Hello,
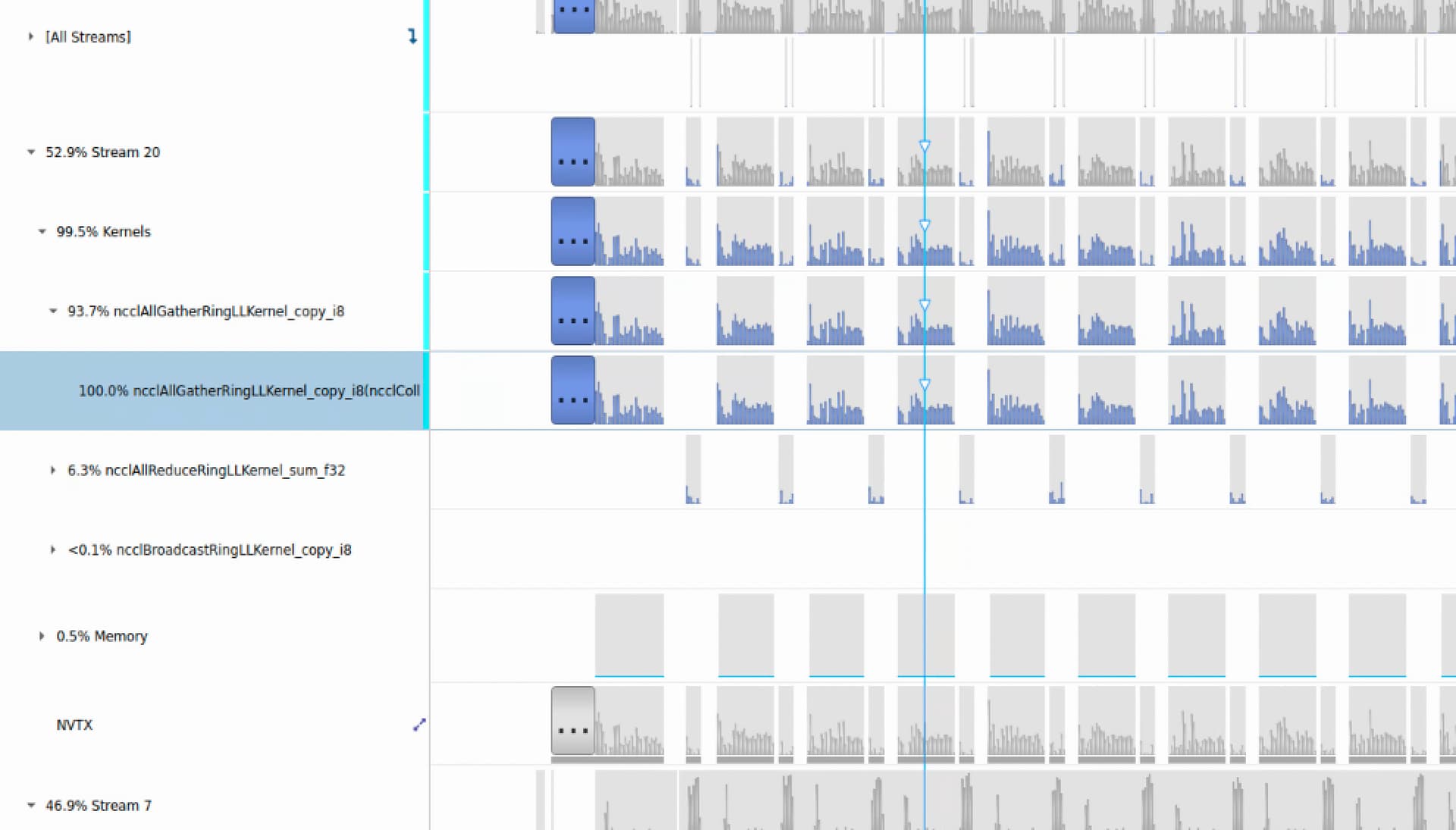
Because of GPU usage is not high in model training, I use DLProf to profile my model. The result shows that all_gather take a lot of time:
Through profiling result I found these all_gather are called by sycnbn(pytorch/torch/nn/modules/_functions.py at v1.8.2 · pytorch/pytorch · GitHub ).
I want to know why it took so much time and how to speed up the training.
