I’m trying to use ExecuTorch to deploy a LLM with a QNN backend. Unfortunately, QNN doesn’t support dynamic shapes, so some trick is needed to utilise up the NPU. A simple idea is shown below:
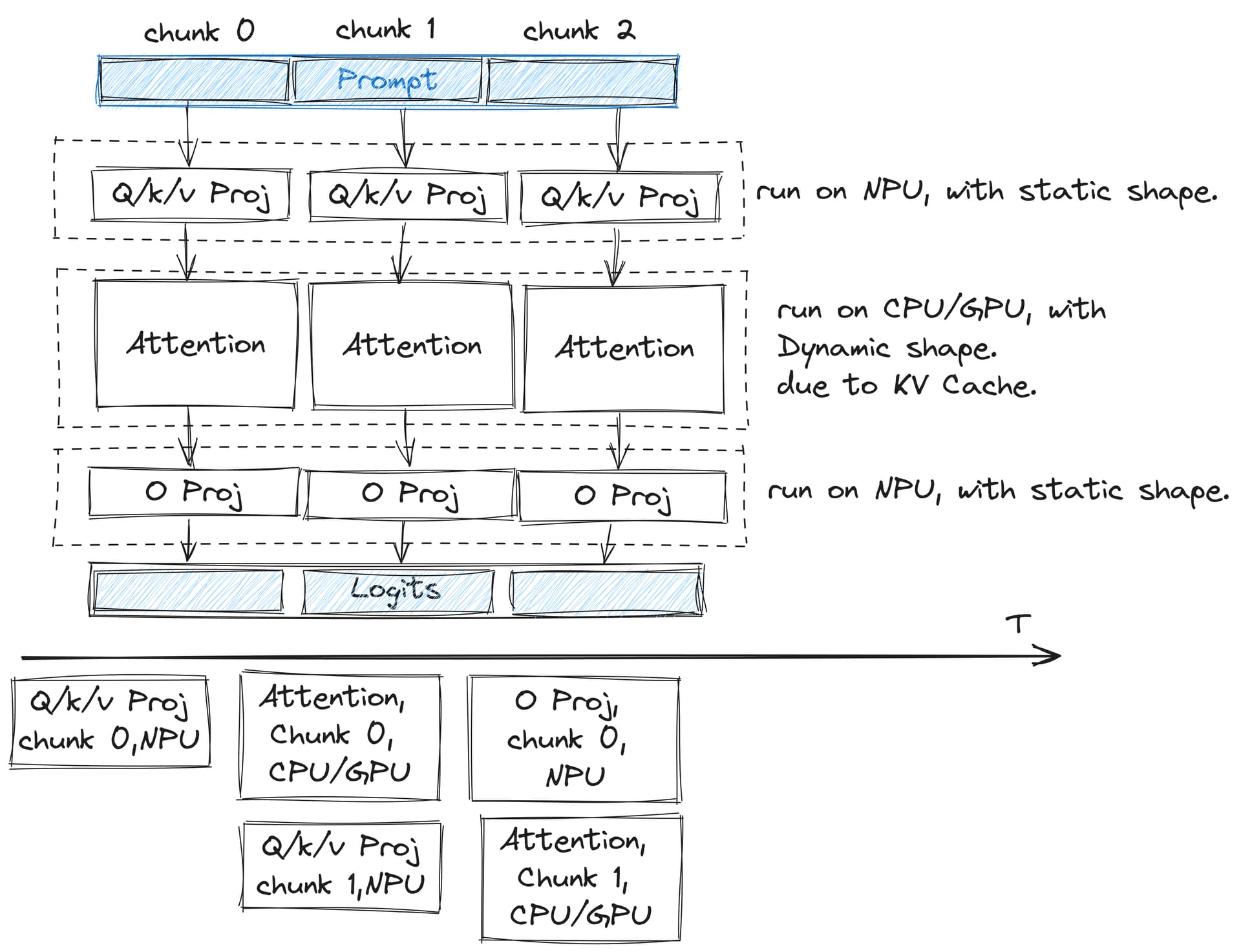
Divide the Prompt into fixed-size Chunks, and these fixed Chunks first enter the Static Shape QKV Proj (run using QNN-NPU), then proceed to the Dynamic Shape Attention (run using CPU). Because of the chunking, the computation of adjacent Tokens can be pipelined.
I am not familiar with ExecuTorch. In the examples of Dynamic Shape provided by ExecuTorch, it seems that dynamic shapes are specified within the export function. such as:
aten_dialect: ExportedProgram = export(
Basic(), example_args, dynamic_shapes=dynamic_shapes
)
However, it seems that I can only specify dynamic shapes for the Top-Level Module, but not for the nested Modules within it. such as:
class MatMul(nn.Module):
def __init__(self):
super().__init__()
def forward(self, a: torch.Tensor, b: torch.Tensor) -> torch.Tensor:
return a @ b
class Basic(nn.Module):
def __init__(self):
super().__init__()
self.MatMul = MatMul()
def forward(self, x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
out1 = self.MatMul(x, y) # 3x6x3
out2 = self.MatMul(out1, x) # 3x3x6
return out2
example_args = (torch.randn(3, 6), torch.randn(6, 3))
dim1_x = Dim("dim1_x", min=1, max=10)
dynamic_shapes = {"a": {0: dim1_x, 1: dim1_x}, "b": {0: dim1_x, 1: dim1_x}}
aten_dialect: ExportedProgram = export(
Basic(), example_args, dynamic_shapes=dynamic_shapes
)
A feasible approach is to compile and call each Module separately; for instance, compile the QKV-Proj Module/O-Proj Module with a Static Shape and the Attention Module with a Dynamic Shape. However, this method is quite cumbersome because it requires disassembling and compiling each Transformer Block within the Large Language Model (LLM) individually.
- So my first question is, how can I make the nested Modules support dynamic shapes?
After the model is compiled, ExecuTorch can dispatch different subgraphs to run on various hardware (as I mentioned, dispatch QKV/O Proj to the NPU and Attention to the CPU/GPU), which is very convenient. But how can I achieve the pipeline form I mentioned above? For example, once the QKV Proj computation for the first token is completed, the computation kernel for the QKV Proj of the second token can be launched.
- My second question is, can I call a compiled Module individually, rather than starting from the Top-Level Module? In this way, I can lock different Modules to achieve a pipeline.
The Dynamic KV Caches seems also unsolved? ![]() see Support for dynamic caches · Issue #4740 · pytorch/executorch · GitHub
see Support for dynamic caches · Issue #4740 · pytorch/executorch · GitHub