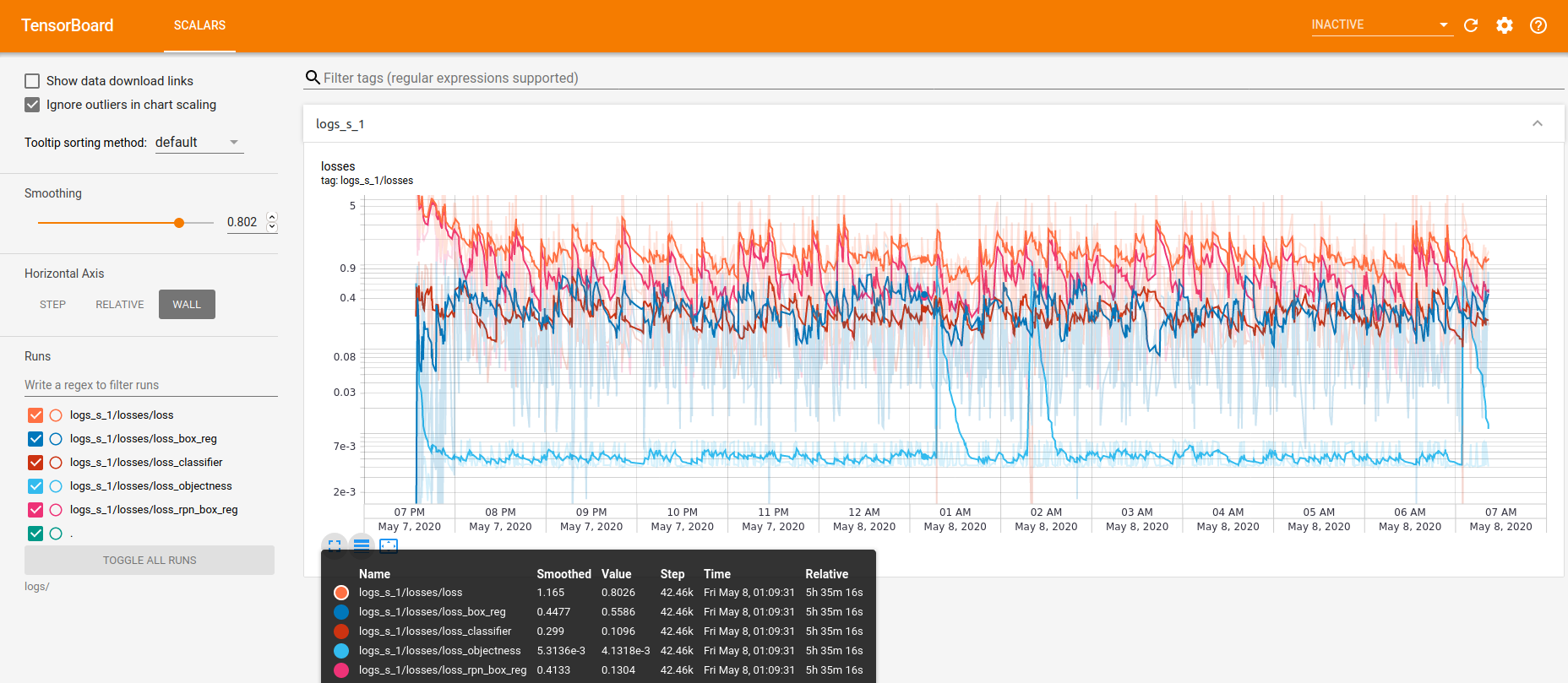
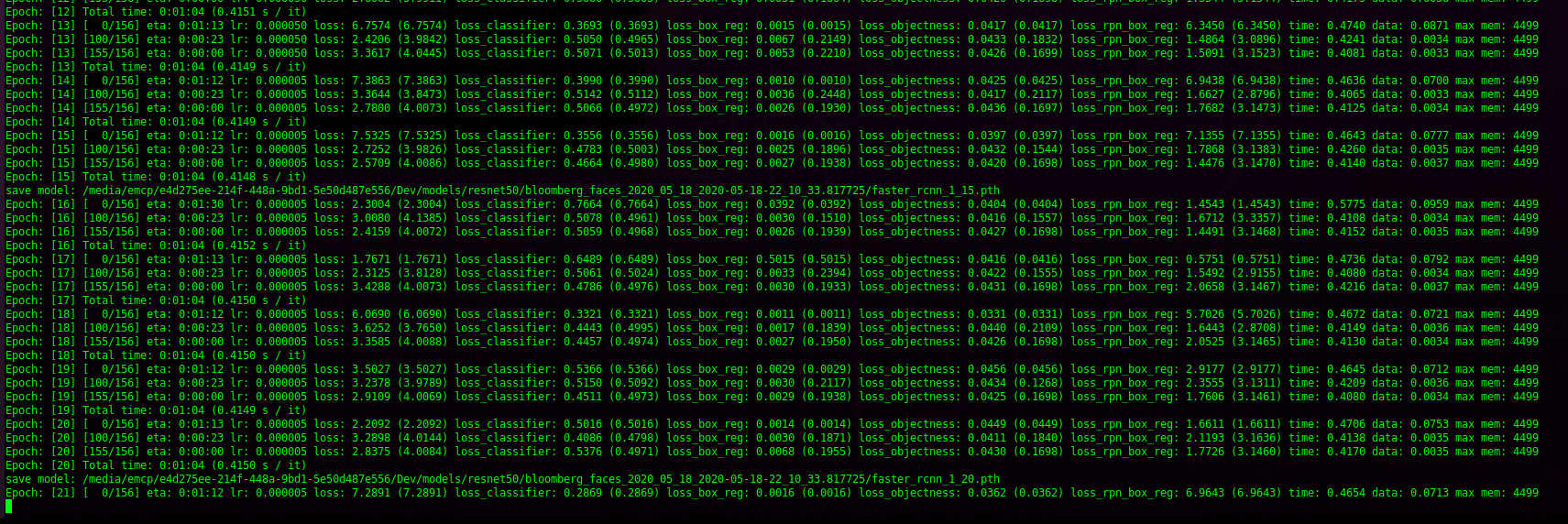
Unfortunately not.
My next move, is to make a downsized problem set… with smaller resolution images which have a better chance of fully fitting within RAM with no downsampling…
I posted the network code a while ago but no interest in it at the time… I figure I’ll use this as a way to learn how to quickly debug a custom COCO dataset training… because even though the tutorial has an evaluation call… it all is hard coded to the original coco dataset… and the second you bring in your own custom data, it breaks… so I need to write my own eval routine to run in tandem with training… then maybe I can see where it starts to go wrong (ie right away, and never improves… or later in the training it starts to lose accuracy)
Edit:
heres my run with resnet 101… fine tuning enabled
python training.py
Using hyperParameters:
{'hyperParameters': {'anchor_ratios': [0.5, 1.0, 2.0],
'anchor_scales': [32, 64, 256, 512],
'bad_net': 'spineless_model',
'batch_size': 1,
'display_interval': 100,
'epoch_max': 400,
'epoch_start': 0,
'freeze_pretrained_gradients': False,
