A broad question: is there any documentation or info anywhere about the synchronization guarantees when passing CUDA tensors through multiprocessing queues?
As a concrete example, imagine code like the following:
def run_function(q):
while(True):
x = q.get()
# Use x, break on some condition, etc.
def main():
ctx = mp.get_context("spawn")
q = ctx.SimpleQueue()
proc = ctx.Process(
target=run_function,
args=(q, ),
daemon=True,
)
proc.start()
x = torch.randn(..., device="cuda")
W = torch.randn(..., device="cuda")
for _ in range(50):
x = torch.matmul(W, x)
q.put(x)
proc.join()
What are the guarantees about the state of x when the child process picks it up out of the queue in run_function? Naively, it looks like it could be anything, as the GPU could have run any number of loop iterations by the time the CPU puts x – and the memory allocator could have happily reused pointers / buffers during that time.
Empirically, though, nothing runs in the child process until the parent process finishes its work (on the GPU) – is this guaranteed? How?
And follow-ups:
Does anything change with multiple devices?
What if we don’t put x itself in the queue but rather a python class that contains (possibly nested) references to Tensor objects?
I don’t know for sure, but, I suspect q.put() is serializing tensor data and sending it to the remote process. If so, this is a CPU-side thing, and before it can be done the tensor data must be requested from the GPU. This would implicitly synchronize the GPU work to the CPU on the source process before allowing the q.put.
(The opposite possibility, is that tensor data remains on GPU and the remote pytorch process just references the existing gpu data, and I don’t think it’s set up that way.)
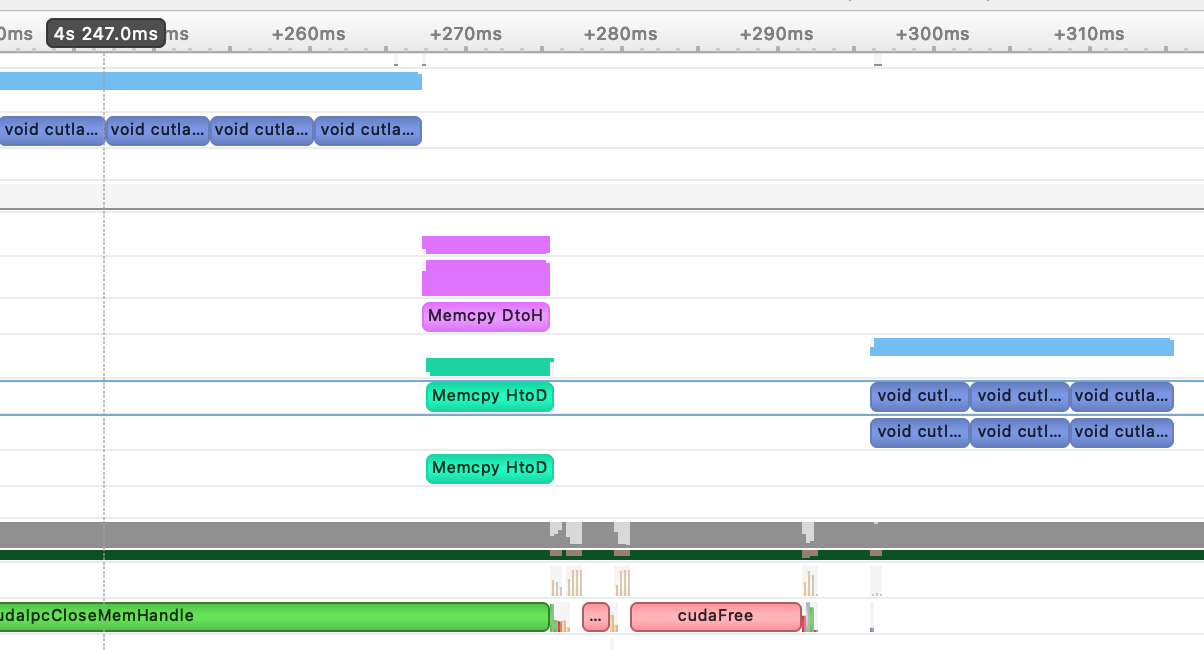
You can confirm by doing a profile trace using the torch autograd profiler, and observing a call to cuda d2h memcopy happening before the q.put finishes
It’s not at all clear to me how the parent process D2H can overlap with the child process H2D, but I agree that explains the apparent synchronization.
This is a little at odds with the description given at Multiprocessing best practices — PyTorch 2.1 documentation, which makes it sound like CUDA tensors are shared directly. I’ll poke at the CUDA API calls going on as well with IPC handles.
The “overlap” could indicate the wait time (thus sync) of the HtoD call, which is launched after the DtoH code. It does not necessarily mean operations are executed, but could still block.
So what I said before is partially true. The combined H2D and D2H appears to occur only when you need to move the tensor across two devices. (my_device in the child is different from the device of x_recv).
In the case of same-device, the tensor is transparently shared with the CUDA IPC mechanisms, but there appear to be some cudaStreamSynchronize()s that occur to guarantee some ordering. Still trying to make sense of the profiles.
# Testing indirection of tensors passed through a queue
class Box:
def __init__(self, x):
self.x = x
# Child process runs this
def run_fn(send_q, recv_q):
my_device = "cuda:0"
torch.cuda.set_device(my_device)
W1 = torch.randn(4096, 4096, device=my_device)
torch.cuda.synchronize()
send_q.put(0)
y_recv, box_recv = recv_q.get()
ret = torch.matmul(W1, box_recv.x) + y_recv
send_q.put(ret)
# Parent process
def main():
my_device = "cuda:0"
torch.cuda.set_device(my_device)
ctx = mp.get_context("spawn")
send_q = ctx.SimpleQueue()
recv_q = ctx.SimpleQueue()
proc = ctx.Process(
target=run_fn,
args=(recv_q, send_q),
daemon=True,
)
proc.start()
proc_ready = recv_q.get()
assert proc_ready == 0
W = torch.randn(4096, 4096, device=my_device)
X = torch.randn(4096, 4096, device=my_device)
y = torch.randn(4096, device=my_device)
torch.cuda.synchronize()
for _ in range(10):
X = torch.matmul(X, W)
box = Box(X)
send_q.put((y, box))
ret = recv_q.get()
print(ret.sum().item())
proc.join()
The resulting profile is kind of a mess, but it looks like the following occurs:
At the point where the parent put()s things into queue, it does a cudaEventRecord.
As soon as the child get()s things out of the queue, the first thing it does is to cudaStreamWaitEvent – presumably on the event created by the parent?
The child also does 2x cudaIpcOpenMemHandle to access the shared tensors
This all makes sense and explains the apparent synchronization between parent and child – there is an implicit stream synchronization and the enqueue / dequeue boundary.
Note that I cannot for the life of me find where the parent creates the IpcMemHandles, or how those handles get passed between processes. I’m just taking it on faith that it occurs somewhere.
I’m still not sure I have a robust mental model of sync guarantees for multiprocessing, but it does seem like things generally skew toward implicit safety.