Hello,
I have trained a model base on SegNet architecture, and when I do it from scratch presents some odds behaviours:
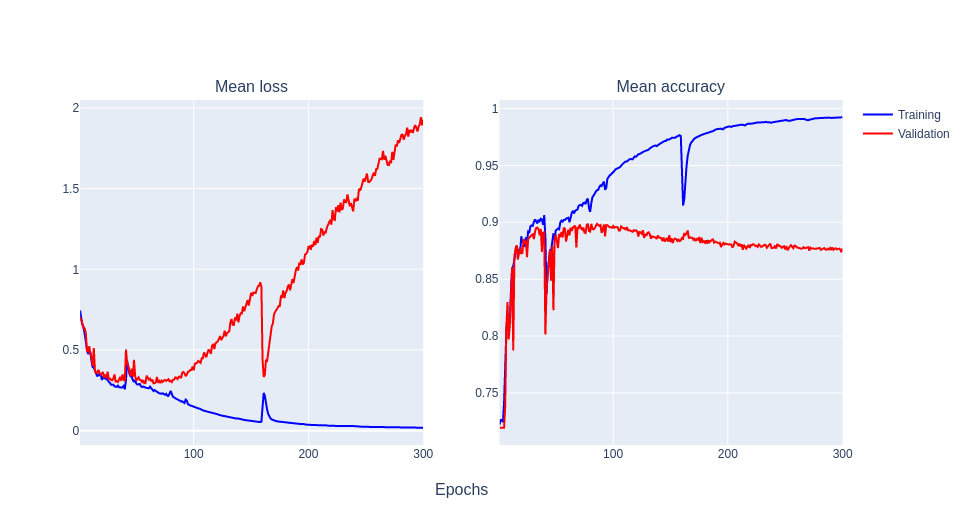
My dataset size is small (165 samples) and I used the following input parameters:
- Batch size = 1
- Learning rate = 0.1
- Momentum = 0.9
- Loss function = Cross-entropy loss
Why does it behave like this? I have been reading about this topic, but I can not be able to find an explanation of this sudden peaks. However, when I apply transfer learning (from VGG16), the odd behaviour does not happen:
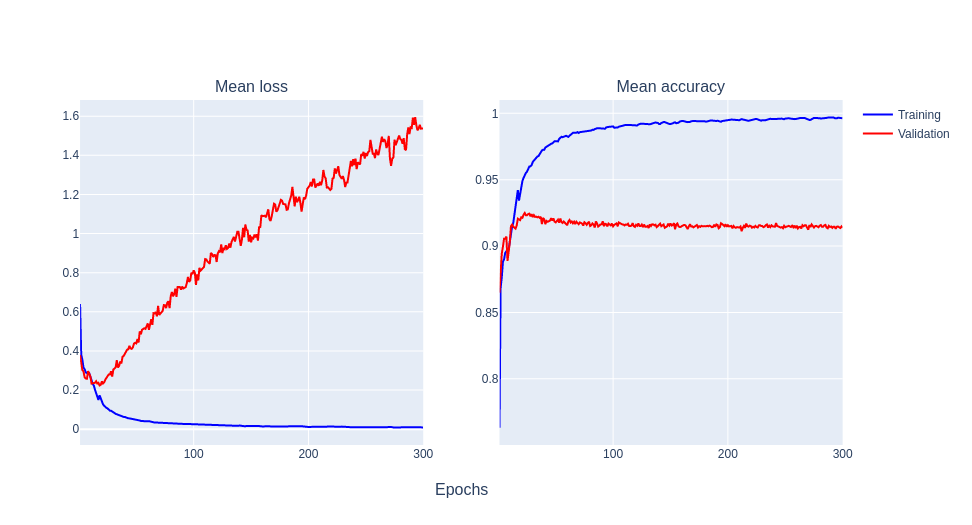
Could it be related to the small training set I used?