I followed your suggestion, changed the transforms to an alternative name
Now I get a different error when I run this block
num_epochs = 10
for epoch in range(num_epochs):
# train for one epoch, printing every 10 iterations
train_one_epoch(model, optimizer, data_loader, device, epoch,print_freq=10)
# update the learning rate
lr_scheduler.step()
# evaluate on the test dataset
evaluate(model, data_loader_test, device=device)
os.mkdir("/content/drive/MyDrive/PytorchObjectDetector/fr_dataset/")
torch.save(model.state_dict(), "/content/drive/MyDrive/PytorchObjectDetector/fr_dataset/model")
Error I get
/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py:490: UserWarning: This DataLoader will create 4 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
cpuset_checked))
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-16-8e894f6729ee> in <module>()
2 for epoch in range(num_epochs):
3 # train for one epoch, printing every 10 iterations
----> 4 train_one_epoch(model, optimizer, data_loader, device, epoch,print_freq=10)
5 # update the learning rate
6 lr_scheduler.step()
5 frames
/usr/local/lib/python3.7/dist-packages/torch/_utils.py in reraise(self)
455 # instantiate since we don't know how to
456 raise RuntimeError(msg) from None
--> 457 raise exception
458
459
TypeError: Caught TypeError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/usr/local/lib/python3.7/dist-packages/torch/utils/data/_utils/worker.py", line 287, in _worker_loop
data = fetcher.fetch(index)
File "/usr/local/lib/python3.7/dist-packages/torch/utils/data/_utils/fetch.py", line 49, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/usr/local/lib/python3.7/dist-packages/torch/utils/data/_utils/fetch.py", line 49, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataset.py", line 471, in __getitem__
return self.dataset[self.indices[idx]]
File "<ipython-input-6-8432aadbd103>", line 28, in __getitem__
img, target = self.transforms(img, target)
TypeError: __call__() takes 2 positional arguments but 3 were given
This the block of code where the error is pointing to
class FrDataset(torch.utils.data.Dataset):
def __init__(self, root, data_file, transforms=None):
self.root = root
self.transforms = transforms
self.imgs = sorted(os.listdir(os.path.join(root, "images")))
self.path_to_data_file = data_file
def __getitem__(self, idx):
# load images and bounding boxes
img_path = os.path.join(self.root, "images", self.imgs[idx])
img = Image.open(img_path).convert("RGB")
box_list = parse_one_annot(self.path_to_data_file,
self.imgs[idx])
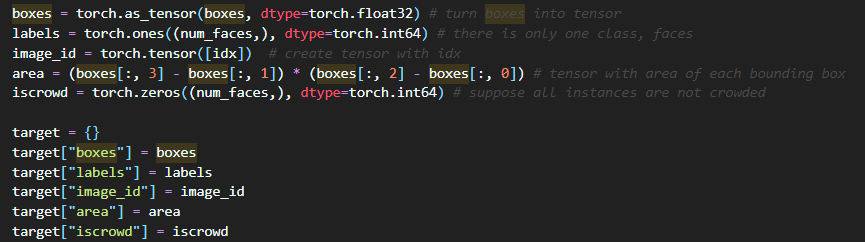
boxes = torch.as_tensor(box_list, dtype=torch.float32)
num_objs = len(box_list)
# there is only one class
labels = torch.ones((num_objs,), dtype=torch.int64)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:,0])
# suppose all instances are not crowd
iscrowd = torch.zeros((num_objs,), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.imgs)