'learning_decay_gamma': 0.1,
'learning_decay_milestones': [1, 5, 7, 10, 14, 20, 45],
'learning_decay_step': 25,
'learning_rate': 0.05,
'learning_weight_decay': 0.001,
'min_size_image': 800,
'momentum': 0.9,
'net': 'resnet101',
'net_out_channels': 2048,
'normalization_mean': [0.485, 0.456, 0.406],
'normalization_std': [0.229, 0.224, 0.225],
'optimizer': 'sgd',
'pooling_size': 7,
'rpn_nms_thresh': 0.7,
'rpn_post_nms_top_n_train': 5,
'rpn_pre_nms_top_n_train': 10,
'testing': {'check_epoch': 65,
'check_session': 1,
'enable_visualization': True,
'visualization_thresh': 0.1}},
'pytorch_engine': {'enable_cuda': True,
'enable_multiple_gpus': False,
'enable_tfb': True,
'evaluate_only_mode': False,
'num_workers': 1,
'resume_checkpoint': False,
'resume_checkpoint_epoch': 1,
'resume_checkpoint_num': 0,
'resume_checkpoint_session': 1,
'session': 1,
'test_dataloader': False},
'pytorch_engine_scoring': {'enable_cuda': False,
'enable_multiple_gpus': False,
'enable_tfb': False,
'num_workers': 1,
'resume_checkpoint': False,
'resume_checkpoint_epoch': 1,
'resume_checkpoint_num': 0,
'resume_checkpoint_session': 1,
'session': 1}}
loading annotations into memory...
