I am trying to understand why making a PseudoLinear layer that does not actually do matmul and instead performs element-wise multiplication by weight vector is not proportionally faster (e.g. on a 160-wide layer I expect ~10x speedup, but in practice it is negligible), and what can be done about it. Here’s my experiment:
The above code prints
100%|██████████| 400/400 [00:38<00:00, 10.48it/s]
real: 38.16433668136597s
100%|██████████| 400/400 [00:35<00:00, 11.29it/s]
fake: 35.41974401473999s
In theory, the speedup should be of order of 160x. Say matmul is 16x accelerated by tensor cores (IMHO, a generous assumption). Why am I not seeing 10x? The speedup becomes more noticeable as I widen layers to 1024, but still the asymptotic is quite off (should have been ~4x difference between the two; (10241024)/(256256)):
100%|██████████| 40/40 [01:05<00:00, 1.63s/it]
real: 65.22167682647705s
100%|██████████| 40/40 [00:21<00:00, 1.86it/s]
fake: 21.476550817489624s
I mean, theoretically, the speedup (or rather difference is speed, cause the substitute is nothing like Linear) should be exactly the size of the input width (N) less a small constant for bias. Matmul does NxN multiplications and this thing does only N both for forward and backward passes, which you can see for larger widths.
It is curious that even on larger sizes the speed difference is all over the place, but I guess this may have something to do with memory cache hierarchy.
You’re right, I assumed this is a small kernel issue and didn’t really think about it.
In your code:
You include random data generation inside the function you are timing
You execute x * self.weight + self.bias + x. I assume the trailing + x is a typo
nn.ReLU() is adding a constant factor to both variants. It’s best to remove it for benchmarking.
Notice that nn.Linear executes forward that is written entirely in C++/CUDA. In your PseudoLinear each operator is executed in CUDA, but multiplication and addition are executed as separate kernels, which makes for an overhead. You can use JIT to mitigate this issue a little. You won’t see any benefit from using JIT in case of nn.Linear based model though.
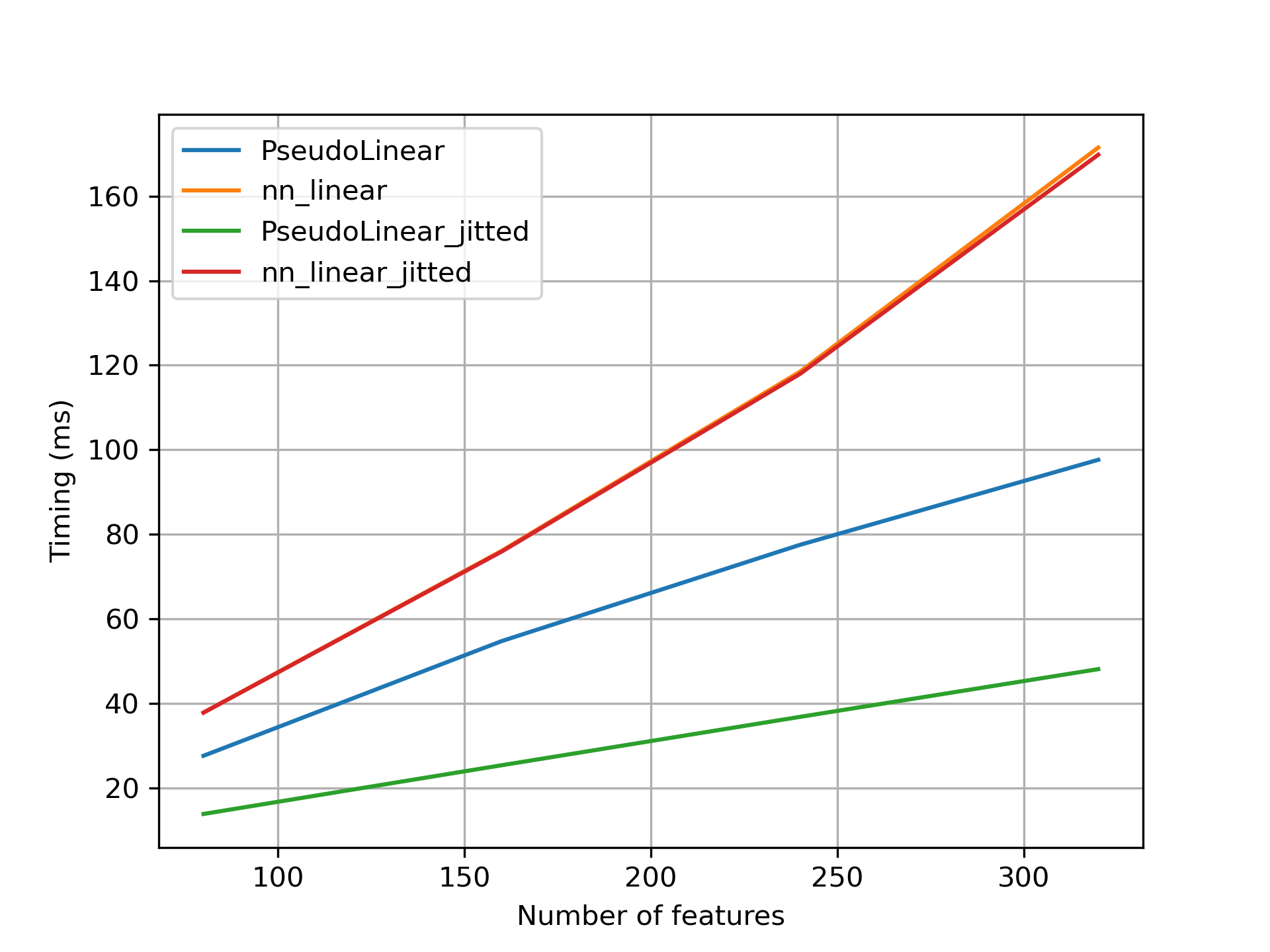
After fixing the above, I get the following performance scaling:
I used batch size of 32768 to fully utilize the GPU even for a small number of features.
Still not what we would expect looking at the number of operations. Another reason might be related to the highly optimized matrix multiplication algorithm. For mmul, there are algorithms that need less scalar multiplications than the naive algorithm. This makes Linear and PseudoLinear closer to each other in terms of the number of multiplications performed.