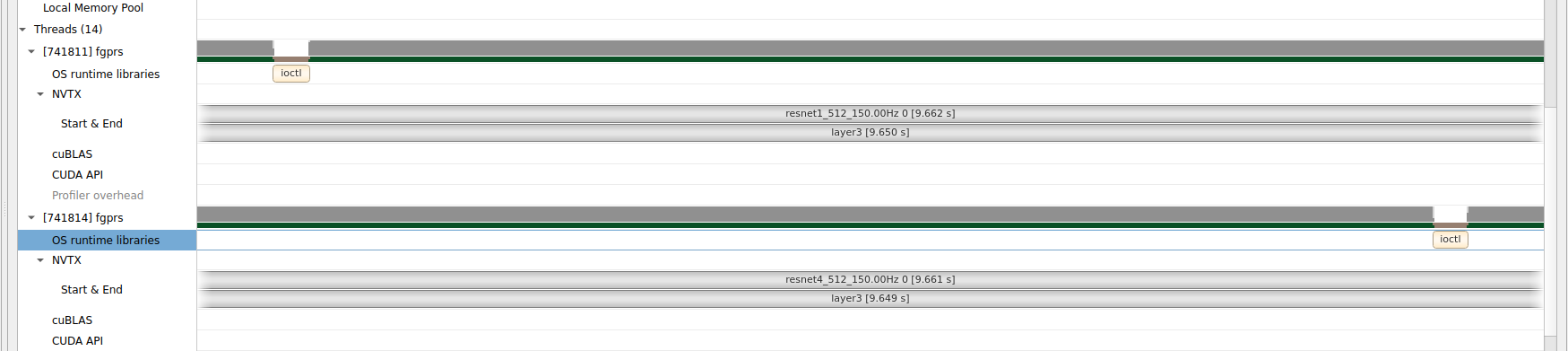
I have designed a real-time scheduler based on LibTorch, using multiple CUDA Contexts and Streams. The problem is sometimes one of the contexts gets stuck suddenly and whatever workload I assign to it gets stuck.
This is a simple code showing how I use it:
cuCtxSetCurrent(_context);
_context.select();
_stream = at::cuda::getStreamFromPool(false, _context->index);
at::cuda::setCurrentCUDAStream(_stream);
auto output = sequential->forward(input);
_stream.synchronize();
It’s a complex scheduler and I have modified the source for PyTorch to treat each CUDA Context as a separate CUDA device. It’s interesting when using a smaller input size for the network (like 224x224), it works fine but when I use a larger input size (like 512x512) sometimes it gets stuck.
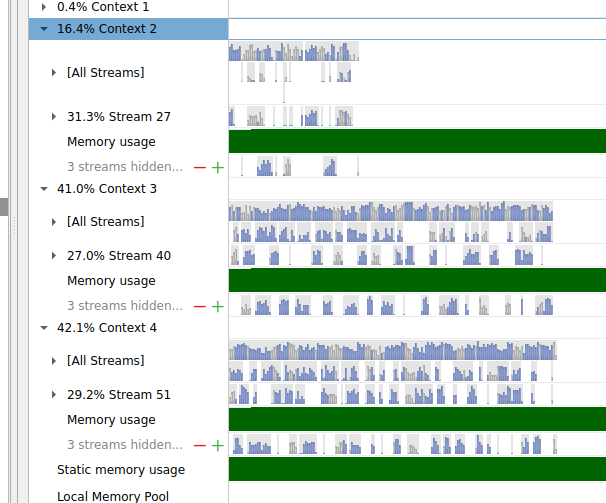
This is a screenshot from NSight Systems showing that after a specific time Context 2 has stuck and no more kernels have been scheduled in it. (And all the modules being executed in it are frozen). Using CUDA_LAUNCH_BLOCKING=0 also solves the problem but I don’t want to use it because it results in poor performance.
Does anyone have any idea what would be the reason for this?