Done (t=0.01s)
creating index...
index created!
found 5 categories in data at: /images/datasets/training
Creating model backbone with resnet101
Using fine-tuning of the model
anchor_ratios = (0.5, 1.0, 2.0)
anchor_sizes = (32, 64, 256, 512)
/home/emcp/anaconda3/envs/pytorch_150/lib/python3.7/site-packages/torch/nn/functional.py:2854: UserWarning: The default behavior for interpolate/upsample with float scale_factor will change in 1.6.0 to align with other frameworks/libraries, and use scale_factor directly, instead of relying on the computed output size. If you wish to keep the old behavior, please set recompute_scale_factor=True. See the documentation of nn.Upsample for details.
warnings.warn("The default behavior for interpolate/upsample with float scale_factor will change "
/opt/conda/conda-bld/pytorch_1587428266983/work/torch/csrc/utils/python_arg_parser.cpp:756: UserWarning: This overload of nonzero is deprecated:
nonzero(Tensor input, *, Tensor out)
Consider using one of the following signatures instead:
nonzero(Tensor input, *, bool as_tuple)
Epoch: [0] [ 0/674] eta: 0:11:40 lr: 0.050000 loss: 20.3240 (20.3240) loss_classifier: 1.6234 (1.6234) loss_box_reg: 0.0011 (0.0011) loss_objectness: 0.6847 (0.6847) loss_rpn_box_reg: 18.0148 (18.0148) time: 1.0398 data: 0.3440 max mem: 3913
Epoch: [0] [100/674] eta: 0:05:41 lr: 0.050000 loss: 2.8428 (8.9256) loss_classifier: 0.6811 (1.6685) loss_box_reg: 0.0076 (0.2147) loss_objectness: 0.0103 (0.0399) loss_rpn_box_reg: 1.7338 (7.0025) time: 0.5908 data: 0.0118 max mem: 5138
Epoch: [0] [200/674] eta: 0:04:41 lr: 0.050000 loss: 2.8853 (7.0916) loss_classifier: 0.6036 (1.2062) loss_box_reg: 0.0063 (0.1727) loss_objectness: 0.0071 (0.0246) loss_rpn_box_reg: 2.2448 (5.6881) time: 0.5920 data: 0.0116 max mem: 5138
Epoch: [0] [300/674] eta: 0:03:41 lr: 0.050000 loss: 3.6367 (6.1657) loss_classifier: 0.4982 (1.0114) loss_box_reg: 0.1109 (0.1999) loss_objectness: 0.0074 (0.0188) loss_rpn_box_reg: 3.0872 (4.9356) time: 0.5914 data: 0.0120 max mem: 5138
Epoch: [0] [400/674] eta: 0:02:42 lr: 0.050000 loss: 4.3385 (5.9693) loss_classifier: 0.3438 (0.8648) loss_box_reg: 0.0121 (0.1844) loss_objectness: 0.0057 (0.0158) loss_rpn_box_reg: 4.0720 (4.9043) time: 0.5921 data: 0.0120 max mem: 5138
Epoch: [0] [500/674] eta: 0:01:43 lr: 0.050000 loss: 3.2315 (5.7498) loss_classifier: 0.4071 (0.7920) loss_box_reg: 0.0151 (0.1808) loss_objectness: 0.0104 (0.0242) loss_rpn_box_reg: 2.4130 (4.7529) time: 0.5919 data: 0.0117 max mem: 5267
Epoch: [0] [600/674] eta: 0:00:43 lr: 0.050000 loss: 5.3011 (5.6707) loss_classifier: 0.1824 (0.7268) loss_box_reg: 0.0032 (0.1729) loss_objectness: 0.0079 (0.0216) loss_rpn_box_reg: 4.6754 (4.7494) time: 0.5924 data: 0.0120 max mem: 5267
