I am implementing fast-rcnn(base on VGG16) by PyTorch. And my graphic card is GTX1060(6G version).
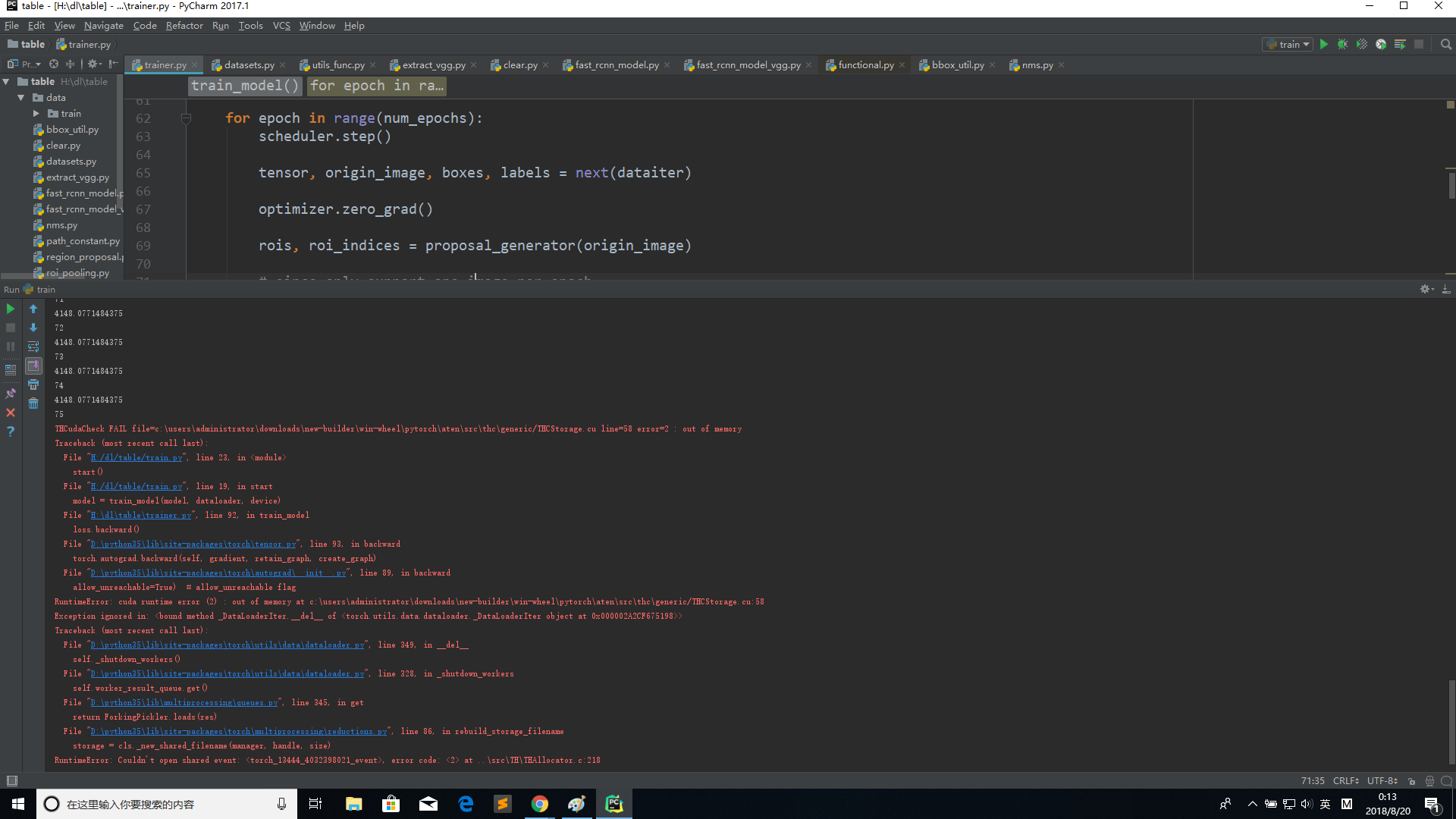
During the training stage, the program always crash(out of memory) after several epochs training.
