Hello everyone,
I am studying about quaternion convolutional neural network following this repo on github: GitHub - Orkis-Research/Pytorch-Quaternion-Neural-Networks: This repository is an update to all previous repositories with implementations of various Quaternion-valued Neural Networks in PyTorch
The repo’s work is great but i want to implement a max amplitude pooling layer to utilize the quaternion network.
The basic idea follows this paper: Quaternion Convolutional Neural Network for Color Image Classification and Forensics | IEEE Journals & Magazine | IEEE Xplore
The pooling will take 4 input layer, compute the amplitude (length) then apply a max pooling. The torch.max function return pooled result and indices for max values.
My question is how to apply these indices to the input layer to get pooled results.
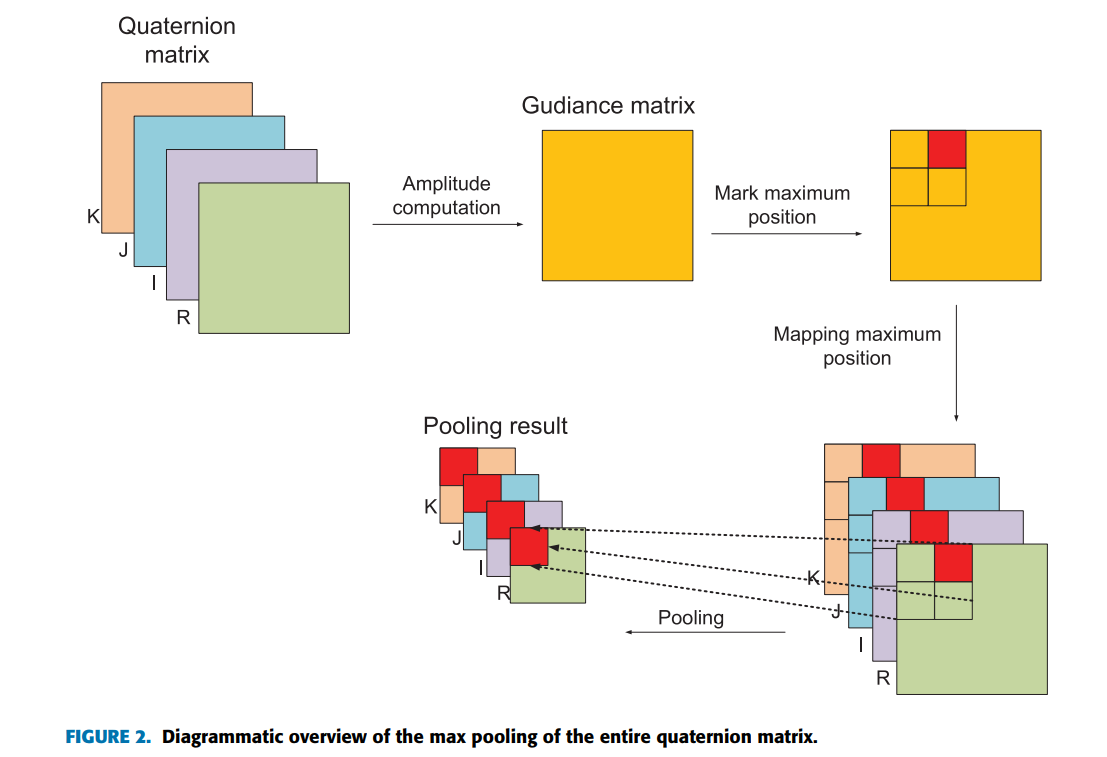
In my custom pooling layer, indices can be a list or a tensor with shape (n, c, h, w); input has shape (n, 4c, h, w) and amplitude has shape (n, c, h, w)
This is my forward function:
def forward(self, x):
# x = F.pad(x, self._padding(x), mode='constant')
amplitude = get_modulus(x, vector_form=True)
input_size = x.size()
amp_size = amplitude.size()
x_r = get_r(x)
x_i = get_i(x)
x_j = get_j(x)
x_k = get_k(x)
amp = amplitude.unfold(2, self.k[0], self.stride[0]).unfold(3, self.k[1], self.stride[1])
print("amp unfold size: ", amp.size())
x_r = x_r.unfold(2, self.k[0], self.stride[0]).unfold(3, self.k[1], self.stride[1])
x_i = x_i.unfold(2, self.k[0], self.stride[0]).unfold(3, self.k[1], self.stride[1])
x_j = x_j.unfold(2, self.k[0], self.stride[0]).unfold(3, self.k[1], self.stride[1])
x_k = x_k.unfold(2, self.k[0], self.stride[0]).unfold(3, self.k[1], self.stride[1])
"""
tensor.unfold(axis, size, step)
Returns a view of the original tensor which contains all slices of size size from self tensor in the dimension dimension.
Step between two slices is given by step.
"""
amp = amp.contiguous().view(amp.size()[:4] + (-1,))
print("amp size after view: ",amp.size())
x_r = x_r.contiguous().view(x_r.size()[:4] + (-1,))
x_i = x_i.contiguous().view(x_i.size()[:4] + (-1,))
x_j = x_j.contiguous().view(x_j.size()[:4] + (-1,))
x_k = x_k.contiguous().view(x_k.size()[:4] + (-1,))
"""
tensor.contiguous() => create a copy of tensor
"""
amp_max, indice = torch.max(amp, dim = -1)
indice = torch.squeeze(indice).tolist()
# print(indice)
"""
initialize output channel
"""
# x_r_out = torch.zeros_like(x_r.mean(4))
# x_i_out = torch.zeros_like(x_r.mean(4))
# x_j_out = torch.zeros_like(x_r.mean(4))
# x_k_out = torch.zeros_like(x_r.mean(4))
"""
apply max amplitude position => max amplitude pooling
"""
# x_r_out
# x_i_out
# x_j_out
# x_k_out
print('size of input: ', input_size)
print('size of amplitude: ', amp_size)
print('size of pooling: ', amp_max.size())
return torch.cat((x_r_out, x_i_out, x_j_out, x_k_out), dim = 1)