Epoch: [0] [673/674] eta: 0:00:00 lr: 0.050000 loss: 4.1352 (5.5770) loss_classifier: 0.3168 (0.7120) loss_box_reg: 0.0100 (0.1859) loss_objectness: 0.0082 (0.0201) loss_rpn_box_reg: 3.8195 (4.6589) time: 0.5913 data: 0.0119 max mem: 5267
Epoch: [0] Total time: 0:06:39 (0.5927 s / it)
save model: /media/faster_rcnn_1_0.pth
Epoch: [1] [ 0/674] eta: 0:10:12 lr: 0.005000 loss: 2.6780 (2.6780) loss_classifier: 0.5748 (0.5748) loss_box_reg: 0.4465 (0.4465) loss_objectness: 0.0059 (0.0059) loss_rpn_box_reg: 1.6508 (1.6508) time: 0.9083 data: 0.3295 max mem: 5267
Epoch: [1] [100/674] eta: 0:05:39 lr: 0.005000 loss: 2.1842 (4.3055) loss_classifier: 0.7421 (0.6624) loss_box_reg: 0.2575 (0.4184) loss_objectness: 0.0066 (0.0067) loss_rpn_box_reg: 0.8786 (3.2179) time: 0.5884 data: 0.0120 max mem: 5267
Epoch: [1] [200/674] eta: 0:04:39 lr: 0.005000 loss: 1.6545 (4.0246) loss_classifier: 0.6738 (0.6663) loss_box_reg: 0.2428 (0.4056) loss_objectness: 0.0061 (0.0066) loss_rpn_box_reg: 0.4456 (2.9461) time: 0.5888 data: 0.0124 max mem: 5267
Epoch: [1] [300/674] eta: 0:03:40 lr: 0.005000 loss: 1.8270 (3.8002) loss_classifier: 0.6603 (0.6722) loss_box_reg: 0.4036 (0.4415) loss_objectness: 0.0063 (0.0219) loss_rpn_box_reg: 0.2459 (2.6646) time: 0.5889 data: 0.0126 max mem: 5269
Epoch: [1] [400/674] eta: 0:02:41 lr: 0.005000 loss: 2.4241 (3.9155) loss_classifier: 0.5570 (0.6533) loss_box_reg: 0.1109 (0.4080) loss_objectness: 0.0070 (0.0180) loss_rpn_box_reg: 1.3295 (2.8362) time: 0.5898 data: 0.0127 max mem: 5269
Epoch: [1] [500/674] eta: 0:01:42 lr: 0.005000 loss: 1.4252 (3.9252) loss_classifier: 0.5889 (0.6390) loss_box_reg: 0.3226 (0.3994) loss_objectness: 0.0058 (0.0156) loss_rpn_box_reg: 0.3787 (2.8712) time: 0.5897 data: 0.0129 max mem: 5269
Epoch: [1] [600/674] eta: 0:00:43 lr: 0.005000 loss: 1.6905 (4.0094) loss_classifier: 0.5049 (0.6345) loss_box_reg: 0.0186 (0.3849) loss_objectness: 0.0056 (0.0140) loss_rpn_box_reg: 0.9127 (2.9760) time: 0.5901 data: 0.0129 max mem: 5269
Epoch: [1] [673/674] eta: 0:00:00 lr: 0.005000 loss: 7.3891 (4.0688) loss_classifier: 0.3403 (0.6294) loss_box_reg: 0.0043 (0.3838) loss_objectness: 0.0057 (0.0131) loss_rpn_box_reg: 7.1363 (3.0425) time: 0.5905 data: 0.0129 max mem: 5269
Epoch: [1] Total time: 0:06:37 (0.5901 s / it)
Epoch: [2] [ 0/674] eta: 0:10:07 lr: 0.005000 loss: 1.6134 (1.6134) loss_classifier: 0.3985 (0.3985) loss_box_reg: 0.0151 (0.0151) loss_objectness: 0.0056 (0.0056) loss_rpn_box_reg: 1.1942 (1.1942) time: 0.9007 data: 0.3221 max mem: 5269
Epoch: [2] [100/674] eta: 0:05:39 lr: 0.005000 loss: 1.5995 (3.4240) loss_classifier: 0.6868 (0.5982) loss_box_reg: 0.5180 (0.5042) loss_objectness: 0.0051 (0.0053) loss_rpn_box_reg: 0.2366 (2.3163) time: 0.5881 data: 0.0120 max mem: 5269