But the strange part is, sometimes after 100~200 epochs, the error will occur, while sometimes only after 5~10 epochs.
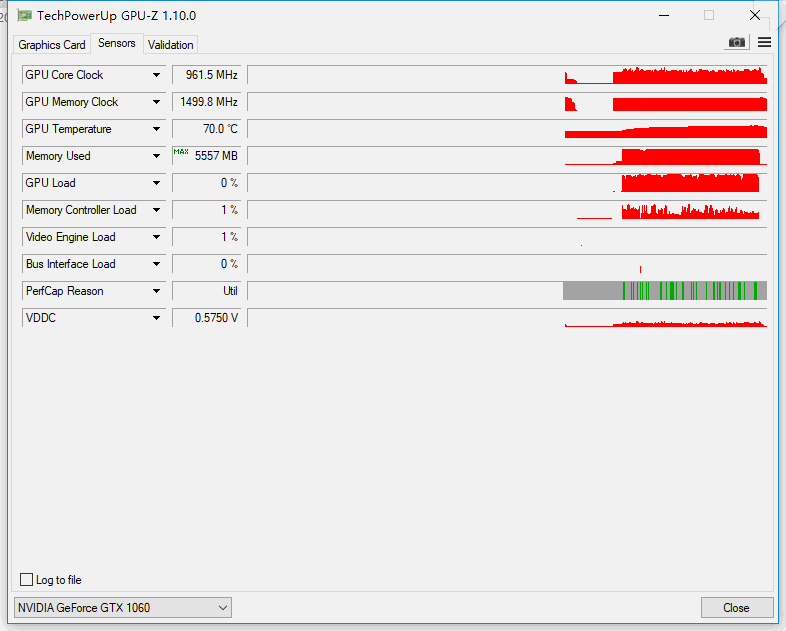
I use the max_memory_allocated to show the memory usage, the memory usage keeps about 4000M in each epoch. Since the memory usage remain constant before the OOM occurs, I think there may be not memory leak. And the nvidia-smi’s result is approximate 5600M. But suddenly, the crash occurs.
Here’s the training part code.
for epoch in range(num_epochs):
scheduler.step()
tensor, origin_image, boxes, labels = next(dataiter)
optimizer.zero_grad()
rois, roi_indices = proposal_generator(origin_image)
# since only support one image per epoch
boxes = boxes[0]
labels = labels[0]
sample_rois, gt_roi_loc, gt_roi_label = proposal_target_creator(rois, boxes, labels)
n_sample = sample_rois.size(0)
roi_indices = torch.zeros(n_sample, dtype=torch.int)
tensor = tensor.to(device)
sample_rois = sample_rois.to(device)
gt_roi_loc = gt_roi_loc.to(device)
roi_indices = roi_indices.to(device)
gt_roi_label = gt_roi_label.to(device)
roi_cls_loc, roi_scores = model(tensor, sample_rois, roi_indices)
gt_roi_label = gt_roi_label.long()
class_loss = class_criterion(roi_scores, gt_roi_label)
regression_loss = loc_loss(bbox_regression_criterion, n_sample,
roi_cls_loc, gt_roi_loc, gt_roi_label)
loss = class_loss + regression_loss
loss.backward()
print(torch.cuda.max_memory_allocated() / (1024 * 1024))
running_loss += loss.item()
print(epoch)
if epoch % 100 == 0:
print('[%d] loss: %.3f' %
(epoch, running_loss / 100))
running_loss = 0.
optimizer.step()
Update:
Here’s another question, i use the max_memory_allocated to print the memory usage before training start, its result is approximate 500M, which is close to VGG’s parameters occupation. However, after the first epoch, it suddenly rise up to 3500M, and then stably keeps at 4000M after several epochs. I calculate the size of tensor, sample_rois, roi_indices and gt_roi_label, the sum is only about 10M. So why does the memory usage rise up so high?