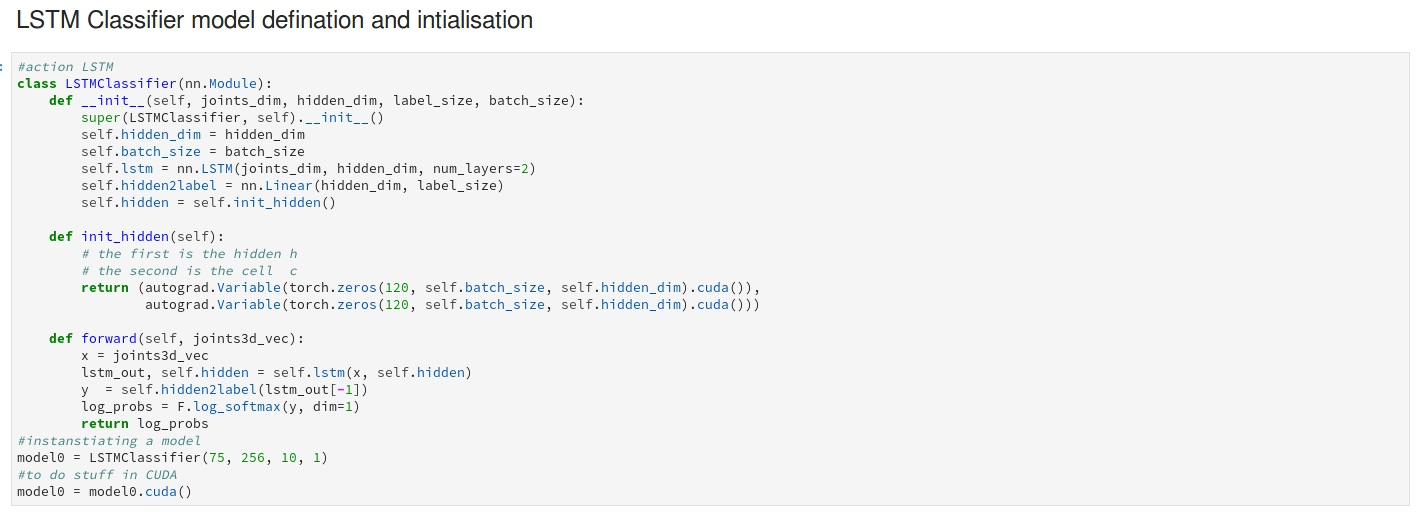
I have the following model, in which I am feeding features (75-D) of video data, and finally want to be able to classify the video
**Note that num_layers=2 in nn.LSTM (my understanding is that this corresponds to number of layers in the LSTM layers and it has nothing to do with the sequence length or batch size, PLEASE CORRECT ME IF I’M WRONG) **
Now If I remove .cuda() from everywhere and run it on cpu, then this error doesn’t appear and I am able to train the model.
Please let me know if I am missing something or my interpretation is wrong. Also please point out to some sources for reference for pytorch LSTM (if any).