Epoch: [2] [200/674] eta: 0:04:39 lr: 0.005000 loss: 1.5641 (3.7782) loss_classifier: 0.6945 (0.6121) loss_box_reg: 0.3320 (0.4361) loss_objectness: 0.0051 (0.0053) loss_rpn_box_reg: 0.3707 (2.7248) time: 0.5893 data: 0.0124 max mem: 5269
Epoch: [2] [300/674] eta: 0:03:40 lr: 0.005000 loss: 1.8371 (3.9685) loss_classifier: 0.5943 (0.6134) loss_box_reg: 0.1414 (0.4042) loss_objectness: 0.0055 (0.0213) loss_rpn_box_reg: 0.6749 (2.9296) time: 0.5892 data: 0.0124 max mem: 5269
Epoch: [2] [400/674] eta: 0:02:41 lr: 0.005000 loss: 1.5657 (4.0406) loss_classifier: 0.6042 (0.6090) loss_box_reg: 0.4362 (0.3977) loss_objectness: 0.0051 (0.0173) loss_rpn_box_reg: 0.3392 (3.0166) time: 0.5900 data: 0.0128 max mem: 5269
Epoch: [2] [500/674] eta: 0:01:42 lr: 0.005000 loss: 1.5843 (3.9926) loss_classifier: 0.6372 (0.6085) loss_box_reg: 0.2343 (0.4029) loss_objectness: 0.0049 (0.0149) loss_rpn_box_reg: 0.3865 (2.9663) time: 0.5899 data: 0.0129 max mem: 5269
Epoch: [2] [600/674] eta: 0:00:43 lr: 0.005000 loss: 1.7645 (4.0018) loss_classifier: 0.6550 (0.6076) loss_box_reg: 0.3710 (0.4219) loss_objectness: 0.0048 (0.0132) loss_rpn_box_reg: 0.4184 (2.9591) time: 0.5900 data: 0.0129 max mem: 5269
Epoch: [2] [673/674] eta: 0:00:00 lr: 0.005000 loss: 2.1142 (4.0237) loss_classifier: 0.6099 (0.6118) loss_box_reg: 0.4489 (0.4192) loss_objectness: 0.0046 (0.0123) loss_rpn_box_reg: 0.4985 (2.9804) time: 0.5900 data: 0.0131 max mem: 5269
Epoch: [2] Total time: 0:06:37 (0.5901 s / it)
fast forward a few hours…
Epoch: [361] [ 0/674] eta: 0:11:04 lr: 0.000000 loss: 0.1095 (0.1095) loss_classifier: 0.0464 (0.0464) loss_box_reg: 0.0223 (0.0223) loss_objectness: 0.0036 (0.0036) loss_rpn_box_reg: 0.0371 (0.0371) time: 0.9858 data: 0.4051 max mem: 5269
Epoch: [361] [100/674] eta: 0:05:40 lr: 0.000000 loss: 0.6014 (2.6537) loss_classifier: 0.0319 (0.0365) loss_box_reg: 0.0267 (0.0590) loss_objectness: 0.0036 (0.0037) loss_rpn_box_reg: 0.2892 (2.5545) time: 0.5883 data: 0.0124 max mem: 5269
Epoch: [361] [200/674] eta: 0:04:40 lr: 0.000000 loss: 0.1555 (2.8574) loss_classifier: 0.0409 (0.0357) loss_box_reg: 0.0233 (0.0695) loss_objectness: 0.0036 (0.0291) loss_rpn_box_reg: 0.0717 (2.7230) time: 0.5890 data: 0.0128 max mem: 5269
Epoch: [361] [300/674] eta: 0:03:40 lr: 0.000000 loss: 0.2531 (2.8026) loss_classifier: 0.0459 (0.0361) loss_box_reg: 0.0227 (0.0688) loss_objectness: 0.0036 (0.0207) loss_rpn_box_reg: 0.0806 (2.6770) time: 0.5887 data: 0.0128 max mem: 5269
Epoch: [361] [400/674] eta: 0:02:41 lr: 0.000000 loss: 0.1561 (2.7800) loss_classifier: 0.0426 (0.0365) loss_box_reg: 0.0229 (0.0738) loss_objectness: 0.0036 (0.0164) loss_rpn_box_reg: 0.0665 (2.6533) time: 0.5893 data: 0.0129 max mem: 5269
