In sub-path training, such as NAS,there are two path A and B need to be optimized. for example, the optimizing order is B->A:
1.when using a single-gpu, everything works well if we set require_grad=False for unselected path,
2.but when using DistributedDataParallel, we need set find_unused_parameters=True in this condition,and because of grad sync,for example, when optimizes path A in step2, the parameters‘ grad in path B will be 0 rather then None
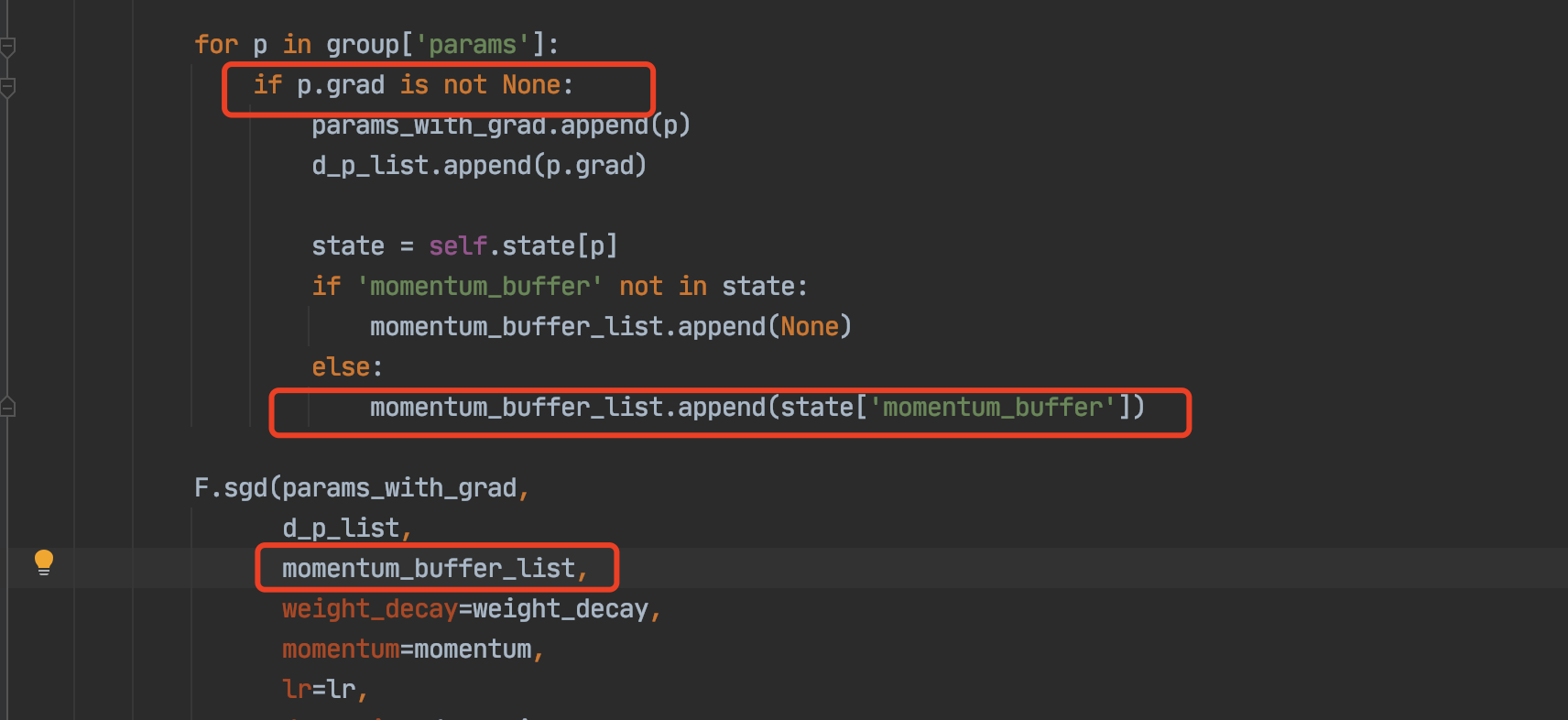
Here comes the problem: optimizer chooses to update params which grad is not None. If we set momentum in SGD or something else in other optimizer, when optimizing path A in step 2, because we have already optimized path B once,so parameters in B have momentum_buffer, although path B’s grad is 0, it will also be updated by the buffer which is incorrect!
Even we set require_grad=False for path B, but once path B is optimized, its grad will be 0 rather then None.
Thanks for posting @VisionAdam Do we know why the grad in path B becomes 0 even if we optimizing path A? I recalled DDP will just don’t touch the gradient field if it’s not being used in forward. Can you share more details why we are observing those gradients be 0?
Also, did you try setting the gradients of Path B explicitly to None and see if that fix your issue?
If @wanchaol’s suggests don’t resolve the issue, feel free to post this as a bug over at Issues · pytorch/pytorch · GitHub ideally with a repro!
if we never optimize path B, the grad will be None, but if path B optimized once, the grad will be 0 in future time.
It can be fixed by set grad to None while the grad is all zero