By the way, because of the large number of model parameters, I set batch_size=1 and use 8 V100 in training.
ptrblck
December 10, 2021, 7:41am
2
I’m not familiar with your setup, but you could check how large each communication between the devices is and how much bandwidth your system allows (e.g. using NVLink could speed it up significantly etc.).
Thank you for your reply.
P2P Connectivity Matrix
D\D 0 1 2 3 4 5 6 7
0 1 1 1 1 0 0 0 1
1 1 1 1 1 0 0 1 0
2 1 1 1 1 0 1 0 0
3 1 1 1 1 1 0 0 0
4 0 0 0 1 1 1 1 1
5 0 0 1 0 1 1 1 1
6 0 1 0 0 1 1 1 1
7 1 0 0 0 1 1 1 1
Unidirectional P2P=Disabled Bandwidth Matrix (GB/s)
D\D 0 1 2 3 4 5 6 7
0 767.74 6.80 6.70 6.76 6.36 6.48 6.51 6.43
1 6.74 770.33 6.72 6.78 6.40 6.48 6.53 6.44
2 6.90 6.93 770.53 6.58 6.39 6.48 6.52 6.44
3 7.02 7.10 6.49 771.49 6.42 6.48 6.52 6.44
4 6.72 6.70 6.57 6.57 770.70 6.33 6.49 6.40
5 6.78 6.86 6.69 6.73 6.30 771.35 6.47 6.39
6 6.70 6.73 6.56 6.64 6.48 6.48 771.28 6.29
7 6.80 6.82 6.71 6.75 6.58 6.58 6.43 770.33
Unidirectional P2P=Enabled Bandwidth (P2P Writes) Matrix (GB/s)
D\D 0 1 2 3 4 5 6 7
0 769.29 48.48 48.49 24.25 6.71 6.66 6.76 24.26
1 48.48 771.21 24.25 48.49 6.72 6.68 24.25 6.68
2 48.48 24.26 770.81 24.25 6.72 48.48 6.74 6.69
3 24.25 48.48 24.25 771.18 48.49 6.66 6.74 6.69
4 6.86 6.89 6.70 48.48 770.87 24.25 48.48 24.25
5 6.84 6.85 48.49 6.75 24.25 771.44 24.25 48.49
6 6.86 24.25 6.75 6.79 48.48 24.25 771.74 48.48
7 24.25 6.90 6.75 6.79 24.25 48.48 48.48 771.11
Bidirectional P2P=Disabled Bandwidth Matrix (GB/s)
D\D 0 1 2 3 4 5 6 7
0 769.95 8.07 10.58 10.36 10.25 10.09 10.22 9.92
1 8.32 771.01 10.50 10.38 10.22 10.12 10.18 9.99
2 10.48 10.76 770.73 7.88 10.05 9.88 10.29 9.91
3 10.38 10.68 7.89 772.27 10.01 10.18 10.14 10.17
4 10.15 10.40 10.22 10.00 772.02 7.57 10.18 9.76
5 10.03 10.29 10.08 10.20 7.64 772.21 9.99 9.95
6 10.17 10.30 10.29 10.13 10.05 9.81 770.79 7.56
7 10.06 10.09 10.03 10.38 9.81 10.07 7.57 771.87
Bidirectional P2P=Enabled Bandwidth Matrix (GB/s)
D\D 0 1 2 3 4 5 6 7
0 770.84 96.91 96.91 48.49 10.37 10.10 10.35 48.49
1 96.86 771.08 48.49 96.92 10.52 10.29 48.49 10.05
2 96.85 48.49 769.93 48.50 10.16 96.91 10.32 10.05
3 48.49 96.91 48.49 769.68 96.90 10.18 10.11 10.40
4 10.30 10.50 10.14 96.92 771.43 48.49 96.85 48.49
5 9.97 10.16 96.91 10.18 48.49 771.37 48.49 96.91
6 10.32 48.49 10.25 10.05 96.85 48.48 771.73 96.91
7 48.50 9.99 9.92 10.30 48.48 96.91 96.86 771.20
By the way, torch 1.10 can speed up training, but communication overhead is still high.
ptrblck
December 13, 2021, 11:15pm
4
Thanks for the follow-up! Were you able to check the data size you would need to communicate and mapped it to the expected bandwidth?