Epoch: [361] [500/674] eta: 0:01:42 lr: 0.000000 loss: 0.3133 (2.7728) loss_classifier: 0.0421 (0.0364) loss_box_reg: 0.0229 (0.0740) loss_objectness: 0.0036 (0.0139) loss_rpn_box_reg: 0.1998 (2.6485) time: 0.5890 data: 0.0128 max mem: 5269
Epoch: [361] [600/674] eta: 0:00:43 lr: 0.000000 loss: 0.5409 (2.8695) loss_classifier: 0.0243 (0.0360) loss_box_reg: 0.0221 (0.0725) loss_objectness: 0.0036 (0.0122) loss_rpn_box_reg: 0.2905 (2.7488) time: 0.5893 data: 0.0128 max mem: 5269
Epoch: [361] [673/674] eta: 0:00:00 lr: 0.000000 loss: 0.6787 (2.9320) loss_classifier: 0.0392 (0.0357) loss_box_reg: 0.0223 (0.0721) loss_objectness: 0.0036 (0.0113) loss_rpn_box_reg: 0.2597 (2.8130) time: 0.5896 data: 0.0132 max mem: 5269
Epoch: [361] Total time: 0:06:37 (0.5902 s / it)
Epoch: [362] [ 0/674] eta: 0:11:23 lr: 0.000000 loss: 0.1250 (0.1250) loss_classifier: 0.0473 (0.0473) loss_box_reg: 0.0397 (0.0397) loss_objectness: 0.0036 (0.0036) loss_rpn_box_reg: 0.0343 (0.0343) time: 1.0143 data: 0.4332 max mem: 5269
Epoch: [362] [100/674] eta: 0:05:40 lr: 0.000000 loss: 0.7797 (3.0647) loss_classifier: 0.0406 (0.0354) loss_box_reg: 0.0283 (0.0841) loss_objectness: 0.0036 (0.0037) loss_rpn_box_reg: 0.2914 (2.9415) time: 0.5894 data: 0.0132 max mem: 5269
Epoch: [362] [200/674] eta: 0:04:40 lr: 0.000000 loss: 0.1940 (3.2964) loss_classifier: 0.0380 (0.0351) loss_box_reg: 0.0237 (0.0752) loss_objectness: 0.0036 (0.0037) loss_rpn_box_reg: 0.0905 (3.1825) time: 0.5903 data: 0.0136 max mem: 5269
Epoch: [362] [300/674] eta: 0:03:41 lr: 0.000000 loss: 0.1388 (3.1812) loss_classifier: 0.0457 (0.0354) loss_box_reg: 0.0217 (0.0706) loss_objectness: 0.0036 (0.0037) loss_rpn_box_reg: 0.0624 (3.0715) time: 0.5906 data: 0.0136 max mem: 5269
Epoch: [362] [400/674] eta: 0:02:41 lr: 0.000000 loss: 0.1619 (3.1720) loss_classifier: 0.0435 (0.0352) loss_box_reg: 0.0232 (0.0656) loss_objectness: 0.0036 (0.0037) loss_rpn_box_reg: 0.0800 (3.0675) time: 0.5904 data: 0.0134 max mem: 5269
Epoch: [362] [500/674] eta: 0:01:42 lr: 0.000000 loss: 0.1406 (2.9470) loss_classifier: 0.0426 (0.0357) loss_box_reg: 0.0256 (0.0678) loss_objectness: 0.0036 (0.0037) loss_rpn_box_reg: 0.0695 (2.8398) time: 0.5900 data: 0.0136 max mem: 5269
Epoch: [362] [600/674] eta: 0:00:43 lr: 0.000000 loss: 0.1427 (2.9059) loss_classifier: 0.0409 (0.0358) loss_box_reg: 0.0235 (0.0696) loss_objectness: 0.0036 (0.0037) loss_rpn_box_reg: 0.0656 (2.7968) time: 0.5903 data: 0.0138 max mem: 5269
Epoch: [362] [673/674] eta: 0:00:00 lr: 0.000000 loss: 0.3631 (2.9320) loss_classifier: 0.0388 (0.0357) loss_box_reg: 0.0232 (0.0721) loss_objectness: 0.0036 (0.0113) loss_rpn_box_reg: 0.2670 (2.8130) time: 0.5905 data: 0.0140 max mem: 5269
Epoch: [362] Total time: 0:06:38 (0.5912 s / it)